在分类模型中,我们使用的神经网络模型其实跟回归模型中的差不多,但是这里我们输入的是两个数(数值对),输出也是两个数,分类0或者分类1的概率。在最终输出的时候我们使用了softmax函数对输出进行概率化表示,就是使得分类0和分类1的概率之和为1。
class Classification(nn.Module):
def __init__(self):
super(Classification, self).__init__()
self.linear1 = nn.Linear(2,10) # 输入是一个点对(x1,x2),所以我们输入的神经节点是两个
self.linear2 = nn.Linear(10,6, bias=True)
self.linear3 = nn.Linear(6,2) # 输出层由于是二分类,所以输出节点是2
def forward(self, x):
x = F.relu(self.linear1(x))
x = F.relu(self.linear2(x))
x = F.softmax(self.linear3(x))
return x
接下来来设定损失函数和优化器,跟前面回归模型唯一不一样的地方就在,这里的损失函数使用的是交叉熵损失函数。
if torch.cuda.is_available():
model = Classification().cuda()
else:
model = Classification()
loss_func = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr = LR)
下面就开始训练啦,训练过程跟回归模型几乎是一样的,但是有些参数设置(例如LR)有些区别,这个就是调参啦。
EPOCH = 3000
LR = 1
# BATCH_size = 50
for epoch in range(EPOCH):
if torch.cuda.is_available():
x = torch.autograd.Variable(x_train).cuda() # 这里没啥奇怪的,因为只导入了torch包,所以要用Variable要多写一点(from torch.autograd import Variable)
y = torch.autograd.Variable(y_train).cuda()
else:
x = torch.autograd.Variable(x_train)
y = torch.autograd.Variable(y_train)
out = model(x)
loss = loss_func(out,y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch+1)%100==0:
print(‘Epoch[{}/{}],loss:{:.6f}‘.format(epoch+1,EPOCH,loss.data.item()))
‘‘‘
训练的时候输出的结果:
Epoch[100/3000],loss:0.428639
Epoch[200/3000],loss:0.428163
Epoch[300/3000],loss:0.427694
Epoch[400/3000],loss:0.427230
Epoch[500/3000],loss:0.426771
Epoch[600/3000],loss:0.426316
Epoch[700/3000],loss:0.425866
Epoch[800/3000],loss:0.425419
Epoch[900/3000],loss:0.424979
Epoch[1000/3000],loss:0.424545
Epoch[1100/3000],loss:0.424115
Epoch[1200/3000],loss:0.423689
Epoch[1300/3000],loss:0.423266
Epoch[1400/3000],loss:0.422847
Epoch[1500/3000],loss:0.422434
Epoch[1600/3000],loss:0.422025
Epoch[1700/3000],loss:0.421618
Epoch[1800/3000],loss:0.421215
Epoch[1900/3000],loss:0.420815
Epoch[2000/3000],loss:0.420418
Epoch[2100/3000],loss:0.420026
Epoch[2200/3000],loss:0.419636
Epoch[2300/3000],loss:0.419249
Epoch[2400/3000],loss:0.418864
Epoch[2500/3000],loss:0.418482
Epoch[2600/3000],loss:0.418103
Epoch[2700/3000],loss:0.417728
Epoch[2800/3000],loss:0.417356
Epoch[2900/3000],loss:0.416986
Epoch[3000/3000],loss:0.416620
‘‘‘
最终,我们测试一下,我们训练的成果吧。
model.eval()
if torch.cuda.is_available():
x = x_test.cuda()
predict = model(x)
predict = torch.max(predict,1)[1]
predict = predict.cpu().data.numpy()
xx = x.cpu().data.numpy()
plt.figure(figsize=(8,8))
colors=[‘g‘,‘r‘]
for _x,_y,y,yy in zip(xx[:,0],xx[:,1], predict,y_test):
plt.scatter(_x,_y,marker=marker[int(y)],color=colors[y!=yy])
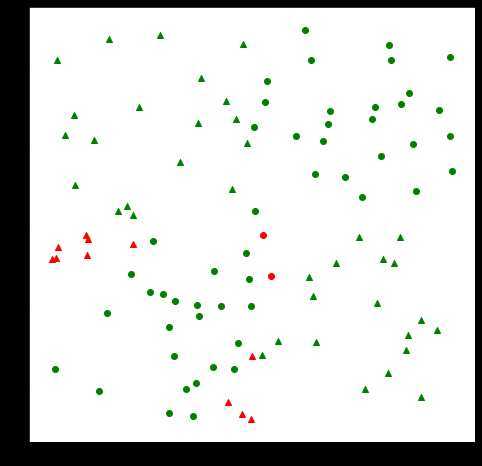
在上图中,可以看到,标记红色的点是预测错误的,也就是如果上面画的是三角△,他原来就应该是○。但是总体来说,我们也算是解决了分类问题。
另外,我们通常用准确率来量化在测试集上的结果,这里使用sklearn包里的accuracy函数来计算:
from sklearn.metrics import accuracy_score
model.eval()
if torch.cuda.is_available():
x = x_test.cuda()
predict = model(x)
predict = torch.max(predict,1)[1]
predict = predict.cpu().data.numpy()
accuracy_score(y_test.cpu().numpy(),predict)
‘‘‘
===output===
0.87
‘‘‘
分类的准确率是0.87,也就是说87%的数据都分类正确了,凑合吧,哈哈哈哈。
原文:https://www.cnblogs.com/datasnail/p/13097064.html