分类代码点这里
‘‘‘
datatime:2020/6/14
author:wuxiong
description:鸢尾花数据集分类
‘‘‘
import numpy
from sklearn.datasets import load_iris
#读出鸢尾花数据集data
data=load_iris()
print(data.keys())
鸢尾花数据集一共150条
一共有三类分别用0,1,2表示,分别是[‘setosa‘ ‘versicolor‘ ‘virginica‘]
四个特征
[‘sepal length (cm)‘, ‘sepal width (cm)‘, ‘petal length (cm)‘, ‘petal width (cm)‘]
每种种类的鸢尾花有50个数据
详细的数据集分析点击,这里
‘‘‘
datatime:2020/6/14
author:wuxiong
description:鸢尾花数据集分类
‘‘‘
import numpy
from sklearn.datasets import load_iris
#读出鸢尾花数据集data
data=load_iris()
print(data.keys())
#鸢尾花数据集包含的内容
# print(data[‘data‘])
#打乱顺序
from sklearn.utils import shuffle
data_shuffle_train,data_shuffle_target = shuffle(data[‘data‘],data[‘target‘])
#分割成数据集和测试集,80%用于训练,20%用于测试
from sklearn.model_selection import StratifiedShuffleSplit
train_index, test_index = next(iter(
StratifiedShuffleSplit(n_splits=1, test_size=0.2,
random_state=1).split(data_shuffle_train,data_shuffle_target)))
x_data_train = data_shuffle_train[train_index]
y_data_train = data_shuffle_target[train_index]
x_data_test = data_shuffle_train[test_index]
y_data_test = data_shuffle_target[test_index]
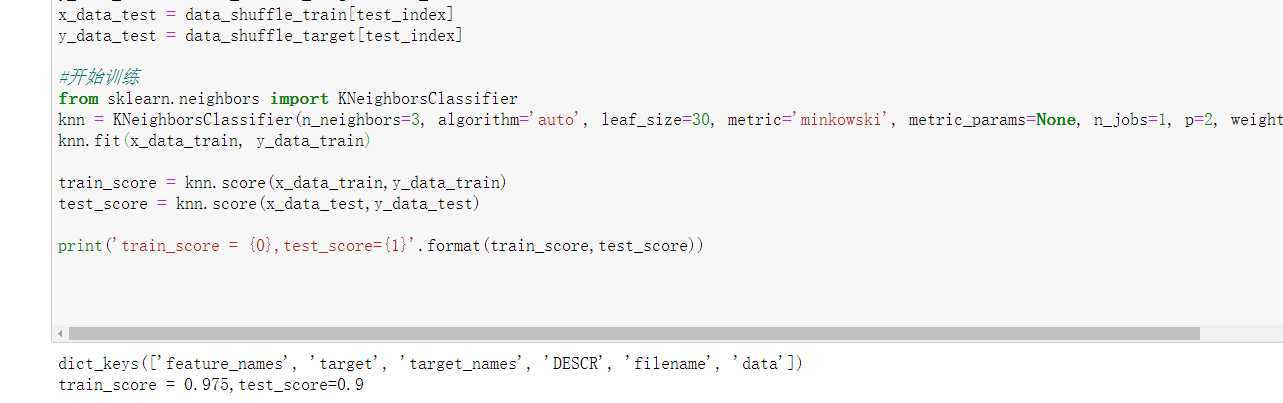
#开始训练
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=3, algorithm=‘auto‘, leaf_size=30, metric=‘minkowski‘, metric_params=None, n_jobs=1, p=2, weights=‘uniform‘)
knn.fit(x_data_train, y_data_train)
train_score = knn.score(x_data_train,y_data_train)
test_score = knn.score(x_data_test,y_data_test)
print(‘train_score = {0},test_score={1}‘.format(train_score,test_score))
训练集的模式差不多能到0.975,测试集0.96
原文:https://www.cnblogs.com/realwuxiong/p/13126954.html