方式一:
#只针对特征进行处理,不涉及标签
from sklearn.feature_selection import VarianceThreshold
selector = VarianceThreshold()
x_var = selector.fit_transform(x)
x_var.shape

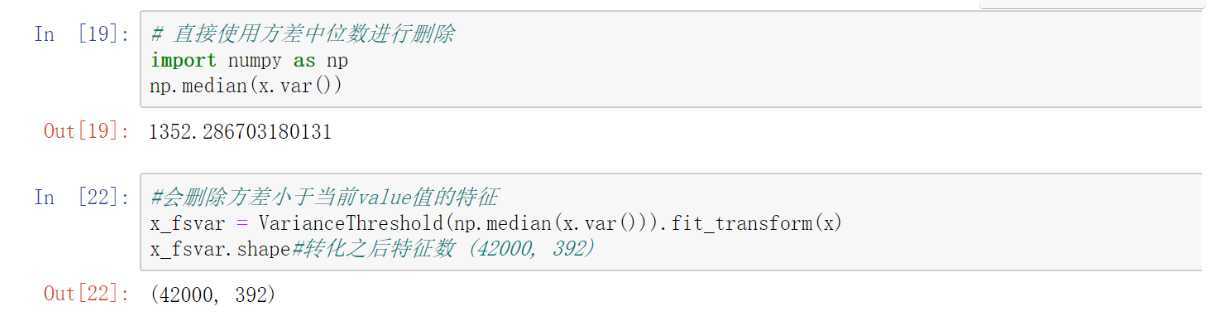
方式二:
直接使用方差中位数进行删除
import numpy as np
np.median(x.var())#查看方差中位数
x_fsvar = VarianceThreshold(np.median(x.var())).fit_transform(x)
x_fsvar.shape#查看特征
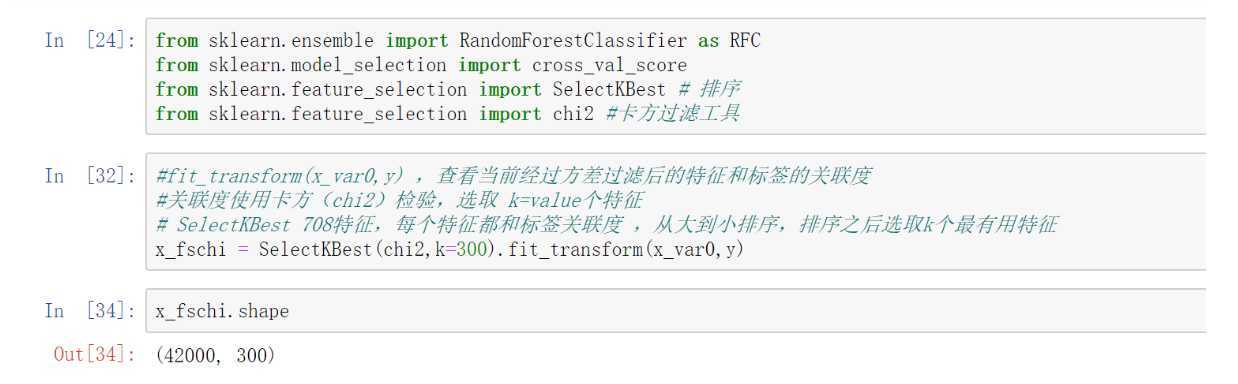
概述:查看方差过滤后特征与标签的关联度
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.model_selection import cross_val_score
from sklearn.feature_selection import SelectKBest#排序
from sklearn.feature_selection import chi2#卡方过滤工具
x_fschi = SelectKBest(chi2,k=300).fit_transform(x_var0,y)
x_fschi.shape
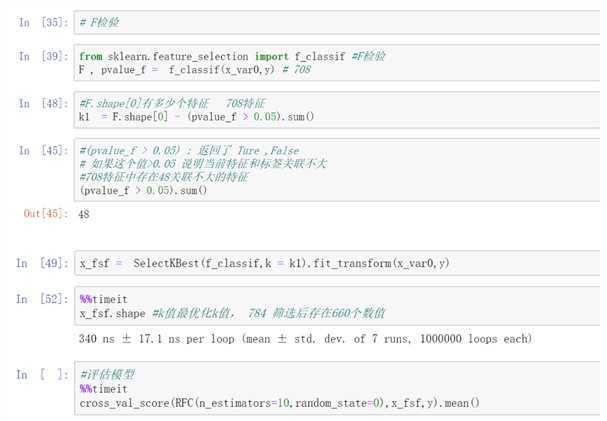
清除pvalue_f>0.05,特征与标签关联不大的特征,保留pvalue_f<0.05的特征
from sklearn.feature_selection import f_classif
F ,pvalue_f = f_class(x_var0,y)
原文:https://www.cnblogs.com/zhaoxiaoxian/p/13089848.html