在猪师的手把手教导下体验了下爬虫,
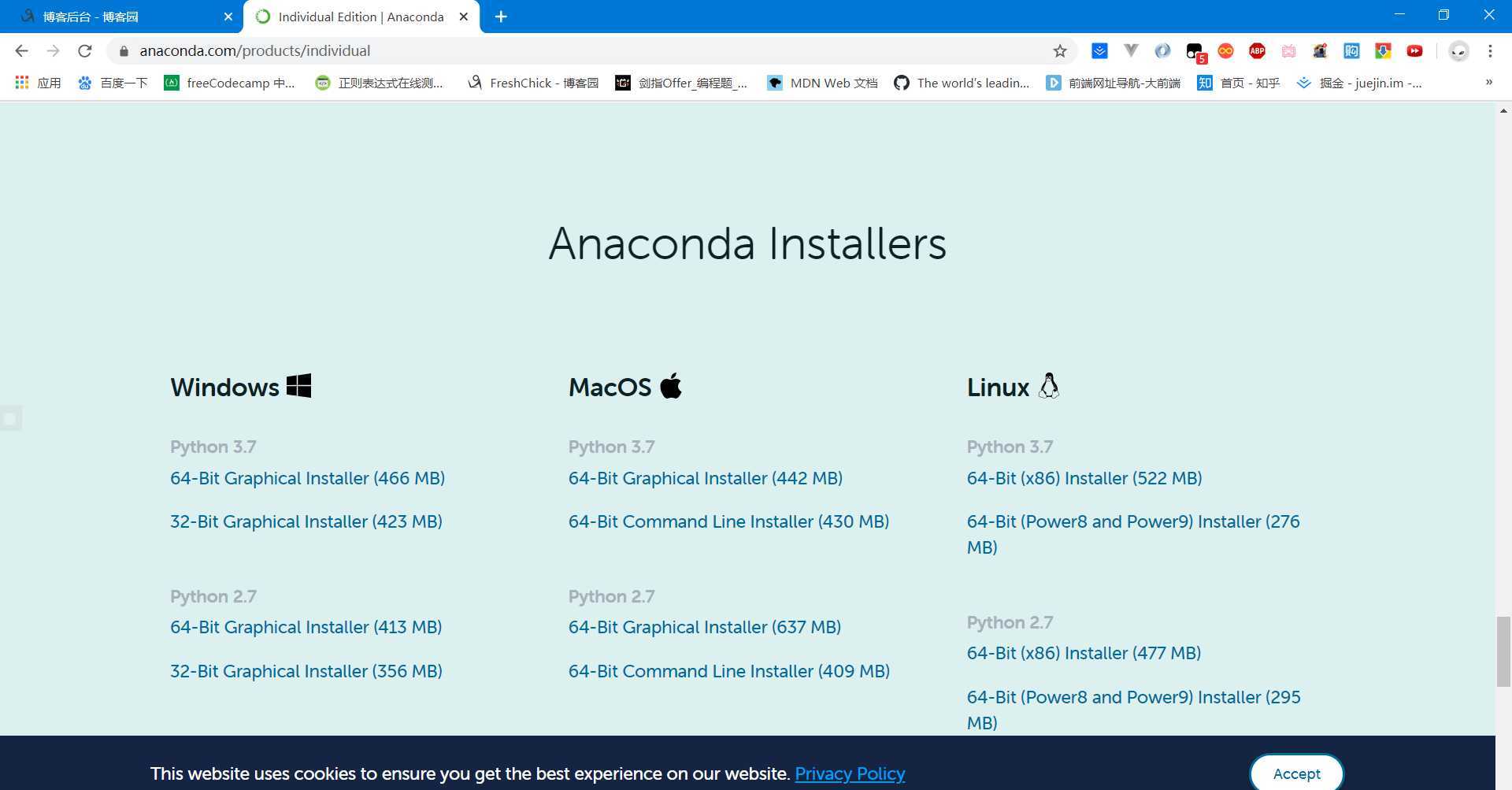
首先是进入anaconda官网,选择一个版本下载
安装时候,记住要勾选带path的选项。
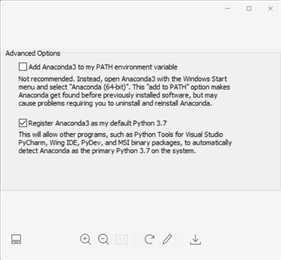
避免python版本混乱
然后初试request跟re模块的用法,直接import即可,
爬取百度,但是出现乱码
把.text改为.content.decode("utf-8")即可。
加入正则
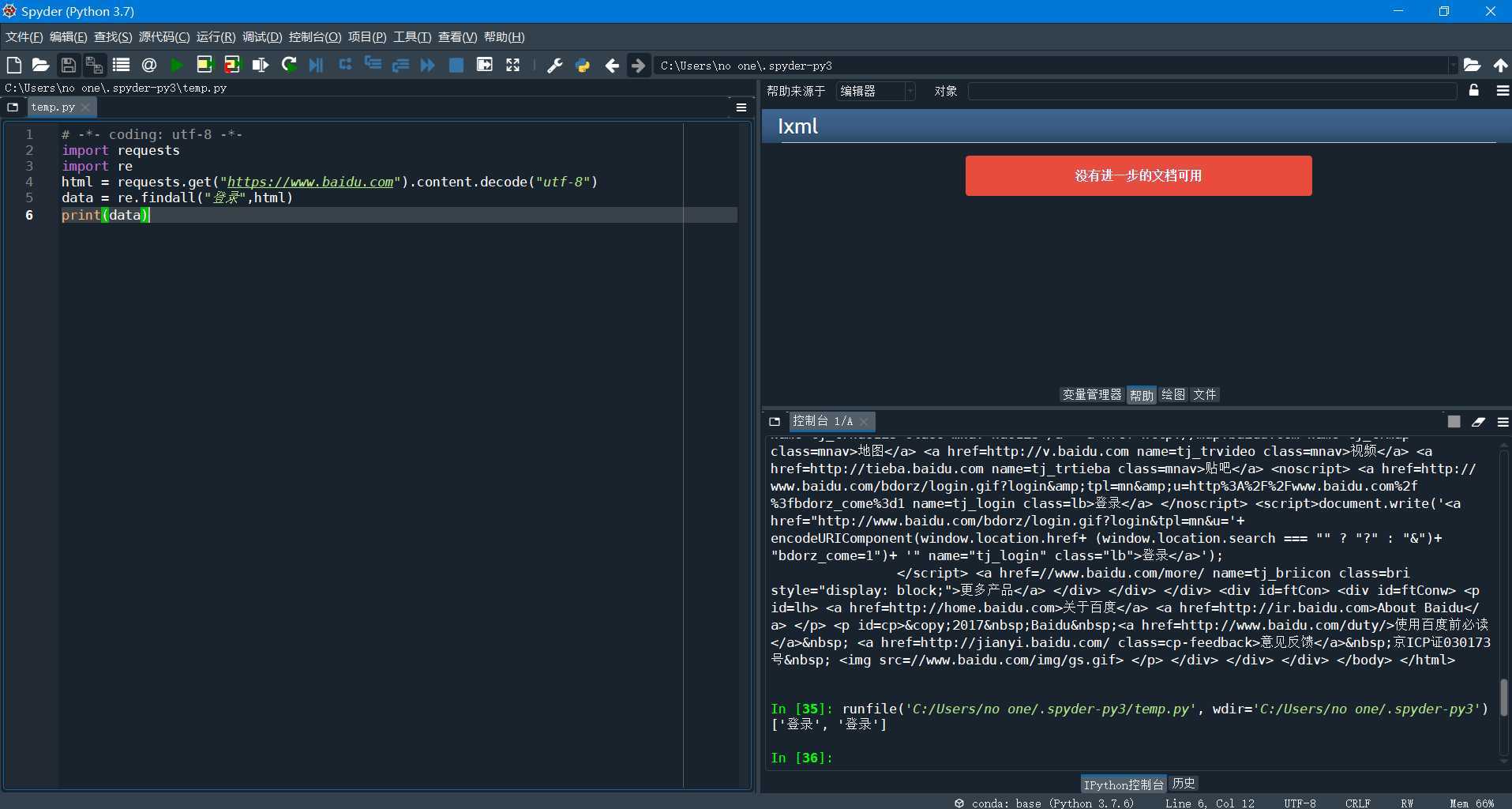
然后读取一个特定的标签
首先引入lxml这个包, cmd中用conda install lxml安装
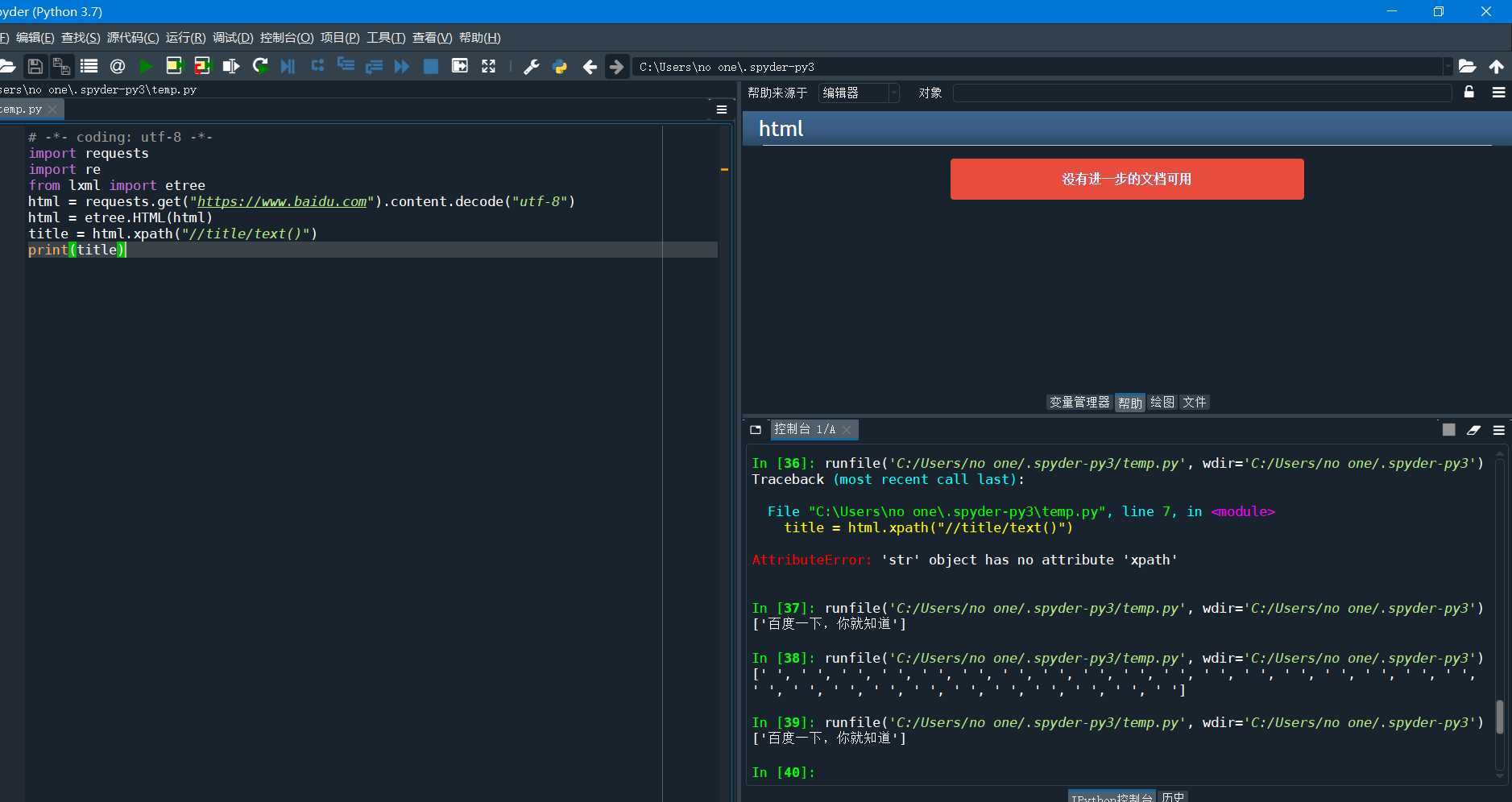
其中//代表不管前面的父元素,title是一个标签,/text()是获取标签里面的文本。
这里的网页也可以直接用api,若一些需要参数的api,写入请求即可。
原文:https://www.cnblogs.com/ljg1998/p/13138496.html