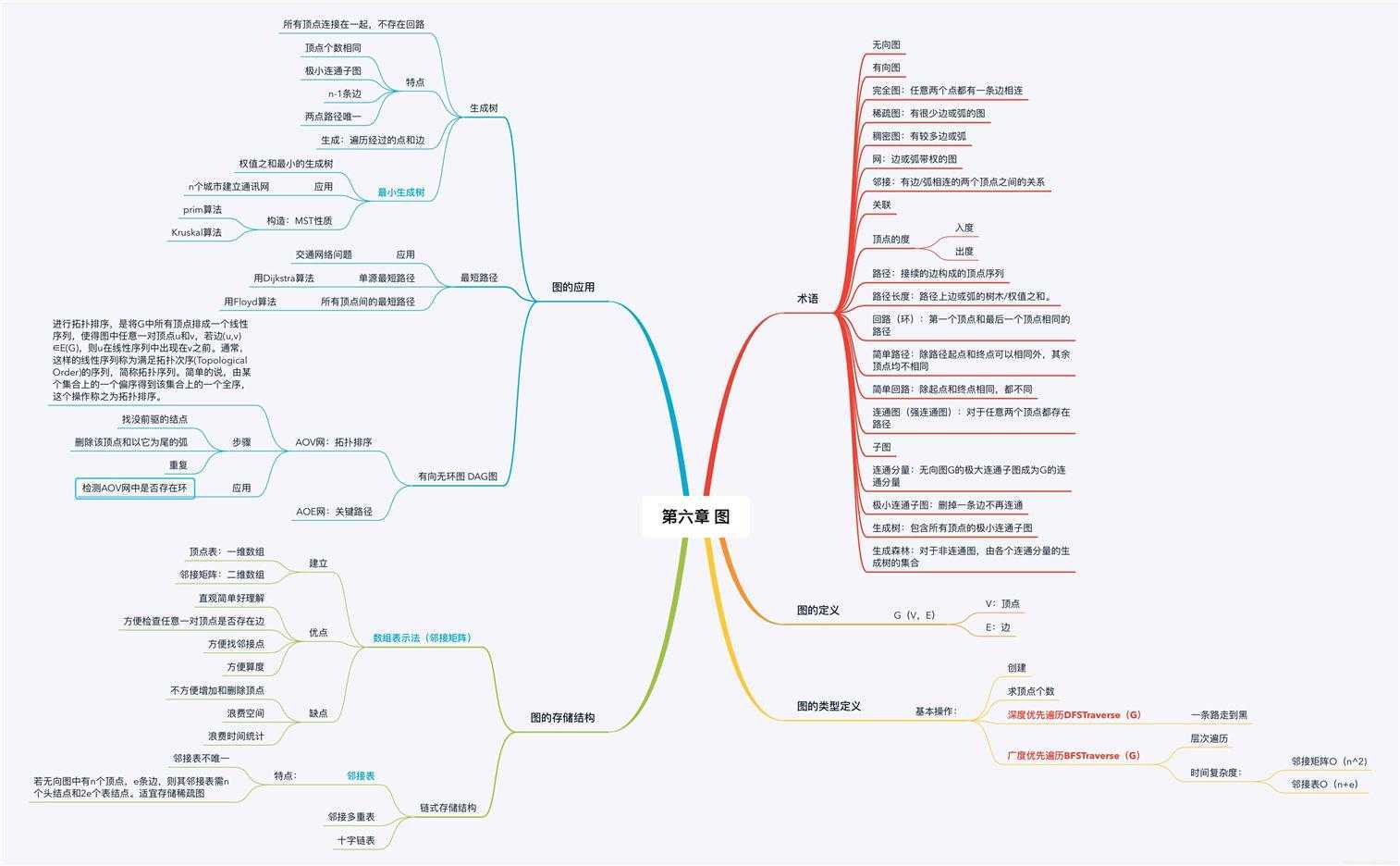
深度优先遍历 (使用栈)
(1)首先访问顶点i,并将其访问标记置为访问过,即visited[i]=1;
(2)然后搜索与顶点i有边相连的下一个顶点j,若j未被访问过,则访问他,并将j的访问标记置为访问过,visited[j]=1,然后从j开始重复这一过程,
若j已访问,再看与i有边相连的其他节点。
(3)若与i有边相连的顶点都被访问过,则退回到前一个访问节点重复刚才的过程,直到图中所有顶点都被访问完为止。
广度优先遍历 (使用队列)
(1)开始时要将其置空
(2)每访问一个顶点,将其入队
(3)在访问一个顶点的所有后继时,要将其出队
(4)若队列为空时,说明每一个访问过的顶点的所有后继均已被访问,因而本次遍历可以结束。若此时还有未访问的顶点,需另选进行遍历。
实践
刚开始时想到dfs,但是又纠结于怎么表示鳄鱼、圆岛的距离。然后没有考虑到一步上岸的问题。
原文:https://www.cnblogs.com/bkyhyf/p/13127164.html