包含user.id用户ID gender性别 occupation职业 ZIP code邮编等属性,每个属性之间用|分割
u.item电影元数据
包含movie.id电影ID title电影标题 release date电影上映日期 IMDB link 电影分类向量等属性,每个属性之间用|分割
u.data用户对电影的评级
包含user.id用户ID movie.id电影ID rating评分(从1-5) timestamp时间戳等属性,每个属性之间用制表符\t分割
下载文件名称 :ml-100k

from pyspark import SparkContext from pyspark.sql import SQLContext,SparkSession
from pyspark.sql.types import *
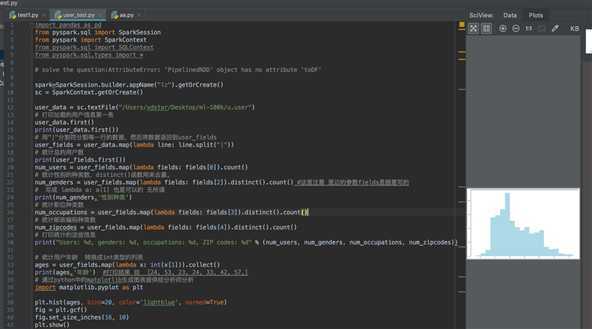
# solve the question:AttributeError: ‘PipelinedRDD‘ object has no attribute ‘toDF‘ spark=SparkSession.builder.appName("lz").getOrCreate() sc = SparkContext.getOrCreate() user_data = sc.textFile("/Users/xdstar/Desktop/ml-100k/u.user") # 打印加载的用户信息第一条 user_data.first() print(user_data.first()) # 用"|"分割符分割每一行的数据,然后将数据返回到user_fields user_fields = user_data.map(lambda line: line.split("|")) # 统计总的用户数 print(user_fields.first()) num_users = user_fields.map(lambda fields: fields[0]).count() # 统计性别的种类数,distinct()函数用来去重。 num_genders = user_fields.map(lambda fields: fields[2]).distinct().count() #这里注意 里边的参数fields是随意写的 # 写成 lambda a: a[1] 也是可以的 无所谓 print(num_genders,‘性别种类‘) # 统计职位种类数 num_occupations = user_fields.map(lambda fields: fields[3]).distinct().count() # 统计邮政编码种类数 num_zipcodes = user_fields.map(lambda fields: fields[4]).distinct().count() # 打印统计的这些信息 print("Users: %d, genders: %d, occupations: %d, ZIP codes: %d" % (num_users, num_genders, num_occupations, num_zipcodes)) # 统计用户年龄 转换成int类型的列表 ages = user_fields.map(lambda x: int(x[1])).collect() print(ages,‘年龄‘) #打印结果 如 [24, 53, 23, 24, 33, 42, 57,] # 通过python中的matplotlib生成图表提供给分析师分析 import matplotlib.pyplot as plt plt.hist(ages, bins=20, color=‘lightblue‘, normed=True) fig = plt.gcf() fig.set_size_inches(16, 10) plt.show()
处理二简介:
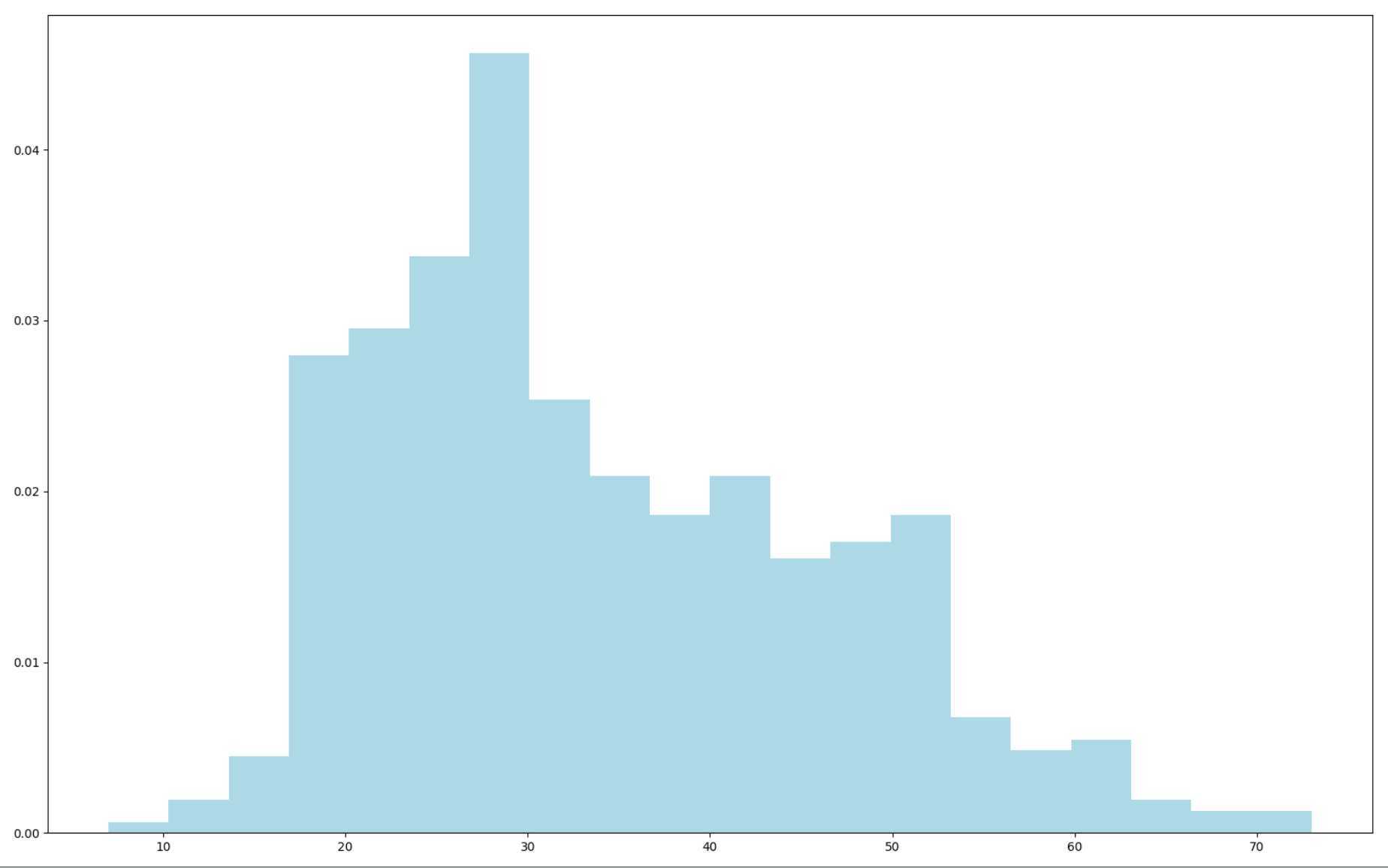
首先对用户数据处理,获得用户信息中的职位种类以及每种职位用户个数。然后对职位进行统计并使用Python中的图形框架Matplotlib生成柱状图,最后通过柱状图分析观看电影的观众职位以及人数分布趋势。
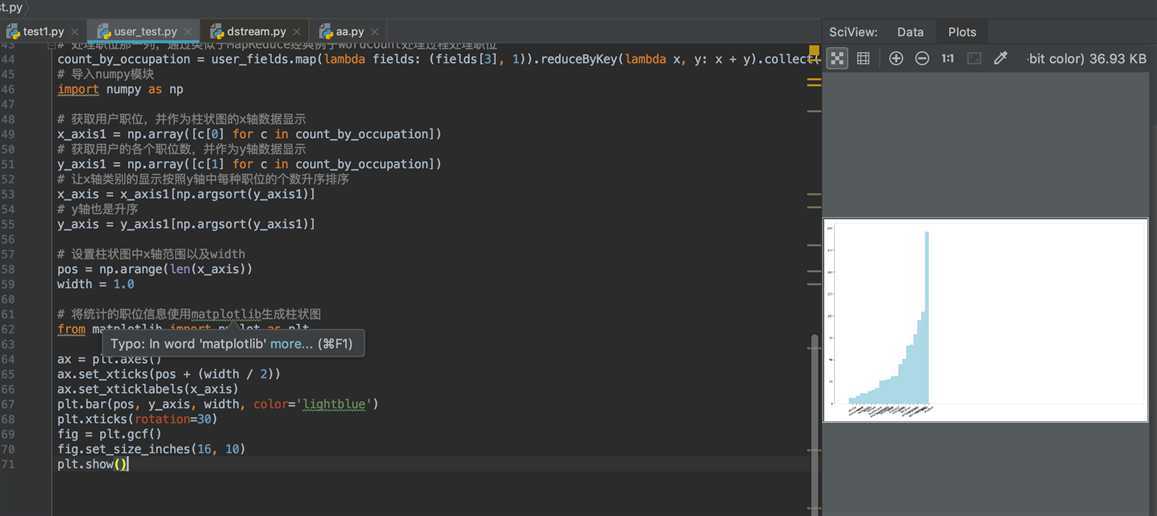
# 处理职位那一列,通过类似于MapReduce经典例子WordCount处理过程处理职位 count_by_occupation = user_fields.map(lambda fields: (fields[3], 1)).reduceByKey(lambda x, y: x + y).collect() # 导入numpy模块 import numpy as np # 获取用户职位,并作为柱状图的x轴数据显示 x_axis1 = np.array([c[0] for c in count_by_occupation]) # 获取用户的各个职位数,并作为y轴数据显示 y_axis1 = np.array([c[1] for c in count_by_occupation]) # 让x轴类别的显示按照y轴中每种职位的个数升序排序 x_axis = x_axis1[np.argsort(y_axis1)] # y轴也是升序 y_axis = y_axis1[np.argsort(y_axis1)] # 设置柱状图中x轴范围以及width pos = np.arange(len(x_axis)) width = 1.0 # 将统计的职位信息使用matplotlib生成柱状图 from matplotlib import pyplot as plt ax = plt.axes() ax.set_xticks(pos + (width / 2)) ax.set_xticklabels(x_axis) plt.bar(pos, y_axis, width, color=‘lightblue‘) plt.xticks(rotation=30) fig = plt.gcf() fig.set_size_inches(16, 10) plt.show()
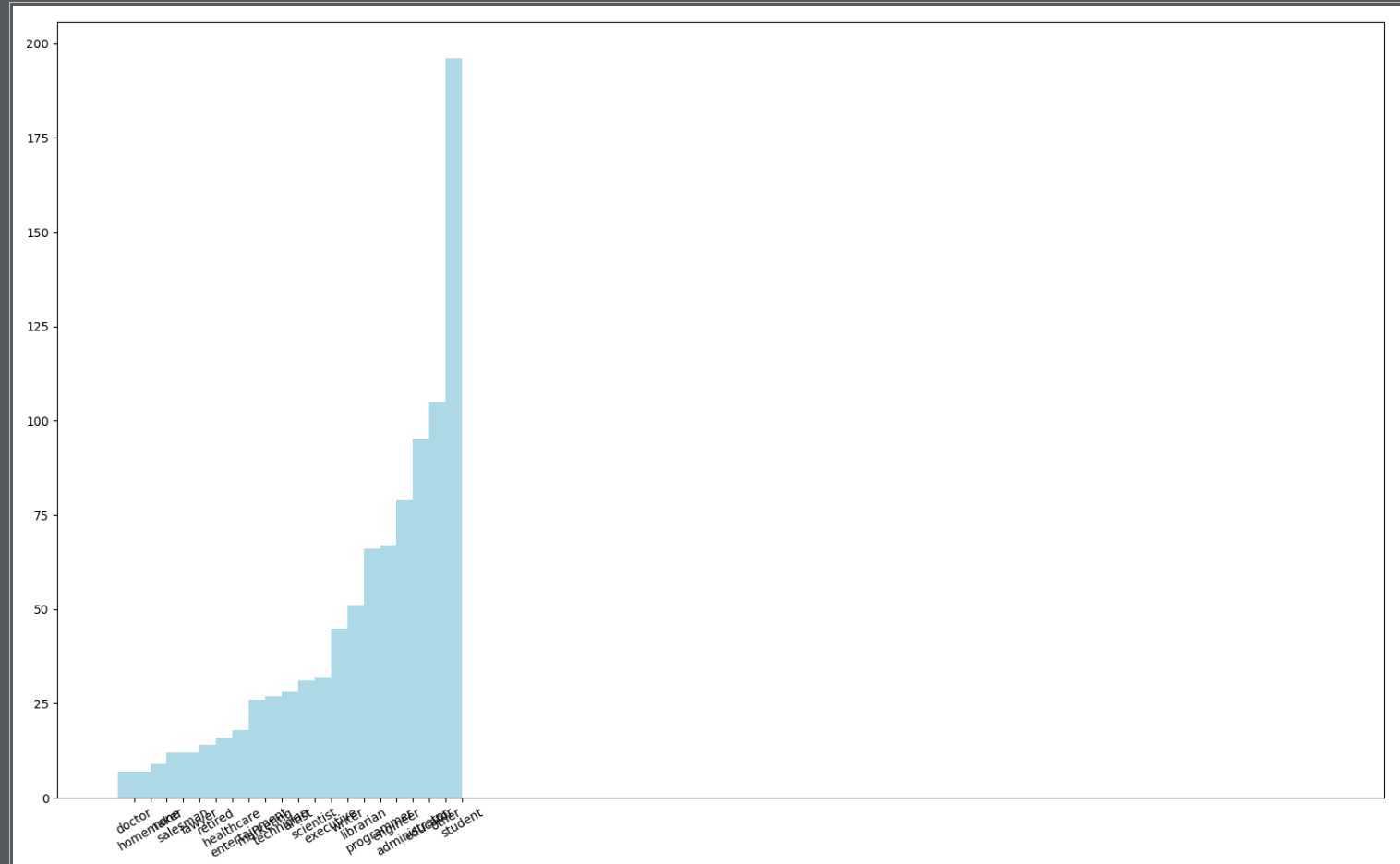
处理三(电影发布信息统计分析)
处理三简介:
首先对用户数据处理,获得用户评价的电影发布时间信息。然后以1998年为最高年限减去电影发布的年限(数据集统计的时间为1998年)得到的值作为x轴,接着通过Python中的图形框架Matplotlib生成柱状图,最后通过柱状图分析当时电影发布时间趋势。
电影信息有一些脏数据,所以需要先作处理。
处理三所有代码:
import pandas as pd
from pyspark.sql import SparkSession
from pyspark import SparkContext
from pyspark.sql import SQLContext
from pyspark.sql.types import *
# solve the question:AttributeError: ‘PipelinedRDD‘ object has no attribute ‘toDF‘
spark=SparkSession.builder.appName("lz").getOrCreate()
sc = SparkContext.getOrCreate()
# 从HDFS中加载u.item数据
movie_data = sc.textFile("/Users/xdstar/Desktop/ml-100k/u.item")
# 打印第一条数据,查看数据格式
print(movie_data.first())
# 统计电影总数
num_movies = movie_data.count()
print("Movies: %d" % num_movies)
# 定义函数功能为对电影数据预处理,对于错误的年限,使用1900填补
def convert_year(x):
try:
return int(x[-4:])
except:
return 1900 # there is a ‘bad‘ data point with a blank year,which we set to 900 and will filter out later
# 使用"|"分隔符分割每行数据
movie_fields = movie_data.map(lambda lines: lines.split("|"))
# 提取分割后电影发布年限信息,并做脏数据预处理
years = movie_fields.map(lambda fields: fields[2]).map(lambda x: convert_year(x))
print(years.first(),‘这是年限===‘)
# 获取那些年限为1900的电影(部分为脏数据)
years_filtered = years.filter(lambda x: x != 1900)
# 计算出电影发布时间与1998年的年限差
movie_ages = years_filtered.map(lambda yr: 1998 - yr).countByValue()
print(movie_ages.values(),movie_ages.keys(),‘年限差‘)
# 将年限差作为x轴,电影数量作为y轴作柱状图
values = movie_ages.values()
bins =sorted(list(movie_ages.keys())) #这里注意bins 要是一个有序的列表,升序的,否则会报错
width = bins[1] - bins[0]
from matplotlib import pyplot as plt1
plt1.hist(values, bins=bins, color=‘lightblue‘, normed=True,)
fig = plt1.gcf()
fig.set_size_inches(16, 10)
plt1.show()
得到的图
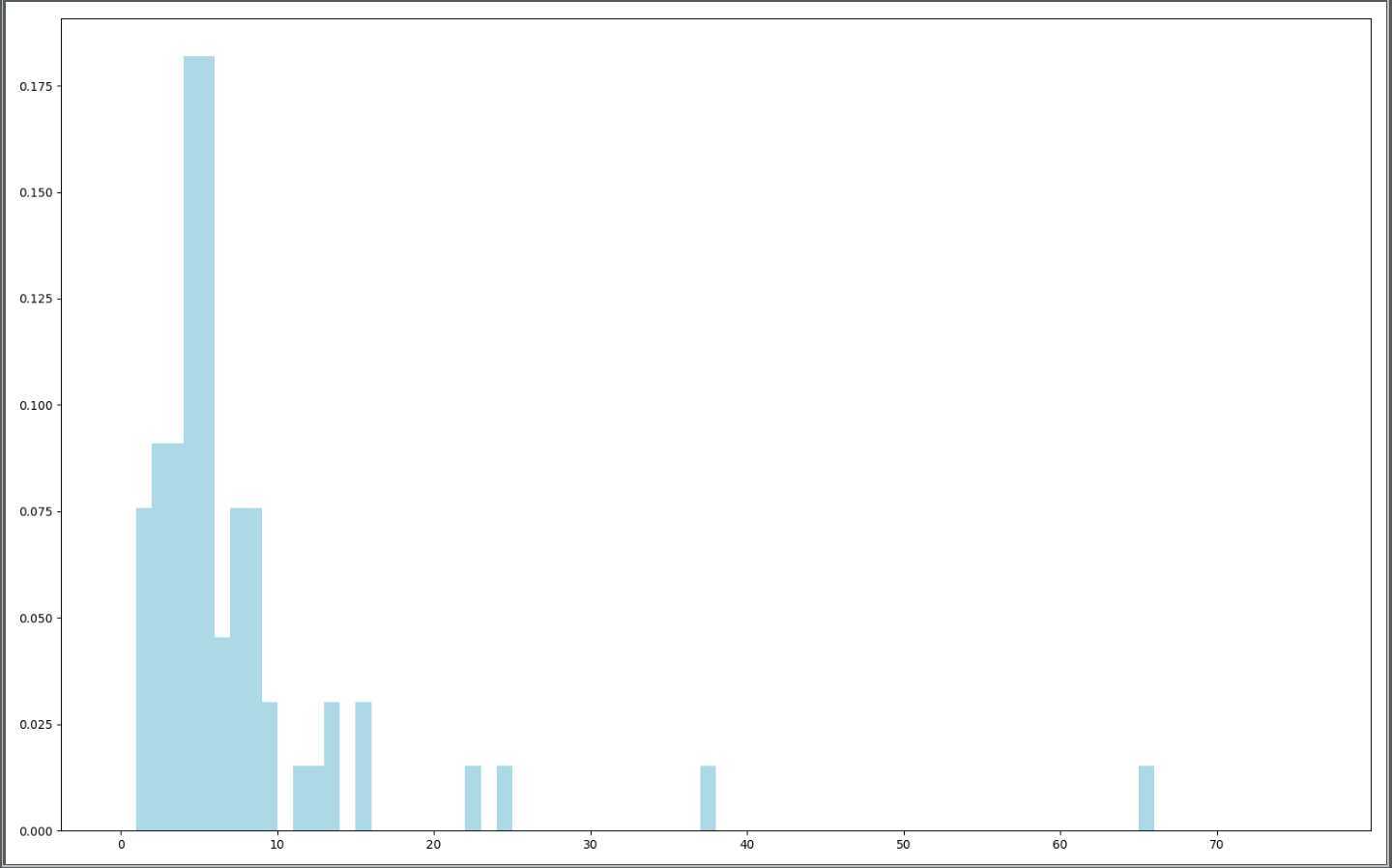
转自:https://www.cnblogs.com/wangkun122/articles/10676034.html
原文:https://www.cnblogs.com/tjp40922/p/13128315.html