Django中前端向后端传参的方式主要有以下几种情况:
但是以上几种情况在Django中又是怎么做的呢?
我们还是使用之前定义的类视图:
from django.http import HttpResponse from django.views import View class IndexPage(View): ‘‘‘ 类视图 ‘‘‘ def get(self, request): return HttpResponse("<p>这是一个get请求</p>") def post(self, request): return HttpResponse("<p>这是一个post请求</p>") def delete(self, request): return HttpResponse("<p>这是一个delete请求</p>")
路由定义如下:
from django.contrib import admin from django.urls import path from projects.views import IndexPage urlpatterns = [ path(‘admin/‘, admin.site.urls), path(‘index/‘, IndexPage.as_view()) ]
以postman请求来做演示,查询字符串一般用在get请求中,也有一些会用在post请求的params中,假设有两个字段,name=‘xiaogongjin‘, ‘age‘=18,我们在代码的对应视图上打上断点后发送请求
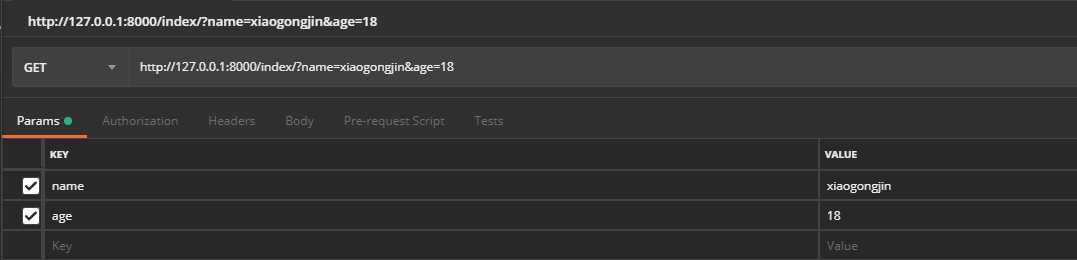
通过pycharm断点计算器,可以通过如下方式获取到传入的字段,传入的字段数据类型为“QureyDict”,可以类比于python的字典数据类型
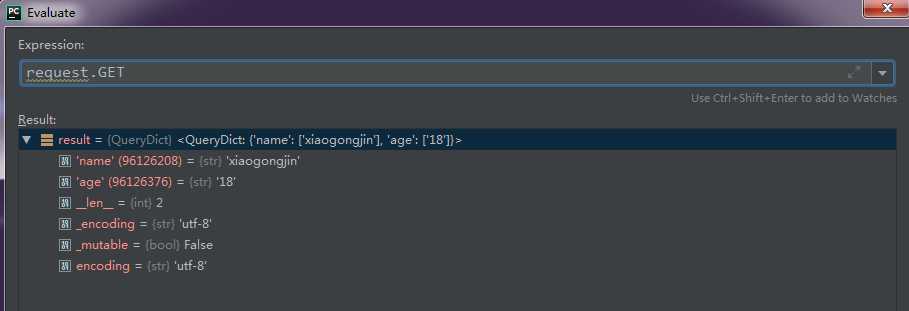
如果要知道request.GET支持哪些方法去操作,可以使用dir()方法去查看:
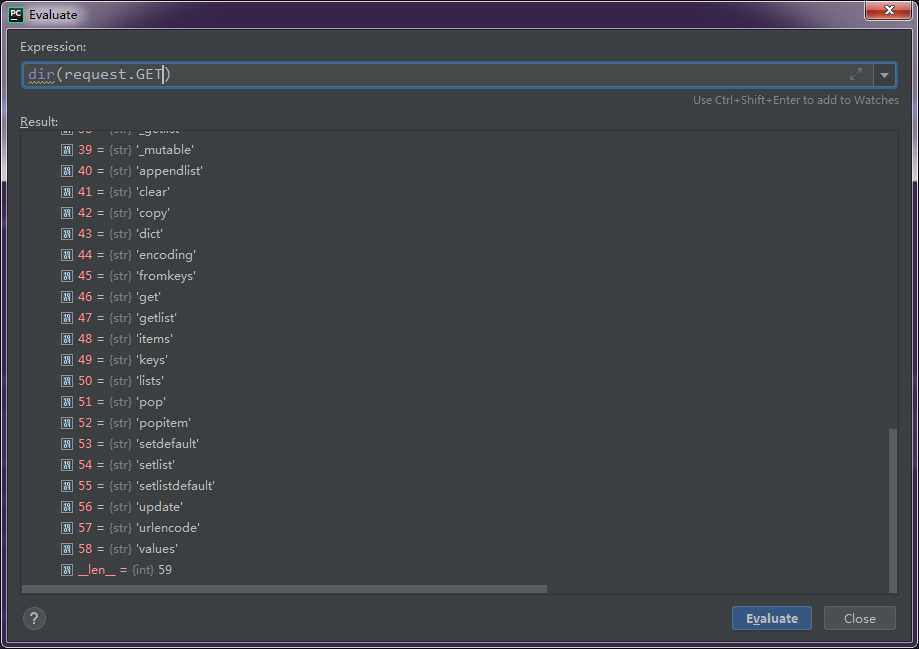
如果我们要获取name字段的值,则可以使用request.GET.get(‘name‘),拿到值后就可以在类视图对应的get方法里进行逻辑控制了,这里就不举例了。
有时候如果查询字符串中传入多个一样的属性名,而值却不同,比如:http://127.0.0.1:8000/index/?name=xiaogongjin&name=xiaohua,这时候可以使用request.GET.getlist(‘name‘),它返回一个list
这里依然使用postman做演示,form一般都是用于post请求的body里,Content-Type为application/x-www-form-urlencoded,同样假设有两个字段,name=‘xiaogongjin‘, ‘age‘=18,我们在代码的对应视图上打上断点后发送请求
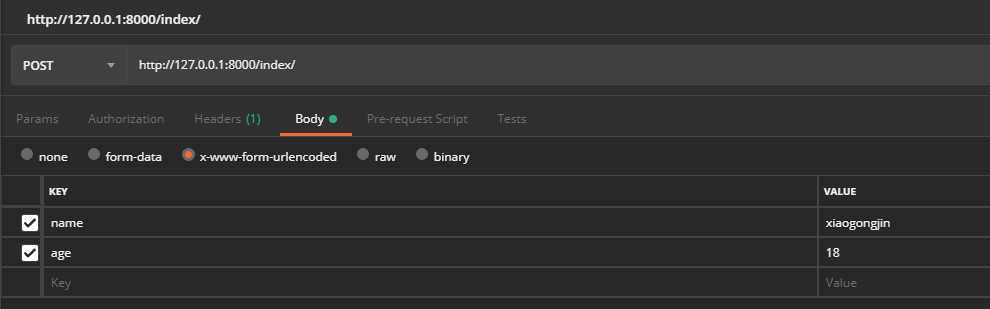
通过pycharm断点计算器,可以通过如下方式获取到传入的字段,传入的字段数据类型也为“QureyDict”
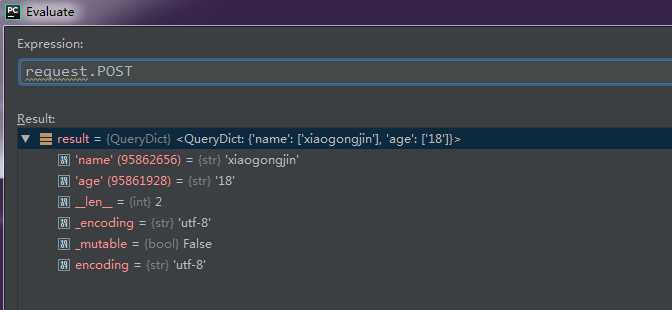
那么获取方法跟查询字符串一致
这里依然使用postman做演示,json格式数据一般也是用于post请求的body里,Content-Type为application/json,同样假设有两个字段,name=‘xiaogongjin‘, ‘age‘=18,我们在代码的对应视图上打上断点后发送请求
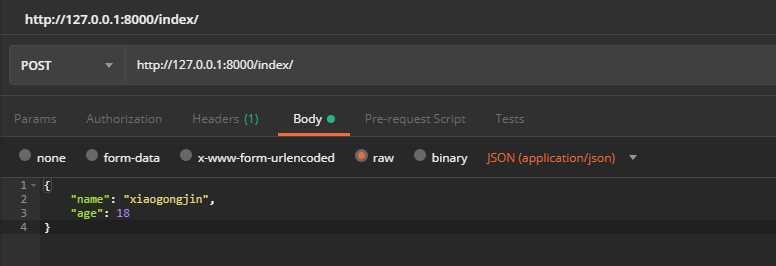
通过pycharm断点计算器,可以通过如下方式获取到传入的字段,传入的字段数据类型为“bytes”,为json格式数据
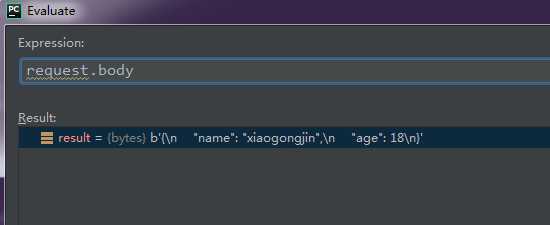
这里依然使用postman做演示,这里使用的post请求方式,上传文件选择binary,我们在代码的对应视图上打上断点后发送请求
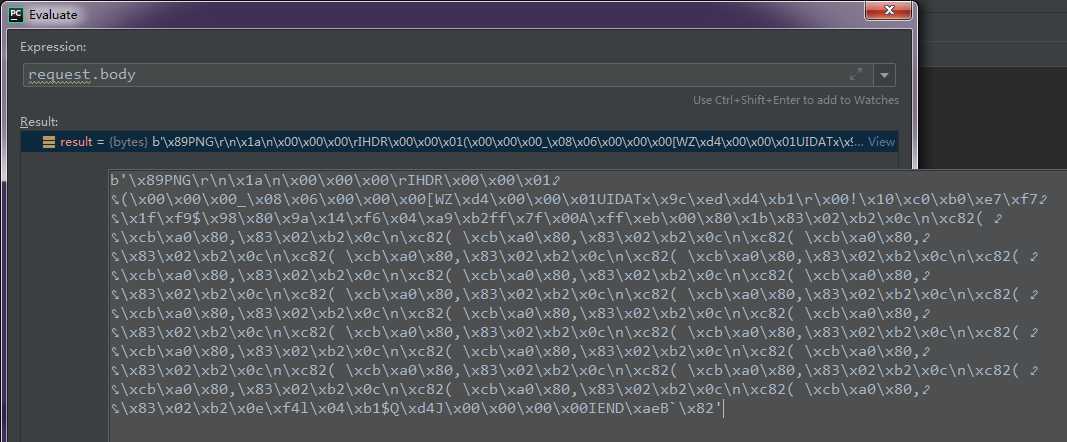
通过pycharm断点计算器,可以通过如下方式获取到传入的字段,传入的字段数据类型也为“bytes”,可以通过上下文管理器去读写二进制文件内容
这里依然使用postman做演示,使用的get请求方式,假设header里面传入Authorization=xxxx,我们在代码的对应视图上打上断点后发送请求
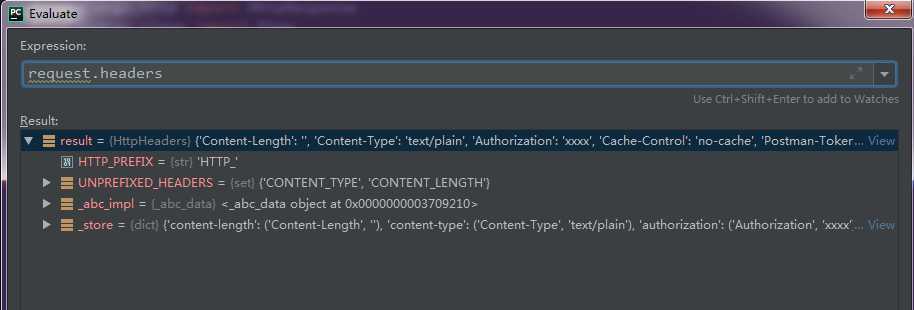
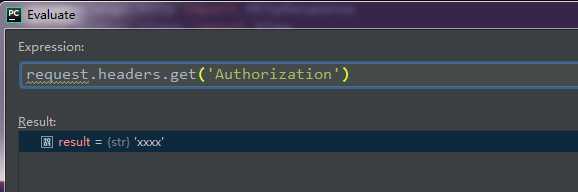
通过pycharm断点计算器,可以通过request.headers获取到所有请求头的相关信息,并且它传入的数据类型为“HttpHeaders”,也可以类比为python的字典数据类型
要获取刚刚自定义的请求头信息,则可以使用request.headers.get(‘Authorization‘)方法
这种类型的请求,只在url路径中传入的参数,比如传入的一些id值,这些值一般都是动态的,在Django中,这种类型的请求处理方法跟上面几种截然不同,我们一般在路由表中进行正则匹配
urlpatterns = [ path(‘admin/‘, admin.site.urls), path(‘index/<int:pk>/‘, IndexPage.as_view()) ]
同样视图方法也要定义第二个形参用于接收pk
依然以postman示例:
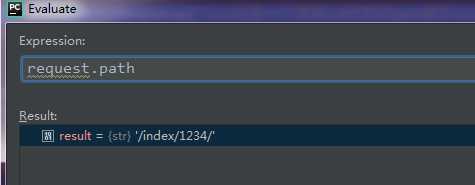
通过pycharm断点计算器,就能够获取到
Django中后端向前端响应,使用的是HttpResponse对象,它继承HttpResponseBase类,我们通过它们的部分源码可以看到传参的方式:
class HttpResponse(HttpResponseBase): """ An HTTP response class with a string as content. This content that can be read, appended to, or replaced. """ streaming = False def __init__(self, content=b‘‘, *args, **kwargs): super().__init__(*args, **kwargs) # Content is a bytestring. See the `content` property methods. self.content = content
class HttpResponseBase: """ An HTTP response base class with dictionary-accessed headers. This class doesn‘t handle content. It should not be used directly. Use the HttpResponse and StreamingHttpResponse subclasses instead. """ status_code = 200 def __init__(self, content_type=None, status=None, reason=None, charset=None): # _headers is a mapping of the lowercase name to the original case of # the header (required for working with legacy systems) and the header # value. Both the name of the header and its value are ASCII strings. self._headers = {} self._resource_closers = [] # This parameter is set by the handler. It‘s necessary to preserve the # historical behavior of request_finished. self._handler_class = None self.cookies = SimpleCookie() self.closed = False if status is not None: try: self.status_code = int(status) except (ValueError, TypeError): raise TypeError(‘HTTP status code must be an integer.‘) if not 100 <= self.status_code <= 599: raise ValueError(‘HTTP status code must be an integer from 100 to 599.‘) self._reason_phrase = reason self._charset = charset if content_type is None: content_type = ‘text/html; charset=%s‘ % self.charset self[‘Content-Type‘] = content_type
原文:https://www.cnblogs.com/xiaogongjin/p/13172697.html