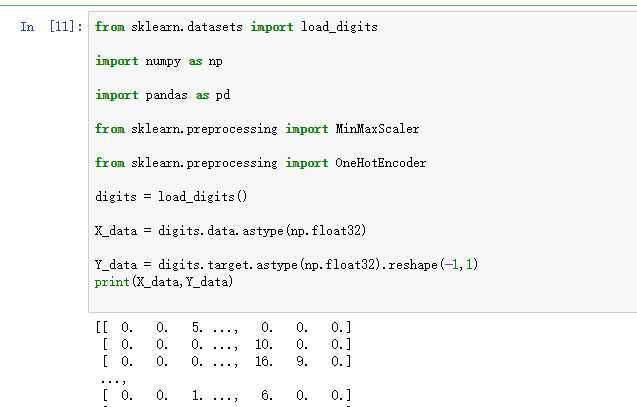
1.手写数字数据集
- from sklearn.datasets import load_digits
- digits = load_digits()
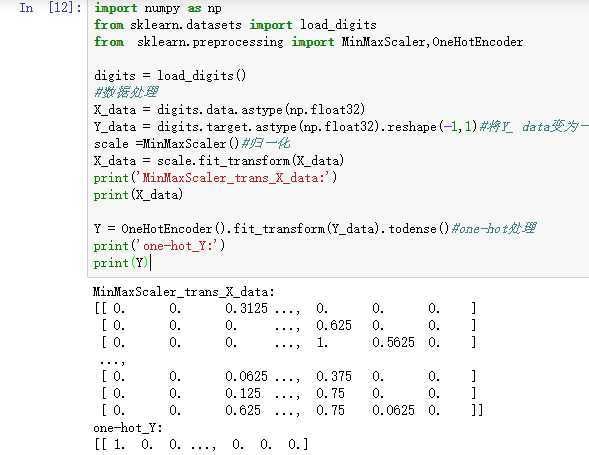
2.图片数据预处理
- x:归一化MinMaxScaler()
- y:独热编码OneHotEncoder()或to_categorical
- 训练集测试集划分
- 张量结构
3.设计卷积神经网络结构
4.模型训练
- model.compile(loss=‘categorical_crossentropy‘, optimizer=‘adam‘, metrics=[‘accuracy‘])
- train_history = model.fit(x=X_train,y=y_train,validation_split=0.2, batch_size=300,epochs=10,verbose=2)
5.模型评价
- model.evaluate()
- 交叉表与交叉矩阵
- pandas.crosstab
- seaborn.heatmap
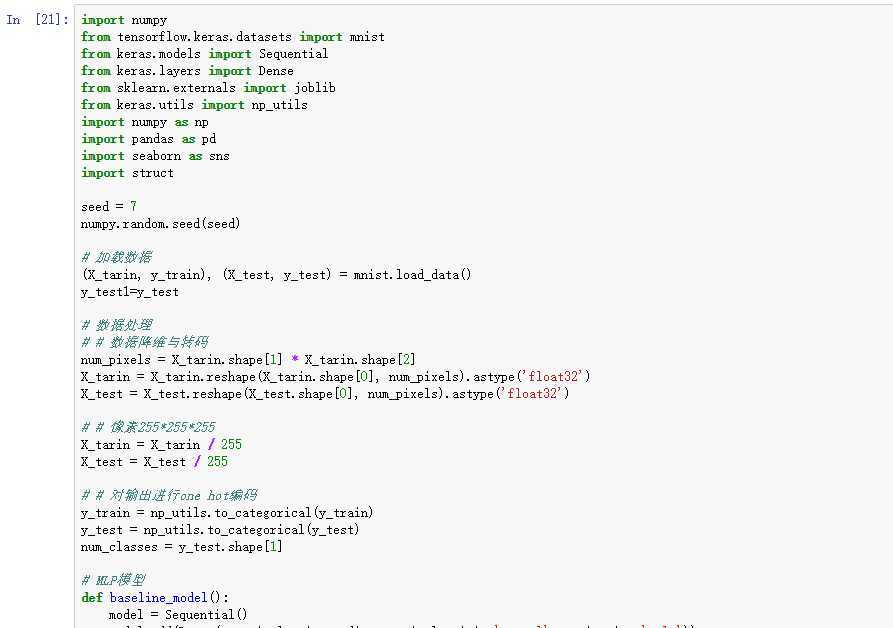
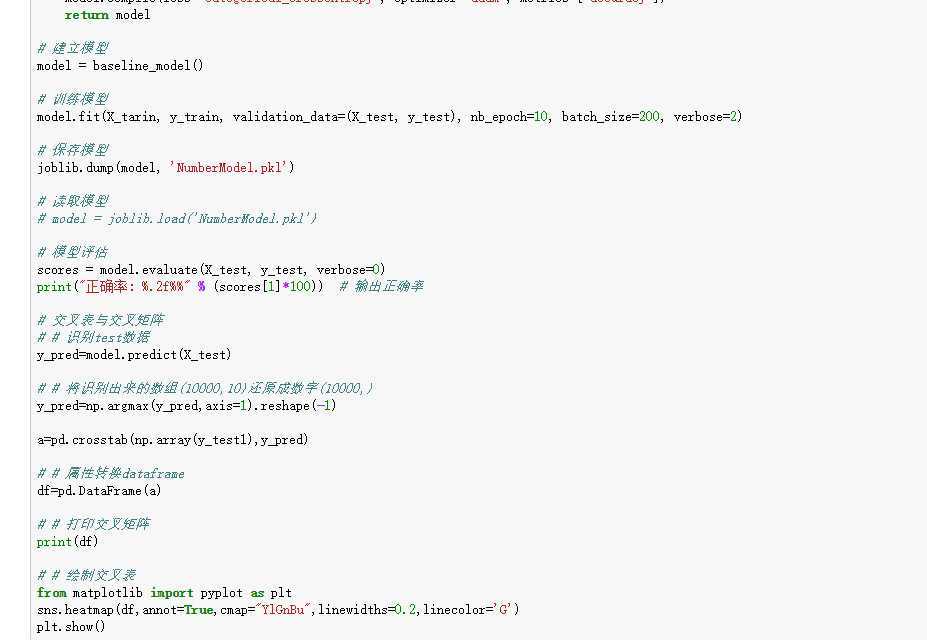
手写数据识别
原文:https://www.cnblogs.com/wujiabin/p/13127076.html