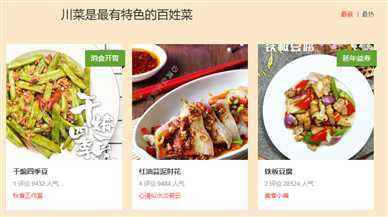
目的:如图,抓取美食节川菜的菜品图片路径,首页一共有18张(分页爬取的解决方案可查看我的其他网络爬虫类博文,有详细描述。其他信息可对照,原理相同)
import requests from lxml import etree def main(): #抓取美食杰川菜相关信息 url=‘https://www.meishij.net/china-food/caixi/chuancai/‘ headers = { ‘User_Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36‘ } response=requests.get(url=url,headers=headers) response.encoding=‘utf-8‘ page_text=response.text #print(page_text) tree=etree.HTML(page_text) #解析川菜菜品列表 src_list=tree.xpath(‘//div[@class="main_w clearfix"]//div[@class="listtyle1"]‘) #print(src_list,len(src_list)) #打印菜品的图片请求路径 for src in src_list: cai_url=src.xpath(‘a/img/@src‘)[0] print(cai_url) if __name__ == ‘__main__‘: main()
结果就是抓到了首页的18张图片路径:
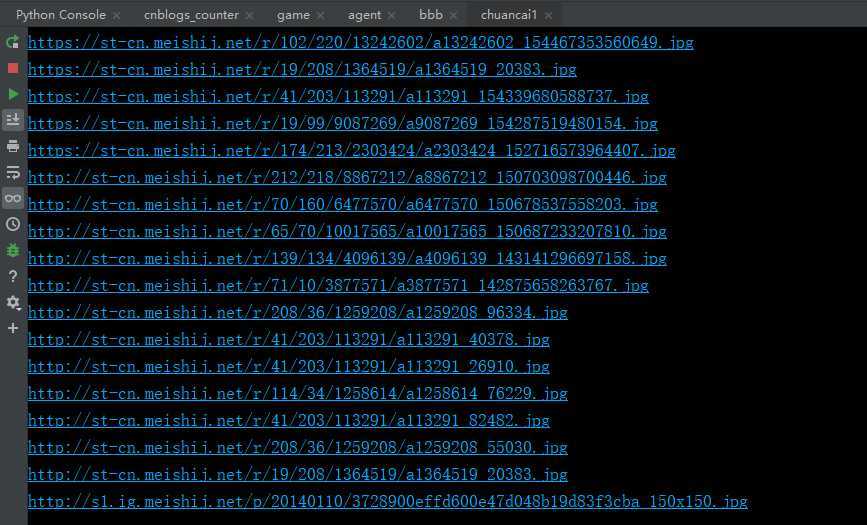
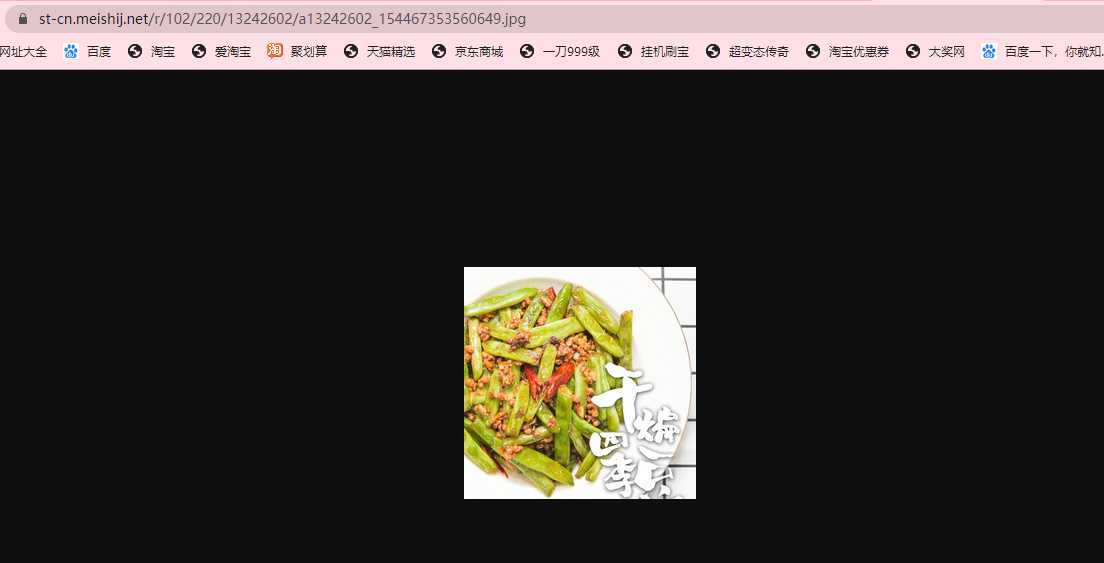
然后,随便点击任何一个图片路径就会访问到这张图片,比如,就点第一张:干煸四季豆
原文:https://www.cnblogs.com/andrew3/p/13156809.html