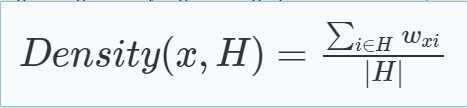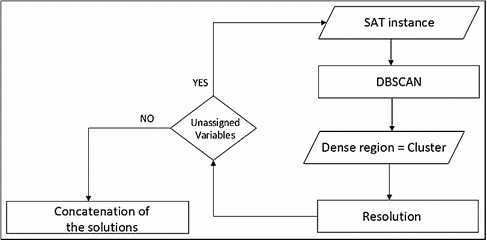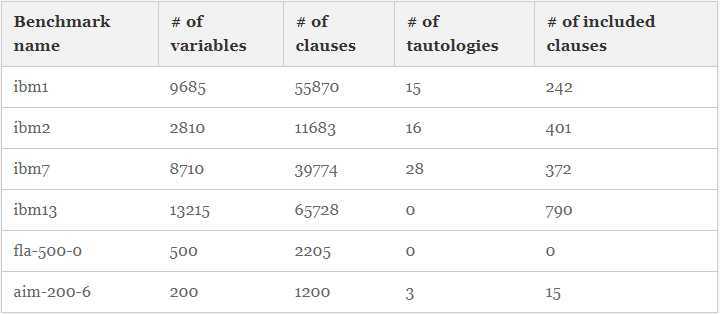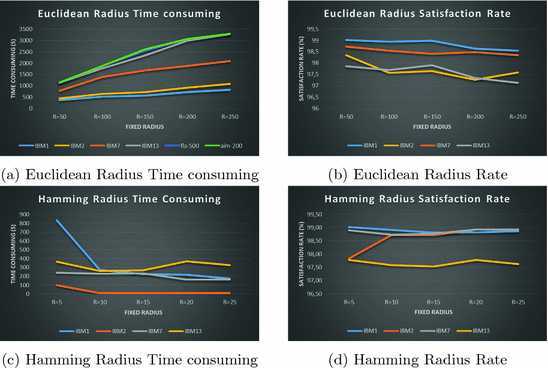
3.1 SAT and Its Solvers Categories
| Being the first problem to be shown as NP-complete [2], SAT is considered as the backbone of all research in problems solving domain. |
| Several approaches have been developed to overcome this problem. Complete algorithms are able to return the satisfying solution if it exists or prove that no solution exists. One of the fundamental and most used algorithms is the Davis-Putnam-Logemann-Loveland (DPLL) [3], which is a backtracking algorithm that assigns a truth value to a chosen variable, eliminating all the clauses satisfied by this assignment and purging removing- the later variable from the unsatisfied clauses containing it. |
| In the other hand, the incomplete solvers, and especially the metaheuristics [9], try to approximate the most until finding the best possible solution to the problem global optimum- according to a certain criteria of satisfaction, using a fitness function to evaluate the proposed solution at each iteration. |
| 译文:另一方面,不完备求解器,特别是元启发式[9],试图最大程度地逼近问题,直到找到问题的全局最优的可能的最佳解——根据一定的满足标准,使用适应度函数在每次迭代中评估建议的解。 |
| The most used category of solvers for SAT is the bio-inspired algorithms(仿生算法), which attempt to reproduce some biological and natural functioning. Such as the Bees Swarm Optimization algorithm (BSO,蜜蜂群优化算法) [6]. In fact when looking for food, bees communicate with each other through a dance indicating the distance that separate the bee from the food’s source [12]. |
|
译文:最常用的SAT解决方案是仿生算法(仿生算法),试图复制一些生物和自然功能。译文:比如蜜蜂群优化算法(BSO)。 译文:事实上,在寻找食物的时候,蜜蜂会通过舞蹈来相互交流,以此来表明蜜蜂与食物来源[12]之间的距离。 |
| The Bees Swarm Optimization BSO- works as follows; A bee named BeeInit generates a random solution called Sref (reference solution). A search area is determined from the later solution. Each solution of this search area is considered as a starting point to the local search made by each bee. At the end of the local search, each bee returns its best solution in a table named Dance, the best solution from the Dances table is taken as Sref and the process restarts until a certain stop criteria. |