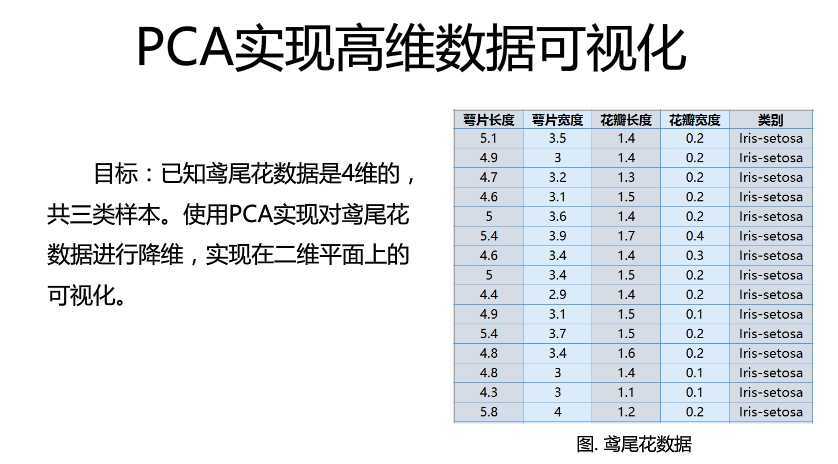
1.介绍








2.代码
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
from pylab import mpl
mpl.rcParams[‘font.sans-serif‘] = [‘SimHei‘] # 设置matplotlib可以显示汉语
mpl.rcParams[‘axes.unicode_minus‘] = False
def pca():
data=load_iris() #载入数据到字典
y = data.target #数据属性
X = data.data #具体数值
pca = PCA(n_components=2) #主成分为2(降维二)
reduced_x = pca.fit_transform(X)
#分三类鸢尾花存值
red_x,red_y=[],[]
blue_x,blue_y=[],[]
green_x,green_y=[],[]
#把降维后的数据按target存值
for i in range(len(reduced_x)):
if y[i]==0:
red_x.append(reduced_x[i][0])
red_y.append(reduced_x[i][1])
elif y[i]==1:
blue_x.append(reduced_x[i][0])
blue_y.append(reduced_x[i][1])
else:
green_x.append(reduced_x[i][0])
green_y.append(reduced_x[i][1])
#散点图绘制
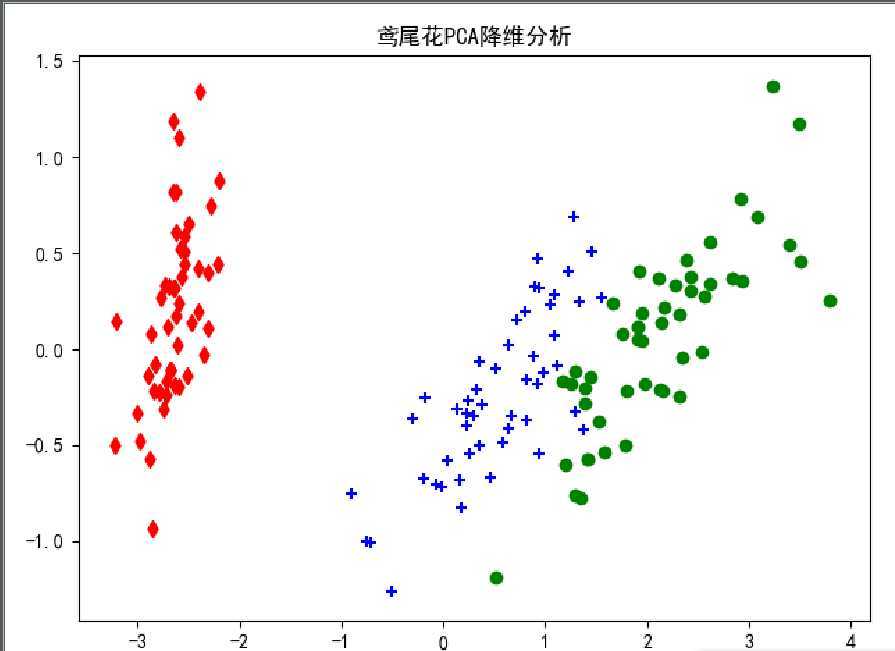
plt.scatter(red_x,red_y,c=‘r‘,marker=‘d‘)
plt.scatter(blue_x,blue_y,c=‘b‘,marker=‘+‘)
plt.scatter(green_x,green_y,c=‘g‘,marker=‘o‘)
plt.title(‘鸢尾花PCA降维分析‘)
plt.legend(loc=‘best‘)
plt.show()
if __name__ == ‘__main__‘:
pca()
3.输出
原文:https://www.cnblogs.com/cheflone/p/13132521.html