老样子,先上最后成功源码(在D盘下创建‘好看视频‘文件夹,直接运行即可获取视频):
import sys import re,os import requests from you_get import common as you_get def getVideo(url,path,headers): demo = requests.get(url,headers=headers) # 获取网站信息 data = demo.json() # 转换为JSON格式 data_list = data[‘data‘][‘response‘][‘videos‘] # 获取每个视频的属性列表 # 遍历,将每一个视频信息展示出来 for i in data_list: title = i[‘title‘] + ‘.mp4‘ # 获取视频名称(描述),视频要修改为的名称,为后边改名做准备 url1 = i[‘play_url‘] # 获取视频源url videoName = re.split(‘\?|/‘,url1)[5][:80]+‘.mp4‘ # 视频下载后,会是一大串字母和数字的组合,这个主要就是获取视频下载后的原名称 # 开始下载 print(‘开始下载:‘ + title) try: sys.argv = [‘you_get‘, ‘-o‘,path,url1] # 视频的属性编辑,选择路径等 you_get.main() # 开始下载 print(‘??下载完成‘) os.rename(path + videoName, path + title) # 下载完成后,改名操作 except: print(title + ‘下载失败!‘) if __name__ == ‘__main__‘: url = ‘https://haokan.baidu.com/videoui/api/videorec?tab=yingshi&act=pcFeed&pd=pc&num=20&shuaxin_id=1592551368953‘ headers = { ‘user-agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36 Edg/83.0.478.54‘, ‘cookie‘: ‘BIDUPSID=517516CBF0261FA0AF6B039EAFEDF39C; PSTM=1589624436; BAIDUID=517516CBF0261FA090A0395C8BF0F31A:FG=1; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; PC_TAB_LOG=haokan_website_page; Hm_lvt_4aadd610dfd2f5972f1efee2653a2bc5=1592530622,1592545903; H_PS_PSSID=31906_1444_31671_21118_31254_32045_30823_32111; delPer=0; PSINO=2; yjs_js_security_passport=d270bf2526b634428ea81932e213c285b8e7cf21_1592546748_js; Hm_lpvt_4aadd610dfd2f5972f1efee2653a2bc5=1592550475; reptileData=%7B%22data%22%3A%22e3b78a008f54876b4fc19fe55faea5fb1ae054d9580474b00db252837ba6a6554cbfde0ada4567b9cad2322c5d972031cb300664e248e8f4a7b27fd91a479f4e02a1e7eceffa642289eba12075334687515e1451aa72eced7ac42e3fbb88a87139c95727da119f5dd9b85d281d98d4d98b943f43a06c3f13e6b63b812c5c40ce%22%2C%22key_id%22%3A%2230%22%2C%22sign%22%3A%2243b164d6%22%7D‘} path = r‘D:\好看视频\\‘ getVideo(url,path,headers)
下载过程:
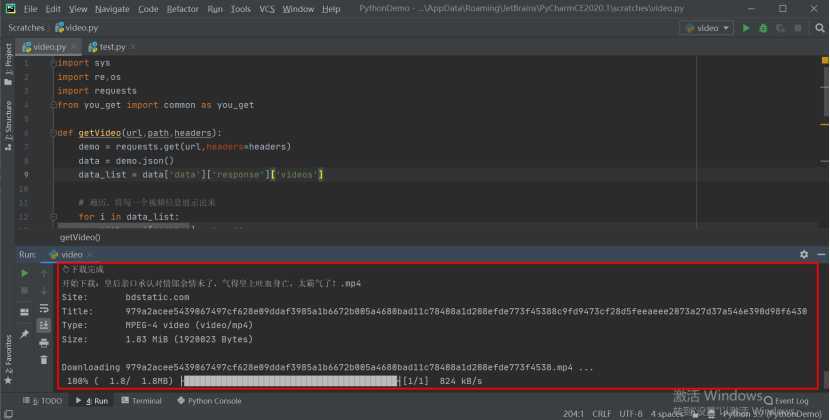
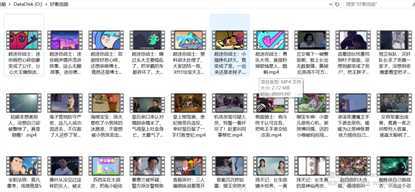
视频展示: 因为爬取的是推荐视频,每次执行会获取不同的视频。
先来介绍一下所用到的库
1、requests库:众所周知,爬虫神器
2、re库:主要用来split的
3、sys和you-get库:主要任务下载视频
4、os库:用来修改文件名
注意:库没安装记得pip install 库名
下边捋一下思路
1、进入好看视频网站—>影视(或者推荐随便哪个分类)—>随便找个视频右击—>检查
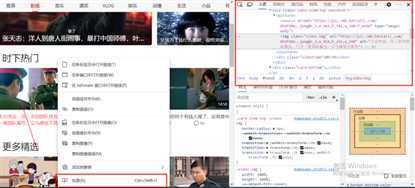
2、选择网络—>XHR—>选择包
获取到当前界面
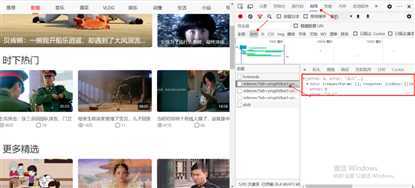
3、展开data—>response—>videos层层扒开
会发现所有的视频id、title都在这里,格式是JSON
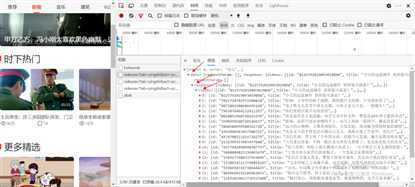
4、再来展开其中一条视频的信息,下边还有,截屏不全,视频所有的信息都在这了
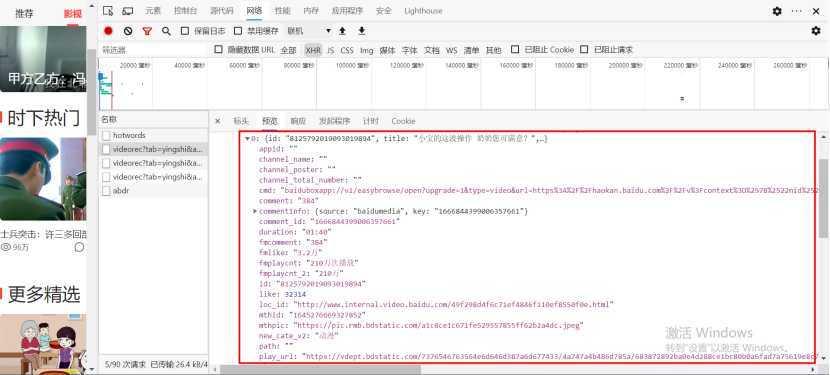
5、我们主要用到的有title、play_url,你会发现,箭头所指的方向还有一个url标签,当你不确定url到底是哪个时,你可以直接复制到浏览器打开查看一下
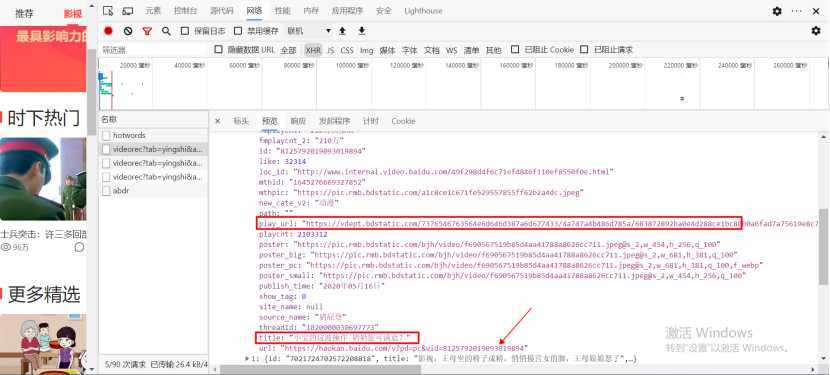
6、到这里,视频的名称和url就已经获取到了,具体的实现过程就看上边的源码吧,基本都有注释
7、这里要简单说一下you-get库,是个非常强大的下载视频库,除了在脚本上应用,也可以直接在cmd中执行,先看下它支持的选项:
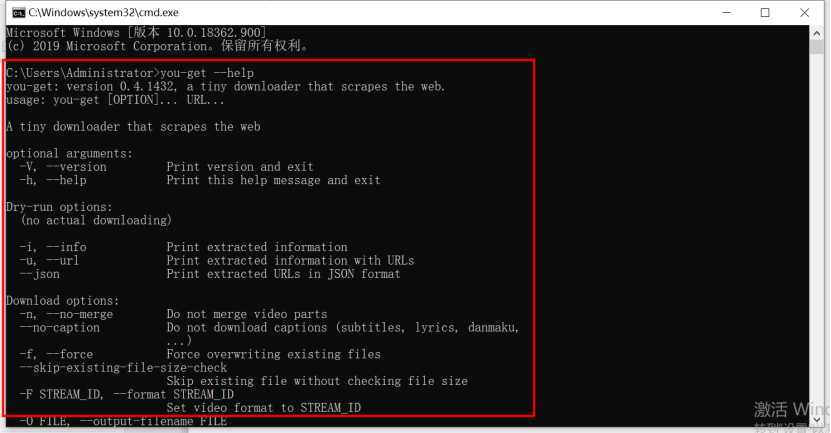
主要用到的有两个,一个是 -o 指定路径,另一个是--debug主要在错误时打印日志
比如随便找个B站视频下载下来:
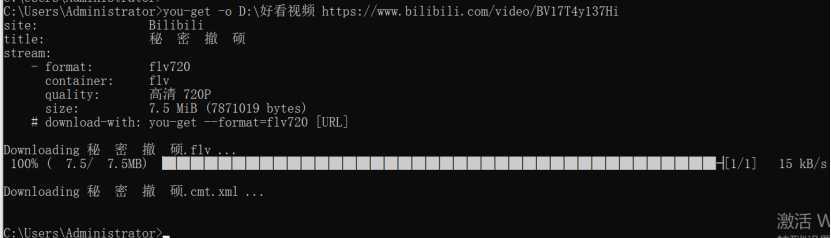
是不是巨方便
原文:https://www.cnblogs.com/v-fan/p/13167805.html