观点:由 4 个元素组成:方面(aspect)、持有者(holder)、观点内容(expression)及情感(sentiment).这四者之间所存在的联系为:观点的持有者针对某一方面发表了具有情感的观点内容。
观点挖掘表示一种对实体及实体方面的观点及态度的挖掘研究。
情感分析是指通过自动分析网络评论的文本内容,挖掘评论用户对这方面的褒贬态度倾向,大部分网络评论情感分析集中于评论的情感极性分析。
常用的观点挖掘流程为:方面挖掘、基于方面的观点内容挖掘、观点情感分析、观点总结。、
观点内容挖掘是指在评论词序列中挖掘出针对不同方面的相应观点子序列,即观点内容。以电影《神奇动物在哪里》的豆瓣影评“这比垃圾奇异博士好看”为例,句中情感词为“垃圾”“好看”,观点内容则可以是“比奇异博士好看”.由此可见,只提取情感词并不能充分反映句子观点。
3个研究方向:文档级观点挖掘、句子级观点挖掘与方面级观点挖掘。
方面是指在一条互联网评论语句中粒度最细的评论对象,即观点词所指向的最小对象。
序列标注问题包括自然语言处理中的分词,词性标注,命名实体识别,关键词抽取,词义角色标注等等。我们只要在做序列标注时给定特定的标签集合,就可以进行序列标注。序列标注问题是NLP中最常见的问题,因为绝大多数NLP问题都可以转化为序列标注问题,虽然很多NLP任务看上去大不相同,但是如果转化为序列标注问题后其实面临的都是同一个问题。
所谓“序列标注”,就是说对于一个一维线性输入序列:
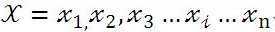
给线性序列中的每个元素打上标签集合中的某个标签:
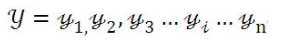
所以,其本质上是对线性序列中每个元素根据上下文内容进行分类的问题。一般情况下,对于NLP任务来说,线性序列就是输入的文本,往往可以把一个汉字看做线性序列的一个元素,而不同任务其标签集合代表的含义可能不太相同,但是相同的问题都是:如何根据汉字的上下文给汉字打上一个合适的标签(无论是分词,还是词性标注,或者是命名实体识别,道理都是想通的)。
序列标注的任务就是给每个汉字打上一个标签,对于分词任务来说,我们可以定义标签集合为(jieba分词中的标签集合也是这样的):
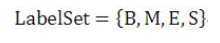
其中B代表这个汉字是词汇的开始字符,M代表这个汉字是词汇的中间字符,E代表这个汉字是词汇的结束字符,而S代表单字词。
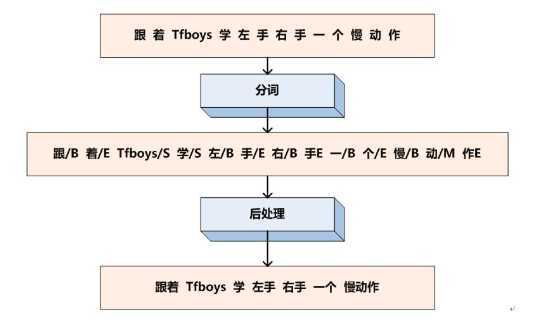
在这里我们可以采用双向LSTM来处理该类问题,双向会关注上下文的信息。在NLP中最直观的处理问题的方式就是要把问题转换为序列标注问题,思考问题的思维方式也就转换为序列标注思维,这个思维很重要,决定你能否真的处理好NLP问题。
命名实体识别任务是识别句子中出现的实体,通常识别人名、地名、机构名这三类实体。
我们要识别出里面包含的人名、地名和机构名。如果以序列标注的角度看这个问题,我们首先得把输入序列看成一个个汉字组成的线性序列,然后我们要定义标签集合,标签集合如下:
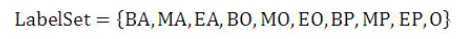
其中,BA代表这个汉字是地址首字,MA代表这个汉字是地址中间字,EA代表这个汉字是地址的尾字;BO代表这个汉字是机构名的首字,MO代表这个汉字是机构名称的中间字,EO代表这个汉字是机构名的尾字;BP代表这个汉字是人名首字,MP代表这个汉字是人名中间字,EP代表这个汉字是人名尾字,而O代表这个汉字不属于命名实体。
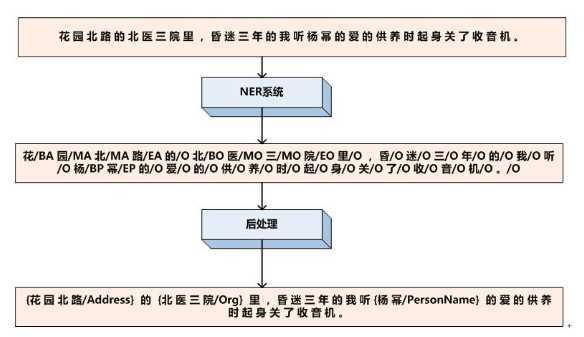
有了输入汉字序列,也有了标签集合,那么剩下的问题是训练出一个序列标注ML系统,能够对每一个汉字进行分类,假设我们已经学好了这个系统,那么就给输入句子中每个汉字打上标签集合中的标签,于是命名实体就被识别出来了,为了便于人查看,增加一个后处理步骤,把人名、地名、机构名都明确标识出来即可。
传统解决序列标注问题的方法包括HMM/MaxEnt/CRF等,很明显RNN很快会取代CRF的主流地位,对于分词、词性标注(POS)、命名实体识别(NER)这种前后依赖不会太远的问题,可以用RNN或者BiRNN处理就可以了。而对于具有长依赖的问题,可以使用LSTM、RLSTM、GRU等来处理。关于GRU和LSTM两者的性能差不多,不过对于样本数量较少时,有限考虑使用GRU(模型结构较LSTM更简单)。此外神经网络在训练的过程中容易过拟合,可以在训练过程中加入Dropout或者L1/L2正则来避免过拟合。

原文:https://www.cnblogs.com/xbsdloo/p/13168764.html