概要:
爬取雪球网站中相关的新闻数据
import requests
headers = {
‘User-Agent‘:‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61‘
}
url = ‘https://xueqiu.com/statuses/hot/listV2.json?since_id=-1&max_id=66208&size=15‘
json_data = requests.get(url=url,headers=headers).json()
print(json_data)
结果:
{‘error_description‘: ‘遇到错误,请刷新页面或者重新登录帐号后再试‘,
‘error_uri‘: ‘/statuses/hot/listV2.json‘,
‘error_data‘: None,
‘error_code‘: ‘400016‘}
上述代码没有获取想要的数据,问题原因?
手动处理将cookice信息添加到请求头中即可
import requests
headers = {
‘User-Agent‘:‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36‘,
‘Cookie‘:‘aliyungf_tc=AQAAANW0eGAa9gsAWFJ5eyKzKfjHGKly; acw_tc=2760824315924751287984449e7480f71707bc6a5df30bb7aa7b4a2af287e9; xq_a_token=ea139be840cf88ff8c30e6943cf26aba8ad77358; xqat=ea139be840cf88ff8c30e6943cf26aba8ad77358; xq_r_token=863970f9d67d944596be27965d13c6929b5264fe; xq_id_token=eyJ0eXAiOiJKV1QiLCJhbGciOiJSUzI1NiJ9.eyJ1aWQiOi0xLCJpc3MiOiJ1YyIsImV4cCI6MTU5NDAwMjgwOCwiY3RtIjoxNTkyNDc1MDcxODU5LCJjaWQiOiJkOWQwbjRBWnVwIn0.lQ6Kp8fZUrBSjbQEUpv0PmLn2hZ3-ixDvYgNPr8kRMNLt5CBxMwwAY9FrMxg9gt6UTA4OJQ1Gyx7oePO1xJJsifvAha_o92wdXP55KBKoy8YP1y2rgh48yj8q61yyY8LpRTHP5RKOZQITh0umvflW4zpv05nPr7C8fHTME6Y80KspMLzOPw2xl7WFsTGrkaLH8yw6ltKvnupK7pQb1Uw3xfzM1TzgCoxWatfjUHjMZguAkrUnPKauEJBekeeh3eVaqjmZ7NzRWtLAww8egiBqMmjv5uGMBJAuuEBFcMiFZDIbGdsrJPQMGJdHRAmgQgcVSGamW8QWkzpyd8Tkgqbwg; u=161592475128805; device_id=24700f9f1986800ab4fcc880530dd0ed; Hm_lvt_1db88642e346389874251b5a1eded6e3=1592475130,1592475300; Hm_lpvt_1db88642e346389874251b5a1eded6e3=1592475421‘
}
url = ‘https://xueqiu.com/statuses/hot/listV2.json?since_id=-1&max_id=66208&size=15‘
json_data = requests.get(url=url,headers=headers).json()
print(json_data)
自动处理
import requests
headers = {
‘User-Agent‘:‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36‘,
}
sess = requests.Session() #返回一个session对象
#第一次调用session一定是为了捕获cookie
main_url = ‘https://xueqiu.com/‘
sess.get(url=main_url,headers=headers) #目的:尝试捕获cookie,cookie就会被存储到session
url = ‘https://xueqiu.com/statuses/hot/listV2.json?since_id=-1&max_id=65993&size=15‘
#已经表示携带cookie发起了请求
json_data = sess.get(url=url,headers=headers).json()
print(json_data)
什么是代理
代理的作用
代理和爬虫之间的关联
代理的基本概念
如何获取代理?
智连HTTP使用
1、注册账号,添加当前本机的IP地址到白名单
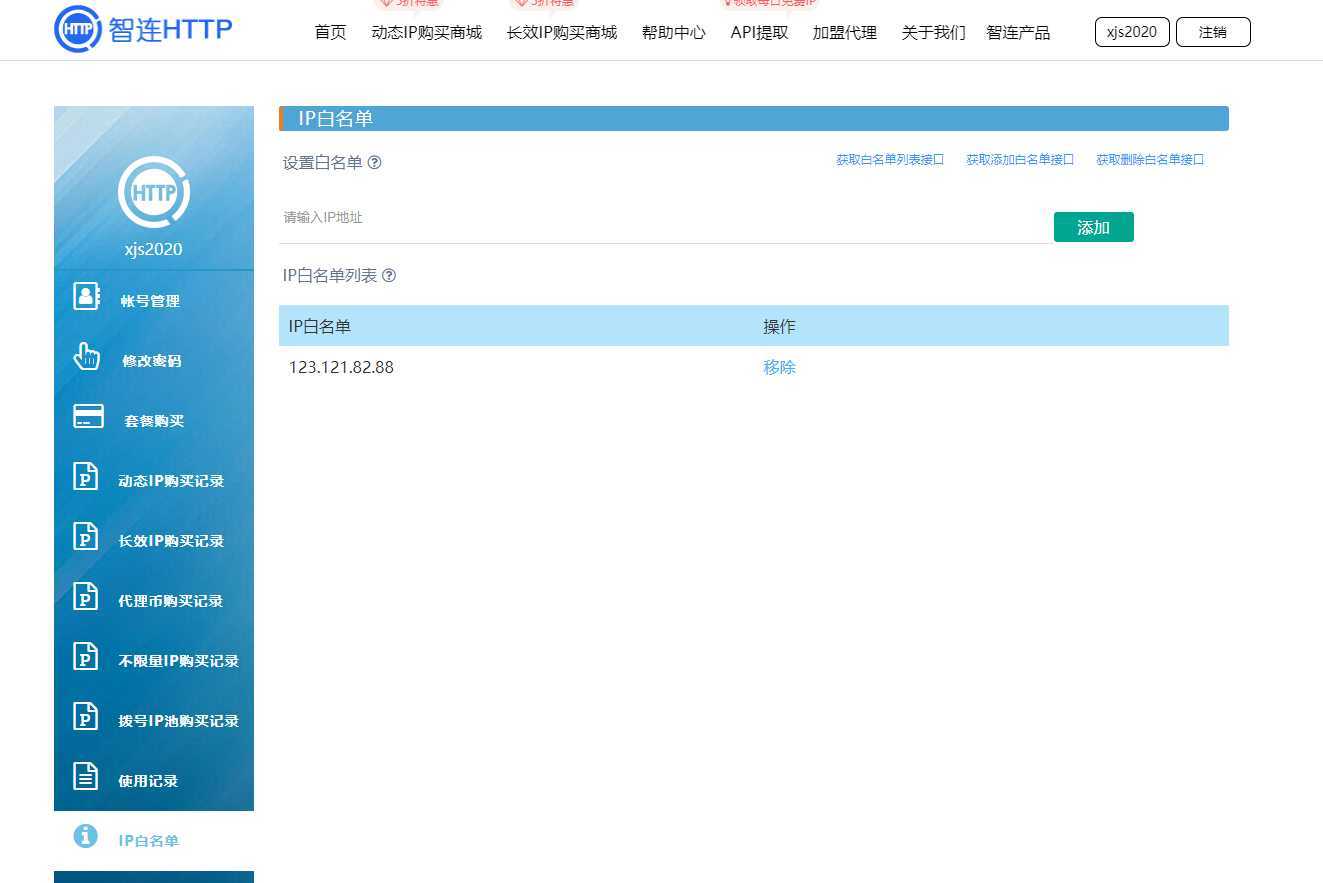
2、土豪可自行购买,在这,我使用的免费的,每天有免费的代理IP
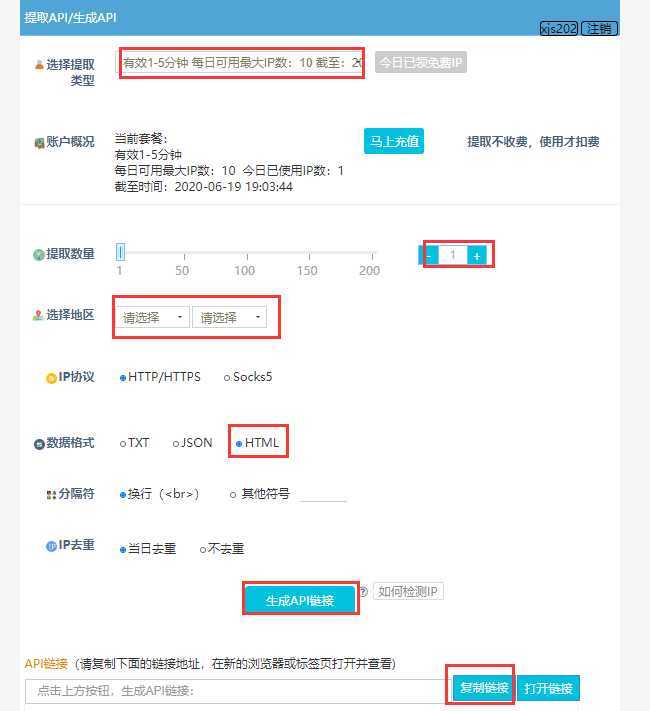
3、浏览器访问生成的代理ip链接,有1条代理IP

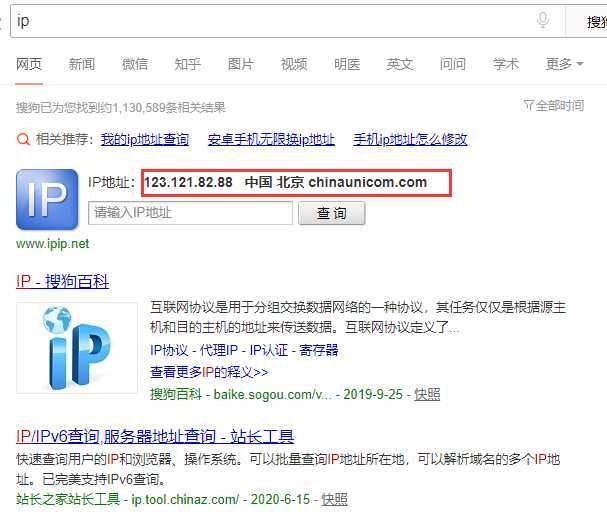
4、没有使用代理ip,查询本机ip
5、使用代理IP
from lxml import etree
import requests
headers = {
‘User-Agent‘:‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36‘,
}
url = ‘https://www.sogou.com/web?query=ip‘
#proxies参数:请求设置代理
page_text = requests.get(url=url,headers=headers,proxies={‘https‘:‘42.203.39.97:12154‘}).text
with open(‘./ip.html‘,‘w‘,encoding=‘utf-8‘) as fp:
fp.write(page_text)
6、打开生成的html文件查看IP信息
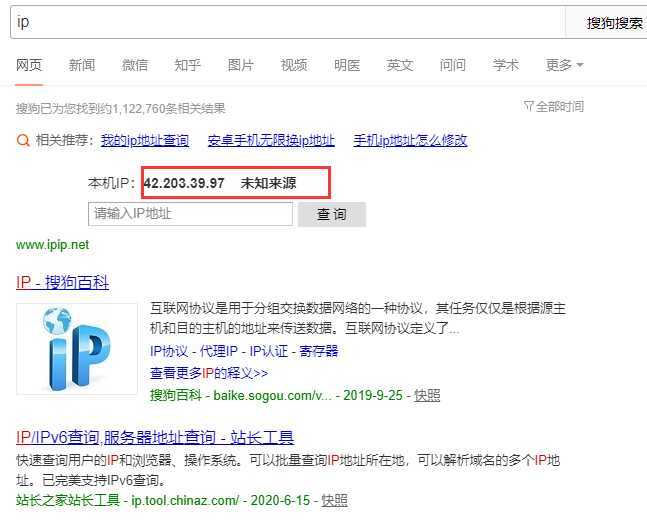
通过进行高频率数据访问爬取https://www.xicidaili.com/,结果本机IP被禁止访问,
from lxml import etree
import requests
headers = {
‘User-Agent‘:‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36‘,
}
#尝试发起高频请求,让对方服务器将本机ip禁掉
url = ‘https://www.xicidaili.com/nn/%d‘
ips = []
for page in range(1,30):
new_url = format(url%page)
page_text = requests.get(new_url,headers=headers).text
tree = etree.HTML(page_text)
#排除掉第一个tr标题标签属性
tr_list = tree.xpath(‘//*[@id="ip_list"]//tr‘)[1:]
for tr in tr_list:
ip = tr.xpath(‘./td[2]/text()‘)[0]
ips.append(ip)
print(len(ips)) #2900
#运行多次程序之后,发现本机ip已被禁掉,再次访问https://www.xicidaili.com/已经无法进行访问
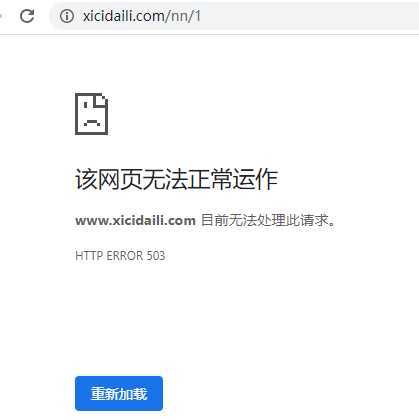
使用代理池进行数据爬取次数限制破解
重新获取3个代理IP
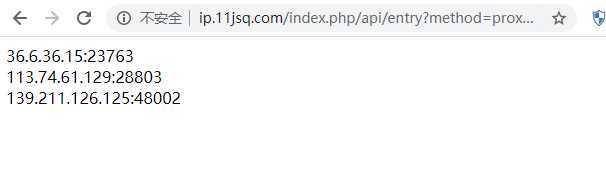
构建一个代理池:大列表,需要装载多个不同的代理
from lxml import etree
import requests
headers = {
‘User-Agent‘:‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36‘,
}
proxy_list = [] #代理池
proxy_url = ‘http://ip.11jsq.com/index.php/api/entry?method=proxyServer.generate_api_url&packid=1&fa=0&fetch_key=&groupid=0&qty=3&time=1&pro=&city=&port=1&format=html&ss=5&css=&dt=1&specialTxt=3&specialJson=&usertype=15‘
page_text = requests.get(url=proxy_url,headers=headers).text
tree = etree.HTML(page_text)
ips_list = tree.xpath(‘//body//text()‘)
for ip in ips_list:
dic = {‘https‘:ip}
proxy_list.append(dic)
print(proxy_list)
>>>
[{‘https‘: ‘122.143.86.183:28803‘}, {‘https‘: ‘182.202.223.253:26008‘}, {‘https‘: ‘119.114.239.41:50519‘}]
完整代码
import random
from lxml import etree
import requests
headers = {
‘User-Agent‘:‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36‘,
}
proxy_list = [] #代理池
proxy_url = ‘http://ip.11jsq.com/index.php/api/entry?method=proxyServer.generate_api_url&packid=1&fa=0&fetch_key=&groupid=0&qty=3&time=1&pro=&city=&port=1&format=html&ss=5&css=&dt=1&specialTxt=3&specialJson=&usertype=15‘
page_text = requests.get(url=proxy_url,headers=headers).text
tree = etree.HTML(page_text)
ips_list = tree.xpath(‘//body//text()‘)
for ip in ips_list:
dic = {‘https‘:ip}
proxy_list.append(dic)
url = ‘https://www.xicidaili.com/nn/%d‘
ips = []
for page in range(1,5):
new_url = format(url%page)
page_text = requests.get(new_url,headers=headers,proxies=random.choice(proxy_list)).text
tree = etree.HTML(page_text)
tr_list = tree.xpath(‘//*[@id="ip_list"]//tr‘)[1:]
for tr in tr_list:
ip = tr.xpath(‘./td[2]/text()‘)[0]
ips.append(ip)
print(len(ips))
>>>400
windows也可对通过浏览器进行设置代理操作
原文:https://www.cnblogs.com/remixnameless/p/13160412.html