shell介绍+ shell中的变量 +shell中的循环和判断+ shell中的字符串操作+ shell扩展 +awk命令 +sed命令
Shell是用户与Linux操作系统沟通的桥梁
Linux的Shell种类众多,这里我们学习的是bash,也就是Bourne Again
1:由于易用和免费,Bash在日常工作中被广泛使用
2:Bash是大多数Linux系统默认的Shell
文件名后缀通常是.sh
#!/bin/bash
#这里是注释
在一般情况下,人们并不区分 Bourne Shell和Bourne Again Shell,所以,在这里,我们可能看到#!/bin/bash,它同样也可以改为#!/bin/sh。
a.sh 这样的话需要保证脚本具有执行权限并且在环境变量PATH中有(.),这样在执行的时候会先从当前目录查找
./a.sh 只要保证这个脚本具有执行权限即可
/usr/local/a.sh 只要保证这个脚本具有执行权限即可
bash a.sh 直接可以执行,甚至这个脚本文件中的第一行都可以不引入/bin/bash,它是将hello.sh作为参数传给bash命令来执行的
bash的单步执行 bash -x /path/to/aa.sh
bash语法检查 bash -n /path/to/aa.sh
变量不需要声明,初始化不需要指定类型
变量命名
1:只能使用数字,字母和下划线,且不能以数字开头
2:变量名区分大小写
3:建议命名要通俗易懂 注意:变量赋值是通过等号(=)进行赋值,在变量、等号和值之间不能出现空格。
显示变量值使用echo命令(类似于java中的system.out) ,加上$变量名,也可以使用${变量名}
例如:echo $JAVA_HOME 或者echo ${JAVA_HOME}
本地变量 环境变量 位置变量 特殊变量
1.本地变量
只对当前shell进程有效,对当前进程的子进程和其它shell进程无效。
定义:VAR_NAME=VALUE
变量引用:${VAR_NAME}
取消变量:unset VAR_NAME
相当于java中的私有变量(private),只能当前类使用,子类和其他类都无法使用。
2.环境变量
自定义的环境变量对当前shell进程及其子shell进程有效,对其它的shell进程无效
定义:export VAR_NAME=VALUE
对所有shell进程都有效需要配置到配置文件中
vi /etc/profile
source /etc/profile
相当于java中的protected修饰符,对当前类,子孙类,以及同一个包下面可以共用。
和windows中的环境变量比较类似
3.位置变量
$1,$2,.....$10....
test.sh 3 89
$0:脚本自身
$1:脚本的第一个参数
$2:脚本的第二个参数
相当于java中main函数中的args参数,可以获取外部参数。
4.特殊变量
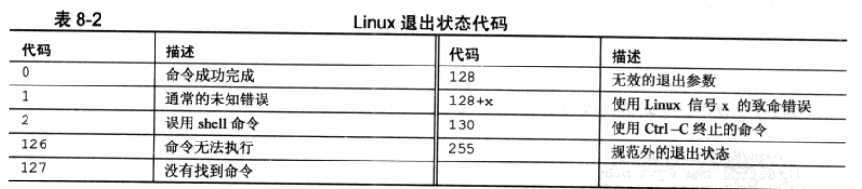
$?:接收上一条命令的返回状态码
返回状态码在0-255之间
$#:参数个数 $*:或者$@:所有的参数
$$:获取当前shell脚本的进程号(PID)(可以实现脚本自杀)(或者使用exit命令直接退出也可以 exit [num])
‘‘单引号不解析变量 echo ‘$JAVA_HOME‘
""双引号会解析变量 echo "$JAVA_HOME"
``反引号是执行并引用一个命令的执行结果,类似于$(...) echo `$JAVA_HOME`
注意下面这两种情况:
echo ‘ "$JAVA_HOME" ‘ echo " ‘$JAVA_HOME‘ "
通过使用一个变量去遍历给定列表中的每个元素,在每次变量赋值时执行一次循环体,直至赋值完成所有元素退出循环
格式1
for ((i=0;i<10;i++))
do
...
done
格式2
for i in 0 1 2 3 4 5 6 7 8 9
do
...
done
格式三
for i in {0..9}
do
...
Done
bash条件测试
格式:
test EXPR
[ EXPR ]:注意中括号和表达式之间的空格
整型测试:
-gt:大于:例如[ $num1 -gt $num2 ]或者test $num1 -gt $num2
-lt:小于
-ge:大于等于
-le:小于等于
-eq:等于
-ne:不等于
字符串测试:
=:等于,例如判断变量是否为空 [ "$str" = "" ] 或者[ -z $str ]
!=:不等于
适用于循环次数未知,或不便用for直接生成较大的列表时
格式:
while 测试条件
do
循环体
done
如果测试条件为“真”,则进入循环,测试条件为假,则退出循环。
单分支
if 测试条件;then
选择分支
fi
双分支
if 测试条件
then
选择分支1
else
选择分支2
fi
多分支
if 条件1; then
分支1
elif 条件2; then
分支2
elif 条件3; then
分支3
...
else
分支n
Fi
获取长度:${#VAR_NAME}
字符串截取
${variable:offset:length}或者${variable:offset}
字符串替换
${variable/substr/replace}
${variable//substr/replace}
取尾部的指定个数的字符
${variable: -length}:注意冒号后面有空格
大小写转换
小-->大:${variable^^}
大-->小:${variable,,}
let varName=算术表达式
varName=$[算术表达式]
varName=$((算术表达式))
显示当前时间
格式化输出 +%Y-%m-%d
格式%s表示自1970-01-01 00:00:00以来的秒数
指定时间输出 --date=‘2009-01-01 11:11:11‘
指定时间输出 --date=‘3 days ago‘ 或者 -d ‘3 days ago‘
高级用法:获取指定日期的前一天
date -d ‘20180101 1 days ago‘ +%Y-%m-%d
read命令接收标准输入(键盘)的输入,或者其他文件描述符的输入。得到输入后,read命令将数据放入一个标准变量中。
格式
read VAR_NAME
read如果后面不指定变量,那么read命令会将接收到的数据放置在环境变量REPLY中
read -p "Enter your name:" VAR_NAME
read -t 5 -p "enter your name:" VAR_NAME
read -s -p "Enter your password: " pass
在脚本后面加一个&
test.sh &
这样的话虽然可以在后台运行,但是当用户注销(logout)或者网络断开时,终端会收到Linux HUP信号(hangup)信号从而关闭其所有子进程
nohup命令
不挂断的运行命令,忽略所有挂断(hangup)信号
使用nohup test.sh &
nohup会忽略进程的hangup挂断信号,所以关闭当前会话窗口不会停止这个进程的执行。
nohup会在当前执行的目录生成一个nohup.out日志文件
标准输入、输出、错误可以使用文件描述符0、1、2引用
使用重定向可以把信息重定向到其他位置
ls >file 或者 ls 1>file(ls >>file)
lk 2>file(lk是一个错误命令)
ls >file 2>&1
ls > /dev/null(把输出信息重定向到无底洞)
例子:nohup command >/dev/null 2>&1 &
linux下的定时任务
编辑 vi /etc/crontab
查看crontab执行日志
tail -f /var/log/cron
必须打开rsyslog服务cron文件中才会有执行日志(service rsyslog status)
查看cron服务状态
service crond status
启动cron服务
service crond start
问题:如果设置每5分钟执行一次的crontab,那么这个脚本分别会在什么时间执行?
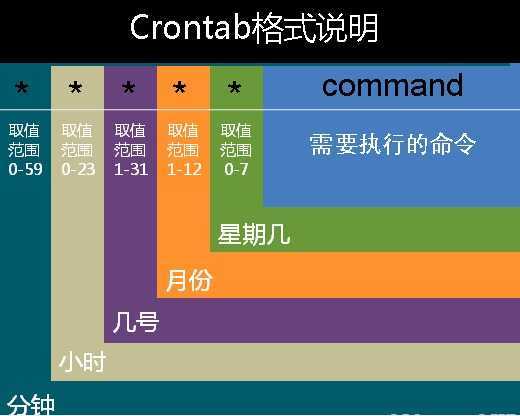
需求:每天凌晨一点实现一次练习一的功能
00 01 * * * root /bin/bash /usr/local/shell_04/for3.sh
分钟 小时 几号 月份 星期几 command
ps:用来显示进程的相关信息
ps显示当前启动的所有进程
ps -e显示系统中所有进程
ps -ef|grep java
jps:类似linux的ps命令,不同的是ps是用来显示所有进程,而jps只显示java进程,准确的说是显示当前用户已启动的部分java进程信息,信息包括进程号和简短的进程command。
查找字符串
/string
查找下一个,按“n”即可
查找某一行
:10(直接跳转到第10行)
复制粘贴
yy(复制当前行)
2 yy(从当前行开始,复制2行)
p(粘贴)
删除
dd(删除当前行)
999dd(删除当前行及下面所有行)
跳到文件最后一行
G
调到文件第一行
gg
ctrl+s会造成终端假死,什么都无法输入,这个命令是linux中一个比较古老的命令
ctrl+q退出假死状态
awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
awk有3个不同版本: awk、nawk和gawk,未作特别说明,一般指gawk。
现在一般所说的awk就是gawk
awk程序的报告生成能力通常用来从大文本文件中提取数据元素并将它们格式化成可读的报告。最完美的例子是格式化日志文件。awk程序允许从日志文件中只过滤出你想要看的数据
命令格式
awk [options] program file
options :选项
program :程序
file:文件(需要处理的数据文件)
选项 描述
-F fs 指定行中分隔数据字段的字段分隔符
-f file 指定程序脚本文件
awk的基本特性之一就是它处理文本文件中数据的能力。它会自动给每行中的每个数据元素分配一个变量。
$0代表整个文本行
$1代表文本行中的第1个数据字段
$2代表文本行中的第2个数据字段
$n代表文本行中的第n个数据字段
注意:每个数据字段在文本行中都是通过字段分隔符来划分的。awk中的默认字段分隔符是任意的空白字符(例如空格或制表符)
如果想要读取使用其他字段分隔符的文件,可以使用-F 选项指定:awk -F: ‘{print $1}‘ /etc/passwd
如果某编程语言一次只能执行一条命令,那么它不会有太大用处。awk编程语言允许你将多条命令组成一个正常的程序。在这我们可以把这些命令保存到一个文件中,这个文件我们就称为是awk的脚本文件。
格式:只要将每条命令放到一个新的行就好了,不需要用分号。
awk -F: -f script /etc/passwd
这里的script是一个文件,需要使用-f参数指定
BEGIN:有时可能需要在处理数据前运行脚本,比如为报告创建开头部分。
END:跟BEGIN关键字类似,END关键字允许你指定一个程序脚本,awk会在读完数据后执行它。
FS:Field Seperator, 输入时的字段分隔符
awk ‘BEGIN{FS=":"}{print $1,$7}‘ /etc/passwd
RS:Record Seperator, 输入行分隔符
OFS: Output Field Seperator, 输出时的字段分隔符;
ORS: Outpput Row Seperator, 输出时的行分隔符;
NF:Numbers of Field,字段数量
NR:Numbers of Record, 行号;所有文件的一并计数;
FNR:行号;各文件分别计数;
正则表达式需要放在/expr/中,/expr/必须出现在它要控制的程序脚本的左花括号前。
awk ‘/110.52.250.126/ {print $1}‘ access_2013_05_30.log
匹配操作符允许将正则表达式限定在数据行中的特定数据字段。
awk ‘ ($1 ~ /110.52.250.126/) {print $1}‘ access_2013_05_30.log
awk ‘ ($1 !~ /110.52.250.126/) {print $1}‘ access_2013_05_30.log
针对ngix中的access访问日志进行分析,主要统计pv,uv等
扩展
shell中的管道|
command 1 | command 2:他的功能是把第一个命令command 1执行的结果作为command 2的输入传给command 2
wc -l
统计行数
uniq -c
在输出行前面加上每行在输入文件中出现的次数
uniq -u
仅显示不重复的行
sort -nr
-n:依照数值的大小排序
-r:以相反的顺序来排序
-k:按照哪一列进行排序
head -3
取前三名
1.Sed -i ‘s/aaa/bbb/g‘ test.conf
-i 表示直接修改文档内容
s 表示用一个字符串替换另一个
aaa 表示需要替换的源字符串
bbb 表示需要替换的目的字符串
g 表示对文件内的所有匹配数据进行替换
原文:https://www.cnblogs.com/gl0102/p/13174583.html