Java中的线程池是运用场景最多的并发框架,几乎所有需要异步或并发执行任务的程序都可以使用线程池。在开发过程中,合理地使用线程池,相对于单线程串行处理(Serial Processing)和为每一个任务分配一个新线程(One Task One New Thread)的做法能够带来3个好处。
下面所有的介绍都是基于JDK 1.8源码。
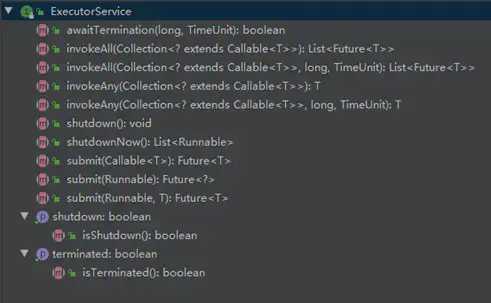
Java中的线程池核心实现类是ThreadPoolExecutor。这个类的设计是继承了AbstractExecutorService抽象类和实现了ExecutorService,Executor两个接口,关系大致如下图所示:

下面将从顶向下逐个介绍这个4个接口与类。
顶层接口Executor提供了一种将任务提交和每个任务的执行机制(包括线程使用的细节以及线程调度等)解耦分开的方法。使用Executor可以避免显式的创建线程。例如,对于一系列的任务,你可能会使用下列这种方式来代替new Thread(new(RunnableTask())).start()的方式:
Executor executor = anExecutor; executor.execute(new RunnableTask1()); executor.execute(new RunnableTask2());
Executor接口提供了一个接口方法,用来在未来的某段时间执行指定的任务。指定的任务
这些可能执行方式都取决于Executor接口实现类的设计或实现方式。
public interface Executor {
void execute(Runnable command);
}
事实上,Executor接口并没有严格的要求线程的执行需要异步进行。最简单的接口实现方法是,将所有的任务以调用方法的线程执行。
class DirectExecutor implements Executor {
public void execute(Runnable r) {
r.run();
}
}
这种实际上就是上面提到的Serial Processing的方式。假设,我们现在以这种方式去实现一个响应请求的服务器应用。那么,这种实现方式虽然在理论上是正确的。
但是其性能却非常差,因为它每次只能响应处理一个请求。如果有大量请求则只能串行响应。
同时,如果服务器响应逻辑里面有文件I/O或者数据库操作,服务器需要等待这些操作完成才能继续执行。这个时候如果阻塞的时间过长,服务器资源利用率就很低。这样,在等待过程中,服务器CPU将处于空闲状态。
综上,这种Serial Processing的方式方式就会有无法快速响应问题和低吞吐率问题。
不过,更典型的实现方式是,任务由一些其他的线程执行而不是方法调用的线程执行。例如,下面的Executor的实现方法是对于每一个任务都新建一个线程去执行。
class ThreadPerTaskExecutor implements Executor {
public void execute(Runnable r) {
new Thread(r).start();
}
}
这种方式实际上就是上面提到的One Task One New Thread的方式,这种无限创建线程的方法也有很多问题。
ExecutorService接口是继承自Executor接口,并增加了一些接口方法。接口也可以继承?以前没注意,现在学习到了。这里介绍下接口继承的语义:
接口Executor有execute(Runnable)方法,接口ExecutorService继承Executor,不用复写Executor的方法。只需要,写自己的方法(业务)即可。
当一个类ThreadPoolExecutor要实现ExecutorService接口的时候,需要实现ExecutorService和Executor两个接口的方法。
ExecutorService大致新增了2类接口方法:
ExecutorService的关闭方法。对于线程池实现,这些方法的具体实现在ThreadPoolExecutor里面。
扩充异步执行任务的方法。对于线程池实现,用的这类方法都是AbstractExecutorService抽象类里面实现的模板方法。
抽象类AbstractExecutorService提供了ExecutorService接口类中各种submit异步执行方法的实现,这些方法与Executor.execute(Runnable)相比,它们都是有返回值的。同时,这些方法的实现的最终都是调用ThreadPoolExecutor类中实现的execute(Runnable)方法。
尽管说submit方法能提供线程执行的返回值,但只有实现了Callable才会有返回值,而实现Runnable的返回值是null。
public Future<?> submit(Runnable task) {
if (task == null) throw new NullPointerException();
RunnableFuture<Void> ftask = newTaskFor(task, null);
execute(ftask);
return ftask;
}
public <T> Future<T> submit(Runnable task, T result) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task, result);
execute(ftask);
return ftask;
}
public <T> Future<T> submit(Callable<T> task) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task);
execute(ftask);
return ftask;
}
除此之外,这个抽象类中还有ExecutorService接口类中invokeAny和invokeAll方法的实现。这里就只是简单介绍下这2个种方法的语义。
线程池是如何执行输入的任务,这个整个线程池实现的核心逻辑,我们从这个方法开始学习。其代码如下所示:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}
可以发现,当提交一个新任务到线程池时,线程池的处理流程如下:
以流程图来说明的话,线程池处理一个新提交的任务的流程如下图所示:
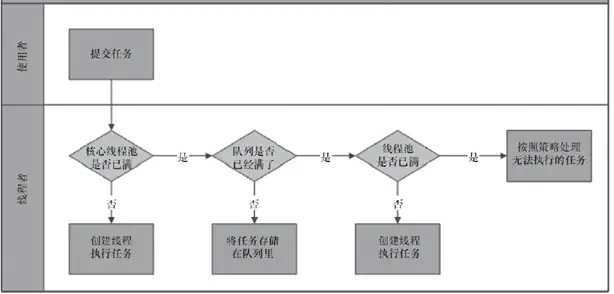

从上面的内容,我们可以发现线程池对于一个新任务有4种处理的可能,分别对应于上面处理流程的4个步骤。
ThreadPoolExecutor采取上述步骤的总体设计思路,是为了在执行execute()方法时,尽可能地避免获取全局锁(那将会是一个严重的可伸缩瓶颈)。在ThreadPoolExecutor完成预热之后(当前运行的线程数大于等于corePoolSize),几乎所有的execute()方法调用都是执行步骤2,而步骤2不需要获取全局锁。
从上面execute(Runnable)的代码我们可以发现,线程池创建线程时,会将线程封装成工作线程Worker,Worker在执行完任务后,还会循环获取工作队列里的任务来执行。
ThreadPoolExecutor中线程执行任务的示意图如下所示:
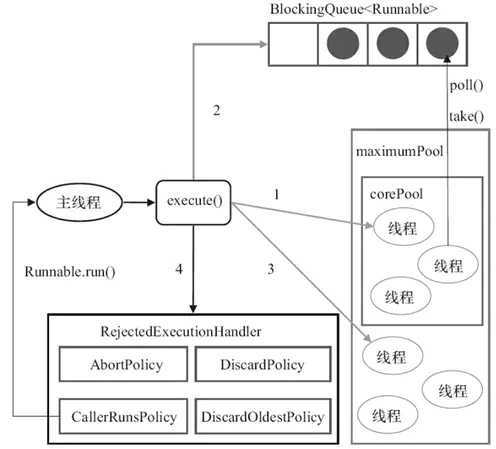
线程池中的线程执行任务分两种情况:
ctl 是一个 AtomicInteger 的类,保存的 int 变量的更新都是原子操作,保证线程安全。它的前面3位用来表示线程池状态,后面29位用来表示工程线程数量。
线程池的状态有5种:
Running:线程池处在Running的状态时,能够接收新任务,以及对已添加的任务进行处理。线程池的初始化状态是RUNNING。换句话说,线程池被一旦被创建,就处于Running状态,并且线程池中的任务数为0。
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
Shutdown: 线程池处在SHUTDOWN状态时,不接收新任务,但能处理已添加(正在运行的以及在BlockingQueue)的任务。调用线程池的shutdown()接口时,线程池由RUNNING -> SHUTDOWN。
Stop: 线程池处在STOP状态时,不接收新任务,不处理已添加的任务,并且会中断正在运行的任务。 调用线程池的shutdownNow()接口时,线程池由(RUNNING or SHUTDOWN ) -> STOP。
Tidying: 当所有的任务已终止,ctl记录的”任务数量”为0,线程池会变为Tidying状态。当线程池变为Tidying状态时,会执行钩子函数terminated()。terminated()在ThreadPoolExecutor类中是空的,若用户想在线程池变为Tidying时,进行相应的处理;可以通过重载terminated()函数来实现。
Terminated: 线程池彻底终止,就变成Terminated状态。 线程池处在Tidying状态时,执行完terminated()之后,就会由 Tidying -> Terminated。
我们可以通过ThreadPoolExecutor的构造函数来创建一个线程池。
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
通过Executor框架的工具类Executors,可以创建以下3种类型的ThreadPoolExecutor。通过源码可以发现这3种线程池的本质都是不同输入参数配置的ThreadPoolExecutor。
FixedThreadPool被称为可重用固定线程数的线程池。下面是FixedThreadPool的源代码实现。
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
注意到,
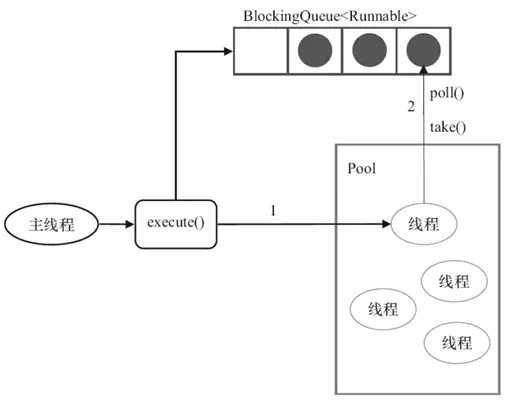
FixedThreadPool的execute()方法的运行示意图如下所示:
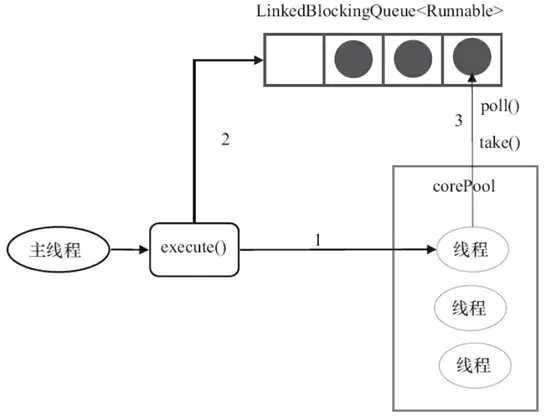
其运行说明:
FixedThreadPool使用无界队列LinkedBlockingQueue作为线程池的工作队列(队列的容量为Integer.MAX_VALUE)对线程池会带来如下影响:
SingleThreadExecutor是使用单个worker线程的Executor。SingleThreadExecutor与FixedThreadPool类似,只是它的corePoolSize和maximumPoolSize被设置为1。下面是SingleThreadExecutor的源代码实现。
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
CachedThreadPool是一个会根据需要创建新线程的线程池。下面是创建CachedThread-Pool的源代码。
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
注意到:
CacheThreadPool的execute()方法的执行过程如下图所示:
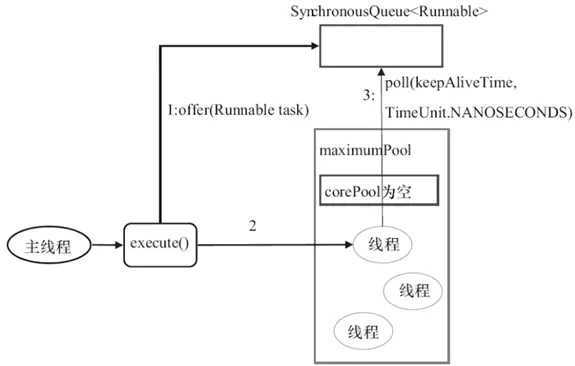
其执行过程的说明如下:
可以使用两个方法向线程池提交任务,分别为execute()和submit()方法。
execute()方法用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功。一般execute()方法输入的任务是一个Runnable类的实例。
submit()方法用于提交需要返回值的任务。线程池会返回一个future类型的对象,通过这个future对象可以判断任务是否执行成功,并且可以通过future的get()方法来获取返回值,get()方法会阻塞当前线程直到任务完成,而使用get(long timeout,TimeUnit unit)方法则会阻塞当前线程一段时间后立即返回,这时候有可能任务没有执行完。
可以通过调用线程池的shutdown或者shutdownNow方法来关闭线程池。它们的原理是遍历线程池中的工作线程,然后逐个调用线程的interrupt方法来中断线程,所以无法响应中断的任务可能永远无法终止。但是它们存在一定的区别。
可以通过线程池提供的参数进行监控,在监控线程池的时候可以使用以下属性:
taskCount:线程池需要执行的任务数量。
completedTaskCount:线程池在运行过程中已完成的任务数量,小于或等于taskCount。
largestPoolSize:线程池里曾经创建过的最大线程数量。通过这个数据可以知道线程池是 否曾经满过。如该数值等于线程池的最大大小,则表示线程池曾经满过。
getPoolSize:线程池的线程数量。如果线程池不销毁的话,线程池里的线程不会自动销 毁,所以这个大小只增不减。
getActiveCount:获取活动的线程数。
另外,通过扩展线程池进行监控。可以通过继承线程池来自定义线程池,重写线程池的beforeExecute、afterExecute和terminated方法,也可以在任务执行前、执行后和线程池关闭前执行一些代码来进行监控。例如,监控任务的平均执行时间、最大执行时间和最小执行时间等。这几个方法在线程池里是空方法。
深度分析:Java并发编程之线程池技术,看完面试这个再也不慌了!
原文:https://www.cnblogs.com/lwh1019/p/13144435.html