首先,Linux将内存空间分为了用户空间和内核空间,一个进程会同时持有两个栈:用户栈和内核栈
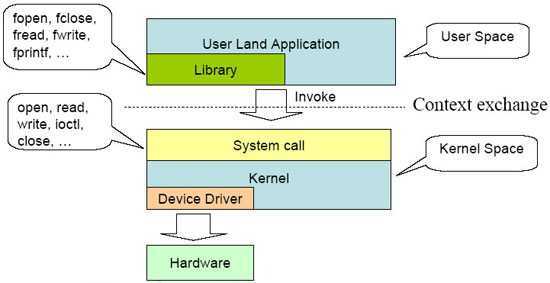
我们熟知的CPU上下文切换可以分为以下三种
① 进程上下文切换:是指从一个进程切换到另一个进程运行。由于一个进程既可以在用户空间运行,也可以在内核空间运行,因此进程的上下文不仅包括了虚拟内存、栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的状态。进程上下文切换需要保存上述资源,加载新进程(内核态)并装入新进程的上下文
(需要特别注意的是,发生系统调用或中断时,系统调用和中断的处理程序依然在当前进程的上下文中,使用当前进程的内核栈,这种情况并没有发生进程上下文切换)
② 中断上下文切换:首先要明确什么是中断上下文->硬件/软件通过中断触发信号,导致内核调用中断处理程序,进入内核空间。这个过程中,硬件的一些变量和参数也要传递给内核,内核通过这些参数进行中断处理。中断上下文可以看作就是硬件传递过来的这些参数和内核需要保存的一些其他环境。因此中断上下文的切换是一直发生在内核态的,相比进程上下文切换要轻量很多。
中断分硬件中断和软件中断,fork和execve系统调用都是利用陷阱(trap)这种软件中断方式主动从用户态进入内核态的
execve系统调用的作用是运行另外一个指定的程序。它会把新程序加载到当前进程的内存空间内,当前的进程会被丢弃,它的堆、栈和所有的段数据都会被新进程相应的部分代替,然后会从新程序的初始化代码和 main 函数开始运行。同时,进程的 ID 将保持不变。execve系统调用通常与 fork系统调用配合使用。从一个进程中启动另一个程序时,通常是先fork一个子进程,然后在子进程中使用 execve变为运行指定程序的进程。我们在shell中输入ls等命令时就触发了execve系统调用,调用关系如下
sys_execve() -> do_execve() -> do_execveat_common() -> do_execve_file -> exec_binprm() -> search_binary_handler() -> load_elf_binary() -> start_thread()
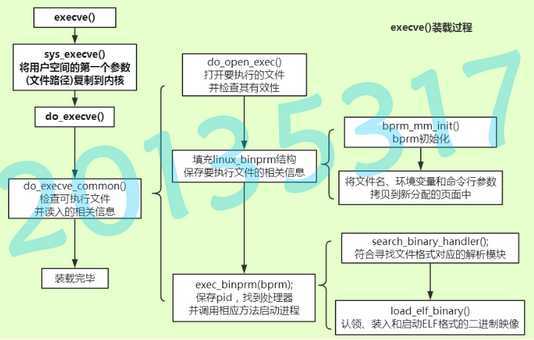
其中,上下文切换的特殊之处主要发生在调用exec_binprm后。search_binary_handler会寻找符合文件格式对应的解析模块,然后装入elf映像,之后要做的就是放弃以前从父进程继承来的资源。主要是对信号处理表,用户空间和文件3大资源的处理。
最终,调用start_thread()后,新程序的ip和sp存入堆栈,覆盖掉了之前的ip,sp,返回到子进程用户态后,就开始执行了装载的新代码
fork系统调用将创建一个与父进程几乎一样的新进程,之后继续执行下面的指令。程序可以根据 fork() 的返回值,确定当前处于父进程中,还是子进程中——在父进程中,返回值为新创建子进程的进程 ID,在子进程中,返回值是0。fork的执行流程如下图所示

fork系统调用实际上是通过do_fork()实现子进程的创建的,我们可以关注一下它的代码
long do_fork(unsigned long clone_flags, unsigned long stack_start, unsigned long stack_size, int __user *parent_tidptr, int __user *child_tidptr) { struct task_struct *p; int trace = 0; long nr; /* * Determine whether and which event to report to ptracer. When * called from kernel_thread or CLONE_UNTRACED is explicitly * requested, no event is reported; otherwise, report if the event * for the type of forking is enabled. */ if (!(clone_flags & CLONE_UNTRACED)) { if (clone_flags & CLONE_VFORK) trace = PTRACE_EVENT_VFORK; else if ((clone_flags & CSIGNAL) != SIGCHLD) trace = PTRACE_EVENT_CLONE; else trace = PTRACE_EVENT_FORK; if (likely(!ptrace_event_enabled(current, trace))) trace = 0; } p = copy_process(clone_flags, stack_start, stack_size, child_tidptr, NULL, trace); /* * Do this prior waking up the new thread - the thread pointer * might get invalid after that point, if the thread exits quickly. */ if (!IS_ERR(p)) { struct completion vfork; struct pid *pid; trace_sched_process_fork(current, p); pid = get_task_pid(p, PIDTYPE_PID); nr = pid_vnr(pid); if (clone_flags & CLONE_PARENT_SETTID) put_user(nr, parent_tidptr); if (clone_flags & CLONE_VFORK) { p->vfork_done = &vfork; init_completion(&vfork); get_task_struct(p); } wake_up_new_task(p); /* forking complete and child started to run, tell ptracer */ if (unlikely(trace)) ptrace_event_pid(trace, pid); if (clone_flags & CLONE_VFORK) { if (!wait_for_vfork_done(p, &vfork)) ptrace_event_pid(PTRACE_EVENT_VFORK_DONE, pid); } put_pid(pid); } else { nr = PTR_ERR(p); } return nr; }
能够看到一个很显眼的调用:p = copy_process(clone_flags, stack_start, stack_size,child_tidptr, NULL, trace); 前面已经说过,子进程是通过复制父进程创建的,copy_process()就承担了这个职责,它的执行流程如下:
struct pt_regs { long ebx; long ecx; long edx; long esi; long edi; long ebp; long eax; int xds; int xes; int xfs; int xgs; long orig_eax; long eip; int xcs; long eflags; long esp; int xss; };
通过软件中断0x80,系统会跳转到一个预设的内核空间地址,它指向了系统调用处理程序(不要和系统调用服务例程相混淆),即在arch/i386/kernel/entry.S文件中使用汇编语言编写的system_call函数。很显然,所有的系统调用都会同一跳转到这个地址进而执行system_call函数
软中断指令int 0x80执行时,系统调用号会被放进eax寄存器,同时,sys_call_table每一项占用4个字节。这样,system_call函数可以读取eax寄存器获得当前系统调用的系统调用号,将其乘以4天生偏移地址,然后以sys_call_table为基址,基址加上偏移地址所指向的内容即是应该执行的系统调用服务例程的地址。
另外,除了传递系统调用号到eax寄存器,假如需要,还会传递一些参数到内核,比如write系统调用的服务例程原型为: 调用write系统调用时就需要传递文件描述符fd、要写进的内容buf以及写进字节数count等几个内容到内核。ebx、ecx、edx、esi以及edi寄存器可以用于传递这些额外的参数。
正如之前所述,系统调用服务例程定义中的asmlinkage标记表示,编译器仅从堆栈中获取该函数的参数,而不需要从寄存器中获得任何参数。进进system_call函数前,用户应用将参数存放到对应寄存器中,system_call函数执行时会首先将这些寄存器压进堆栈。对于系统调用服务例程,可以直接从system_call函数压进的堆栈中获得参数,对参数的修改也可以一直在堆栈中进行。在system_call函数退出后,用户应用可以直接从寄存器中获得被修改过的参数。
系统调用通过软中断0x80陷进内核,跳转到系统调用处理程序system_call函数,并执行相应的服务例程,但由于是代表用户进程,所以这个执行过程并不属于中断上下文,而是处于进程上下文
结合中断上下文切换和进程上下文切换分析Linux内核一般执行过程
原文:https://www.cnblogs.com/cccc2019fzs/p/13110431.html