使用线程池的原因
多线程是为了用来最大化发挥多核处理器的处理能力,但是线程是不能无限创建的,当线程创建太多时,反而会消耗CPU与内存资源。
线程的创建与销毁是需要时间的,假如一个线程的创建时间加上销毁时间还要远大于服务时间时,是得不偿失的;线程需要占用内存资源,大量线程的创建会占用宝贵内存资源,可以导致OOM (Out Of Memory)的问题;大量线程的回收会增加GC操作的压力,增加GC的停顿时间;线程抢占CPU资源,会导致CPU在各个线程中进行上下文的切换,这也是一个耗时的过程。多线程的创建不仅是一个耗时,也占用资源的,因此就提出了线程池的解决方法。
线程池
线程池是是事先创建若干个可执行的线程放入一个池(容器)中,有任务需要执行时就从池中获取空闲的线程,任务执行完成后将线程放回池,而不用关闭线程,可以减少创建和销毁线程对象的开销。避免了频繁的创建和销毁线程,让创建的线程达到复用的目的,线程池的内部维护一部分活跃的线程,如果有需要就从线程中取线程使用,用完归还到线程池,当然线程池对线程的数量是有一定的限制。线程池的本质是对线程资源的复用。
其优势是:
部分接口及实现类
Executor是最基础的执行的接口,ExecutorService接口继承了Excutor接口,提供了一些对线程池操作的扩展方法;AbstractExecutorService抽象类实现了ExecutorService接口提供的大部分方法;
ThreadPoolExecutor继承自AbstractExecutorService,部分方法的具体实现;
ScheduledExecutorService接口继承了ExecutorService接口,提供了”周期执行“的功能;
ScheduledThreadPoolExecutor既继承了TheadPoolExecutor线程池,也实现了ScheduledExecutorService接口,是带“周期执行“功能的线程池;
Executors是线程池的静态工厂,其提供了快捷创建线程池的静态方法。
ThreadPoolExecutor类
构造函数
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) {...}
corePoolSize:核心的线程数。当我们提交一个任务时会创建一个新的线程执行,直到线程数等于corePoolSize,如果当前的线程数等于corePoolSize时,继续提交任务会被保存到阻塞队列中,等待被执行
maximumPoolSize:线程池允许的最大的线程的数量。
keepAliveTime:空闲线程的存活时间。默认情况下只有当线程数量大小corePoolSize时才有效。
unit:keepAliveTime的时间单位。
workQueue:等待队列,队列必须是BlockingQueue阻塞队列,被提交但尚未被执行的任务(线程数量大于corePoolSize)
排队的策略:
不排队,直接提交:SynchronoursQueue
无界队列:LinkedBlockingQueue
有界队列:ArrayBlockingQueue
threadFactory:线程工厂,用于创建线程。使用默认的线程工厂或者自定义线程工厂,自定义实现(实现ThreadFactory),要提供给线程创建时设置一个具有识别度的线程名(默认的线程工厂:DefaultThreadFactory 线程的命名规则:“Pool- 数字-thread-数字”)
handler:线程池的饱和策略。由于任务过多或其他原因导致的线程池无法处理时的任务拒绝策略。
线程池在JDK内置的四种拒绝策略:
除此以外,还可以自定义拒绝策略,实现RejectedExecutionHandler接口,捕获异常来实现自定义拒绝策略。
执行过程
如图
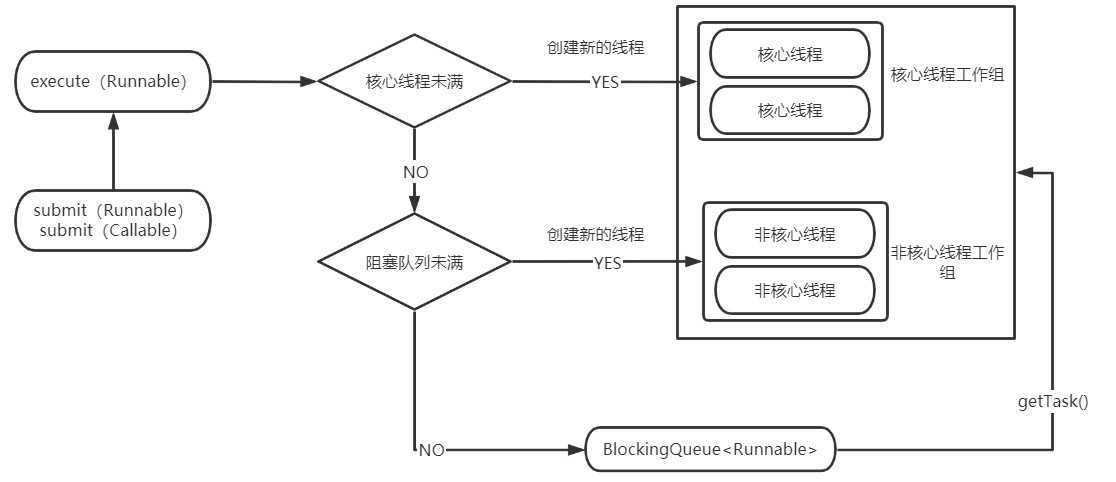
线程池在被创建时,只是向系统申请一个用于执行线程队列和管理线程池的线程资源。在调用execute()添加一个任务时,线程池才会进行一系列操作。
原文:https://www.cnblogs.com/128-cdy/p/13170892.html