文章是根据极客时间的MySQL45讲做的笔记
全局锁即给整个数据库加锁,MySQL提供了一个全局加读锁的命令Flush tables with read lock (FTWRL)。在语句执行下,整个数据库间处于只读状态,其他线程的update、更新类事务的提交语句、数据定义语句(如建表、修改表等)将被阻塞。另外命令set global readonly = true也可以使数据库变成只读状态。但不推荐,因为readonly的值会用来做其他逻辑,二在发生异常断开时,前者的锁会自动释放,后者不会。
另外对于支持事务的引擎,可以使用single-transaction 方法。
MySQL 里面表级别的锁有两种:一种是表锁,一种是元数据锁(meta data lock,MDL)。
表锁的语法是 lock tables … read/write。可以用 unlock tables 主动释放锁,也可以在客户端断开的时候自动释放。lock tables 语法除了会限制别的线程的读写外,也限定了本线程接下来的操作对象。线程 A 中执行 lock tables t1 read, t2 write;自己只能执行读 t1、读写 t2 的操作。
另一类表级的锁是 MDL(metadata lock)。MDL 不需要显式使用,在访问一个表的时候会被自动加上。当对一个表做增删改查操作的时候,加 MDL 读锁;当要对表做结构变更操作的时候,加 MDL 写锁。
读锁之间不互斥,因此你可以有多个线程同时对一张表增删改查。
读写锁之间、写锁之间是互斥的,用来保证变更表结构操作的安全性。因此,如果有两个线程要同时给一个表加字段,其中一个要等另一个执行完才能开始执行。
在 InnoDB 事务中,行锁是在需要的时候才加上的,但并不是不需要了就立刻释放,而是要等到事务结束时才释放。这个就是两阶段锁协议。
知道了这样的设定,我们设计事务执行顺序有指导意义。
假设一个顾客A在商店B买东西。顾客C也在商店B买东西。
对于顾客A的行为,我们创建一个事务流程如下:
1、update扣除A的钱x
2、update增加B的钱x
3、记录这条交易
我们可以发现对于顾客C的事务,它们都要对商店B的钱做update,根据两阶段协议,我们应该将顾客A的事务流程设置成1、3、2。这样B锁等待的时间就最短。
虽然这样设置可以提高效率,但是并不能避免死锁。
面对死锁,原生MySQL有两种解决策略:
1、进入等待,直到超时
2、发起死锁检测,发现死锁,回滚链条中的某个事务。将参数 innodb_deadlock_detect 设置为 on,表示开启这个逻辑。
但是在高并发的情况,这样的策略效率仍然低下。一般并发控制需要在服务端或者中间件甚至修改MySQL源码,对于同行的更新在进入引擎前进行排队,减少死锁检测的工作量。
另外,还有一种方法可以参考,基于上面例子将商店B的钱的存储行变成多行,钱是这些行的总和,这样就减少了单个行的锁冲突。
在可重复读隔离级别下,事务在启动的时候就“拍了个快照”。这个快照是基于整库的。这快照并不是复制库。
InnoDB 里面每个事务有一个唯一的事务 ID,叫作 transaction id。它是在事务开始的时候向 InnoDB 的事务系统申请的,是按申请顺序严格递增的。
每行数据也都是有多个版本的。每次事务更新数据的时候,都会生成一个新的数据版本,并且把 transaction id 赋值给这个数据版本的事务 ID,记为 row trx_id。数据表中的一行记录,其实可能有多个版本 (row),每个版本有自己的 row trx_id。
一个事务开启,开启前生产的数据版本有效,开启后的无效。这个视图数组和高水位,就组成了当前事务的一致性视图(read-view)。
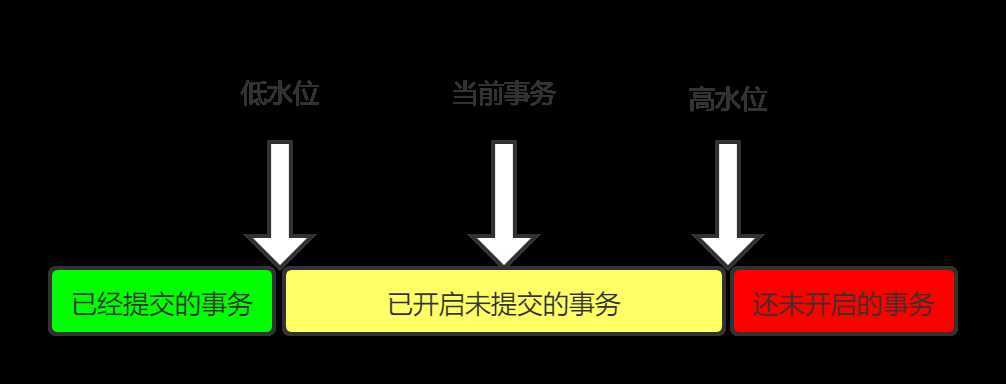
根据redo log和版本 row trx_id,InnoDB实现快速创建快照的能力。根据这个快照,InnoDB实现了可重复读的功能。
但需要注意的是,当事务在进行更新操作时,我们读的数据并不是源于该事务开启时的数据快照。而是进行当前读。这样就与前面的两阶段协议所说的一致了,当进行update操作时,是当前读,如果有其他事务更新了这条数据,还未提交,事务就进入锁等待。
小结InnoDB 的行数据有多个版本,每个数据版本有自己的 row trx_id,每个事务或者语句有自己的一致性视图。
普通查询语句是一致性读,一致性读会根据 row trx_id 和一致性视图确定数据版本的可见性。
对于可重复读,查询只承认在事务启动前就已经提交完成的数据;
对于读提交,查询只承认在语句启动前就已经提交完成的数据;
而当前读,总是读取已经提交完成的最新版本。
原文:https://www.cnblogs.com/DOTA-bing/p/13095076.html