这是uber-plato 的研究成果,发表时间:2019-7-11
https://github.com/uber-research/plato-research-dialogue-system
https://arxiv.org/pdf/1907.05507.pdf
http://www.paperweekly.site/papers/3801
Papangelis, A., Wang, Y.-C., Molino, P., & Tur, G. (2019). Collaborative Multi-Agent Dialogue Model Training Via Reinforcement Learning. SIGDIAL, 92–102. https://doi.org/10.18653/v1/w19-5912
论文阐述了对话代理仅通过自我生成语言进行交流的第一次完整的尝试。
使用DSTC2作为种子数据,为每个代理训练了NLU和NLG网络,使得代理之间能够在线交互。
将代理之间的交互行为看做是随机合作游戏,每个代理(玩家)都有一个角色(助理、导游、食客等),它们只能通过自己生成的语言和顾客进行交互。因此,每个代理都需要学习如何在具有多种不确定性来源的环境中合理运作(它自己的NLU和NLG,其他代理的NLU, Policy, 和 NLG)。我们的实验结果证实,随机游戏代理比有监督的深度学习方法表现优秀。
在DSTC2数据集上,Cambridge restaurants领域实现多对话代理。
整体的模型由1个卷积层encoder和2个decoder(一个意图多标签分类器、一个槽位标记器)组成,以多任务的方式进行端到端训练,同时优化多标签意图分类和插槽标记任务。
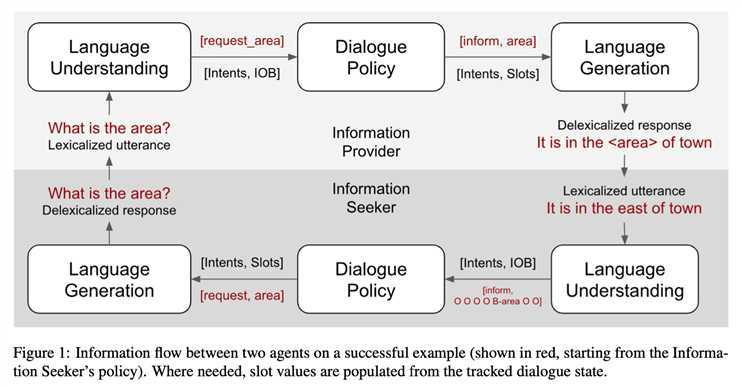
论文训练了2个代理:一个是寻找餐馆信息的seeker,另一个是提供信息的provider。
seeker将自己的目标和provider提供的信息建模;而提供者的状态模型则表达了搜索者所要求的约束或信息,以及当前关注项的属性(从数据库中检索)和与当前数据库结果相关的度量,例如检索项的数量、槽值熵等。
每个代理的奖励信号是不同的。
每个代理的对话策略都接收对话状态跟踪的结果,输出对话行为。候选的对话行为也是相同的。每个代理也有不同的对话状态,表示对世界的认知。
论文研究policy环节的强化学习多代理问题。
文中实现了seg2seg的lstm模型,并加入了attention机制。
代码见https://github.com/uber- research/ plato-research-dialogue-system
原文:https://www.cnblogs.com/xuehuiping/p/13092811.html