
哈希表(Hash table),也叫散列表,是根据关键码值(Key value)而直接进行访问的数据结构。
它通过把关键码值映射到表中一个位置(即它的下标index)来访问记录,以加快查找的速度。 这个映射函数叫作散列函数(Hash Function)或哈希函数,存放记录的数组叫作哈希表(或散列表)。
班级里30个人名字(英文),要把他们放到一张表里,怎么把不同的人放到不同的位置,又便于查找到不同的人呢?
放在数组就不合适了,只能依次的去找, 线性的查找, 每次查找都是O(n);知道jack这个名字可以一次性的查找到他所在的位置, O(1), 即哈希函数;
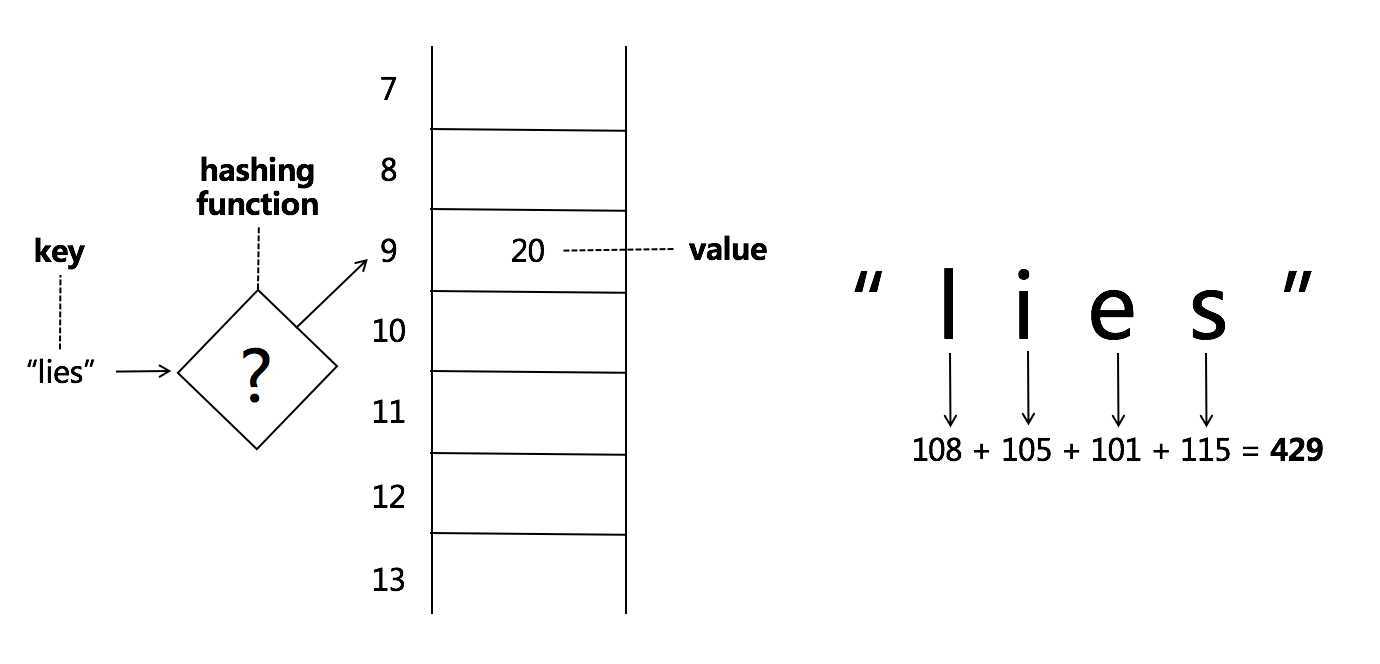
比如lies这个名字,找到对应的hash函数,对应一个数字(0-29的下标),比如9,不同的英文字符对应不同的下标;
比如选取每个字母的accii码, 最后加一起得到一个和,和 % 30得到一个下标;
哈希函数选取的好就会让这些数值尽量分散,而不会发生所谓的碰撞
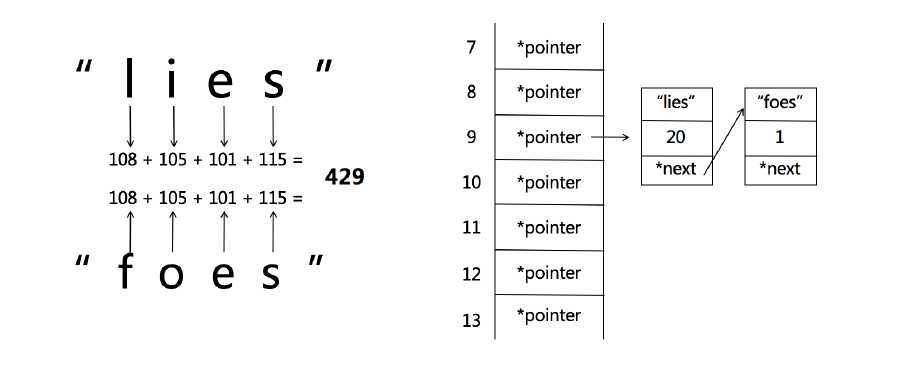
两个key用同样的hash函数最后取模得到的结果下标一样既Hash Collisions(即两个字符串key哈希后得到相同的下标。)
只要有hash函数,99%都会有重复的值既碰撞, 而且把大于30的放在30之内的范围内肯定会有碰撞;
lines和foes 最后得到的下标都是9, 在9的位置上建立一个链表, 所有的元素都存在这个链表中(这种方式叫拉链法来解决碰撞)
明白哈希表的实现原理,知道哈希函数和哈希碰撞;
实际中哈希表、HashMap、HashSet、 Hashtable等,在语言原生都是已经实现好了的;
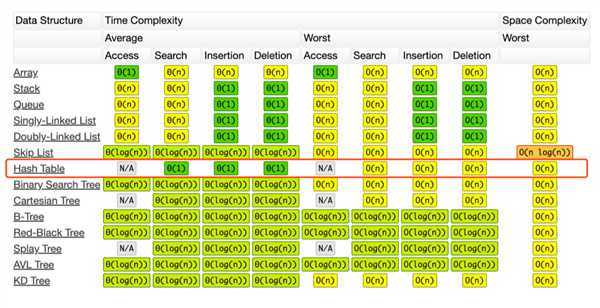
如果碰撞的越来越多,链表会越来越长,它的查询时间复杂度就变成了O(n),哈希表设计的好会避免很多哈希碰撞,我们可以认为它的查询时间复杂度是O(1)。
哈希表的时间空间复杂度: 查询、 添加、 删除都是 O(1) ,最坏情况是哈希函数选的不好或者它的整个size太小了就会导致经常发生冲突,一冲突就变成链表了,很多时候它的复杂度就退化成 O(n)了。
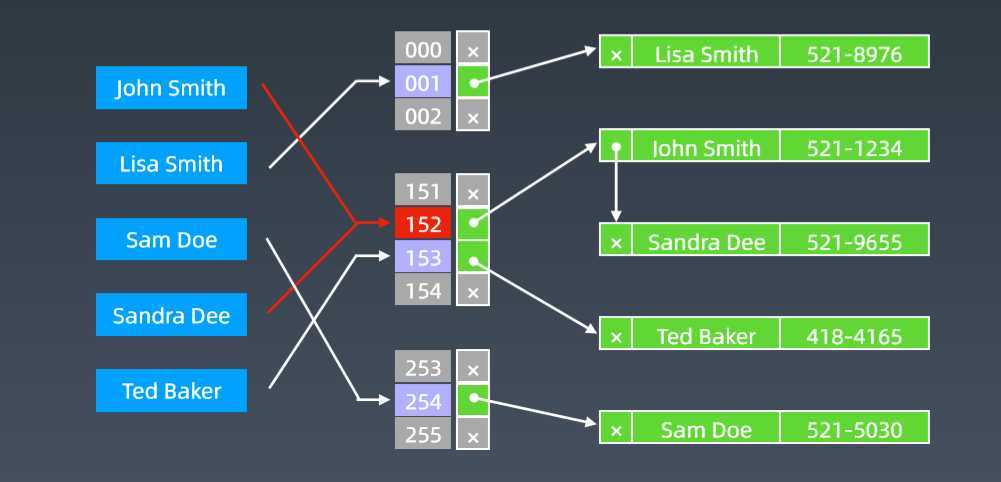
在工程中就不再用哈希表了,经常抽象出来使用。比如Java中Map和Set
电话号码簿、 用户信息表、 缓存(LRU Cache)、 键值对存储(Redis)
在Java - Code:
Map:key-value对,key不重复,值value可以重复;
Set:不重复元素的集合,没有键值对,而是一个单个的元素,单个元素是不重复的。
在python中 dict或者json,set在python中就是set。
Java Map文档 HashMap、 Hashtable、 ConcurrentHashMap
Java Set文档 TreeSet、 HashSet、 ConcurrentSkipListSet、 CopyOnWriteArraySet、 EnumSet、 JobStateReasons、 LinkedHashSet
List和Map是抽象性和解释性;
list_x = [1,2,3,4] 它的实现可以是数组也可以是链表,关键是它是可以重复的;
插入是O(1)的时间复杂度,查找是O(n);
map_x = {
‘jack‘:100,
‘张三‘:80,
‘kris‘:90,
...
}
map是一种映射;
Set抽象接口,它背后的实现类千差万别
set_x = {‘jack‘,‘kris‘,‘andy‘}
set_y = set([‘jack‘,‘kris‘,‘jack‘])
集合,跟map比较相似,可把它看做map的key;集合不能有重复,可看做去重后的list
集合的实现背后有两种: 哈希表或者树 二叉树的形式来实现;
查找是O(1)时间复杂度或者Logn, 它比List的效率要高;
HashMap vs TreeMap
HashSet vs TreeSet
hashtable vs binary-search
以上三种跟List、Map和Set能够达到的目的是一样的, 只不过里边的元素排列和存储的方式不同;
HashMap/HashSet/hashtable用的是hash表来存储, 查询时时间复杂度是O(1), 是乱序的;
TreeMap/TreeSet/binary-search用的是二叉树来存储, 时间复杂度是Log(n), 都是排好序的(有序); TreeMap、 TreeSet等都是用二叉搜索树即红黑树来实现,严格平衡的红黑树。
HashSet的实现
public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, java.io.Serializable
public HashSet() {
map = new HashMap<>(); //HashSet它的背后就是建了一个HashMap,
}
public boolean add(E e) {
return map.put(e, PRESENT)==null; //add方法就是把这个元素放到它的key的位置上去,它的value叫 PRESENT,//private static final Object PRESENT = new Object();// Dummy value to associate with an Object in the backing Map
//present就是它新建了一个叫dummy value,随便用了一个object作为占位使用,表示我在场。
}
public boolean remove(Object o) { return map.remove(o)==PRESENT; } //remove也是从hashmap中移除。
HashSet它背后就是嫁接在HashMap上。HashSet每次都存一个present,岂不是浪费内存空间。
HashMap的实现
它的node分为 HashNode和TreeNode这两种。
put、 putVal
get
原文:https://www.cnblogs.com/shengyang17/p/13124919.html