安装ElasticSearch
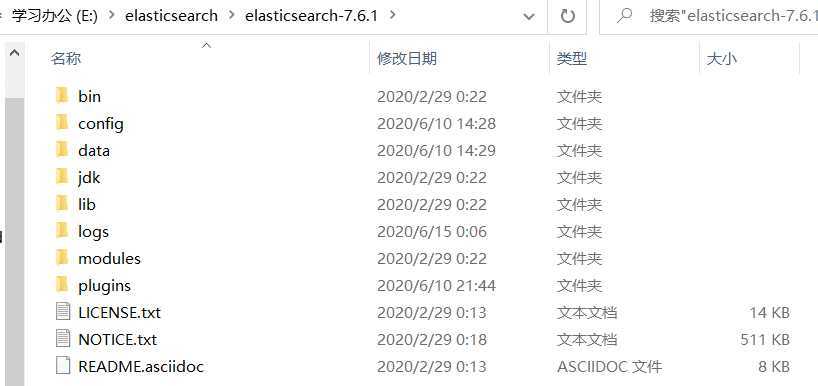
bin #启动文件
config #配置文件
log4j2 #日志配置文件
jvm.options #java 虚拟机相关的配置
elasticsearch.yml ? #elasticsearch 的配置文件
lib #相关jar包
logs #日志
modules #功能模块
plugins #插件
安装ES可视化插件head
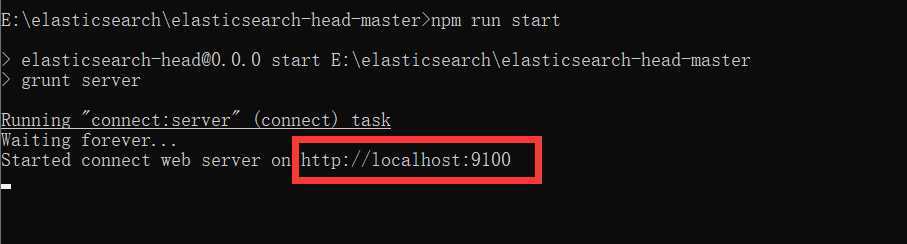
npm install
npm run start
若存在跨域问题,修改elasticsearch.yml配置文件,在文件末尾添加:
http.cors.enabled: true
http.cors.allow-origin: "*"
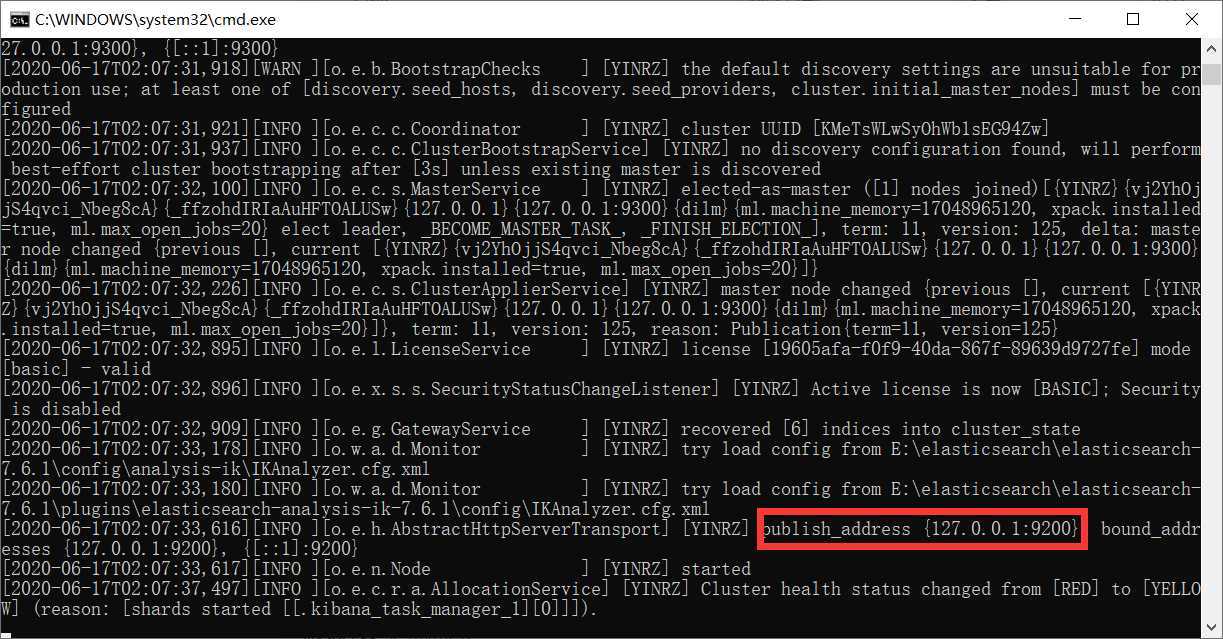
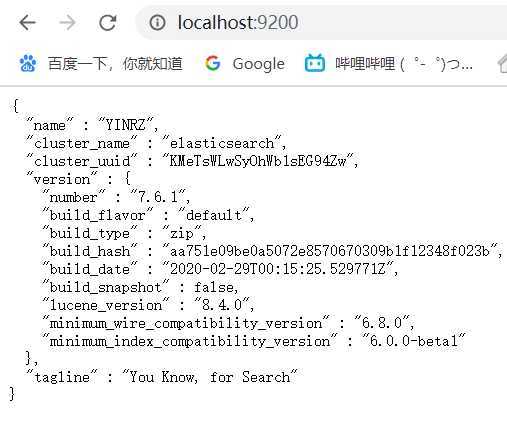
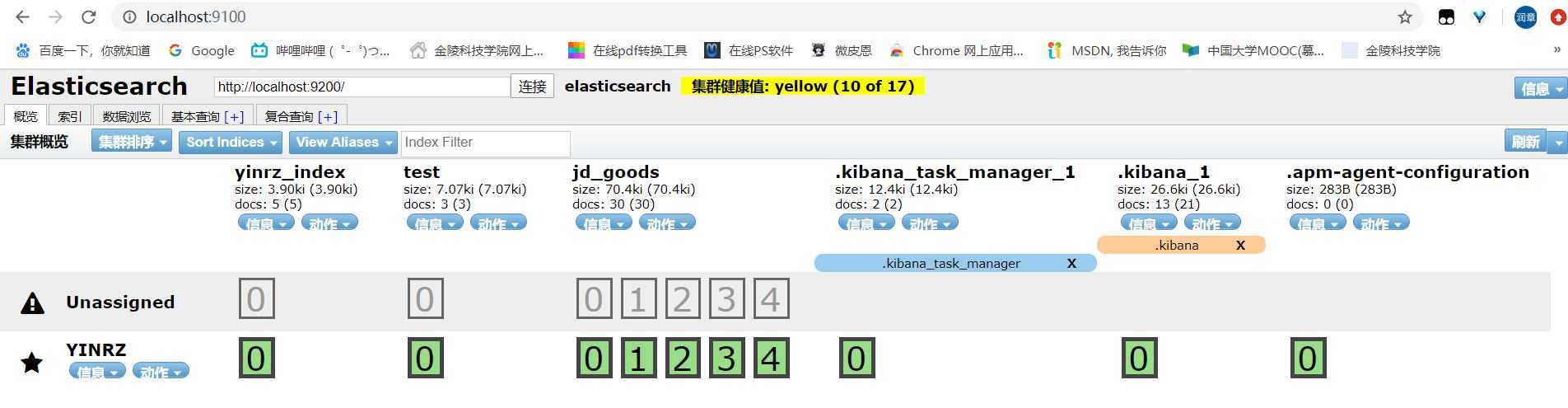
运行结果:
安装Kibana
Kibana是一个针对Elasticsearch的开源分析及可视化平台,用来搜索、查看交互存储在Elasticsearch索 引中的数据。使用Kibana,可以通过各种图表进行高级数据分析及展示。Kibana让海量数据更容易理解。它操作简单,基于浏览器的用户界面可以快速创建仪表板(dashboard)实时显示Elasticsearch查 询动态。设置Kibana非常简单。无需编码或者额外的基础架构,几分钟内就可以完成Kibana安装并启动 Elasticsearch索引监测。
解压
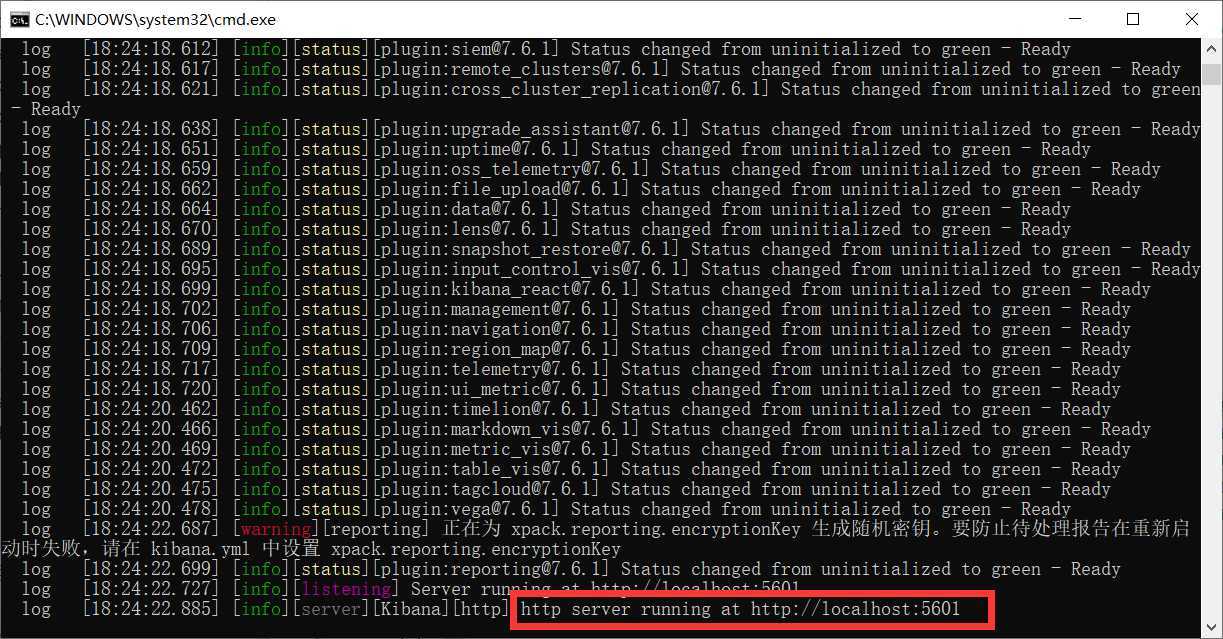
进入config目录,修改kibana.yml文件,在文件末尾添加:
i18n.locale: "zh-CN"
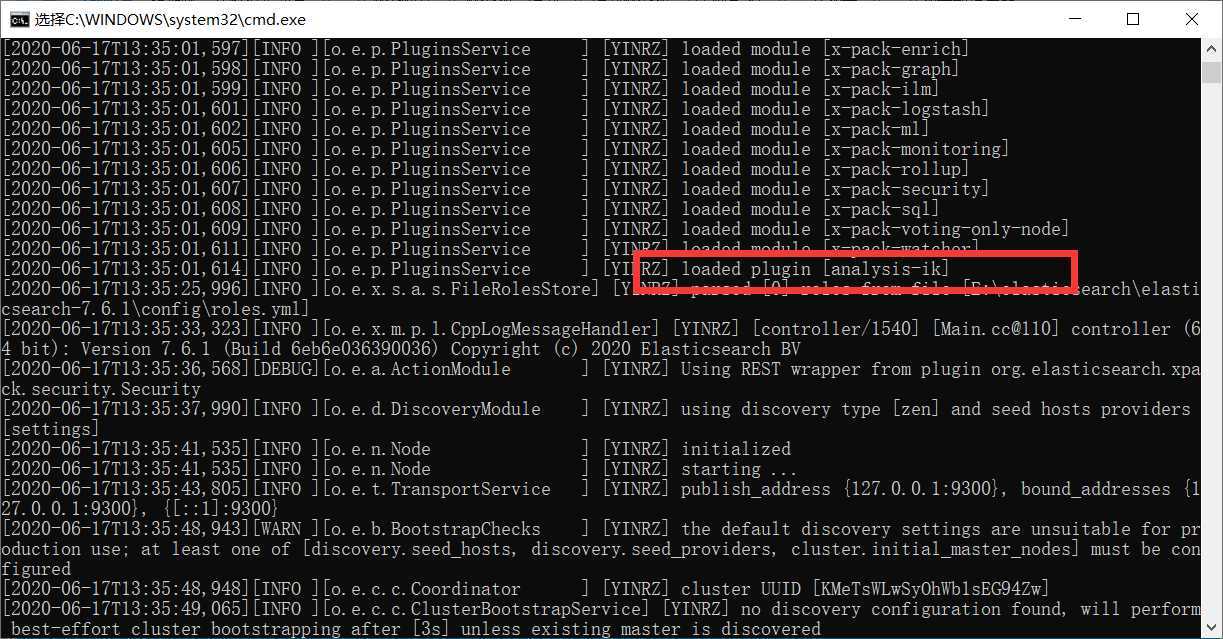
IK分词器安装
分词:即把一段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词是将每个字看成一个词,比如 “你好世界” 会被分为"你","好","世","界",这显然是不符合要求的,所以我们需要安装中文分词器ik来解决这个问题。 如果要使用中文,建议使用ik分词器!
IK提供了两个分词算法:ik_smart 和 ik_max_word,其中 ik_smart 为少切分,ik_max_word为细粒度划分。

原文:https://www.cnblogs.com/yinrz/p/13152020.html