美国语言协会对美国人日常使用的英语单词做了一份详细的统计,按照日常使用的频率做成了一张表,称为COCA词频表。排名越低的单词使用频率越高,该表可以用来统计词汇量。
如果你的词汇量约为6000,那么这张表频率6000以下的单词你应该基本都认识。(不过国内教育平时学的单词未必就是他们常用的,只能说大部分重合)

我一直有个想法,要是能用COCA词频表统计一本小说中所有的词汇都是什么等级的,然后根据自己的词汇量,就能大致确定这本小说是什么难度,自己能不能读了。
学习了C++的容器和标准库算法后,我发现这个想法很容易实现,于是写了个能够统计文本词频的小工具。现在只实现了基本功能,写得比较糙。还有很多要改进的地方,随着以后的学习,感觉这个工具还是可以再深挖的。
v0.1
1.可逐个分析文本中的每一个单词并得到其COCA词频,生成统计报告。
2.使用乔布斯斯坦福大学演讲稿(2200+词)测试,处理时间约为1000-1100+ms。
2.仅支持txt,且文本中不能有奇怪的符号。支持字母,空格和一般的语句符号,但破折号,单位符号还不能处理。
实现的重点就两块。
(1)COCA词典的建立
首先建立出COCA词典。我使用了恶魔的奶爸公众号提供的txt格式的COCA词频表,这张表是经过处理的,每行只有一个单词和对应的频率,所以读取起来很方便。
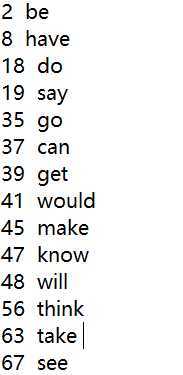
读取文本后,用map容器来建立“单词——频率”的一对一映射。
要注意的是有些单词因为使用意思和词性的不同,统计表里会出现两个频率,也就是熟词的偏僻意思。我只取了较低的那个为准,因为你读文本时,虽然可能不是真正的意思但起码这个单词是认识的,而且这种情况总体来说比较少见,所以影响不大。
存储时我用了26组map,一个首字母存一组,到时候查询时按首字母查找。可能有更有效率的办法。
(2)单词的获取和处理
使用get()方法逐个获取文本的字符。
使用vector容器存储读到的文本内容。如果是字母或连字符就push进去,如果不是,就意味着一个单词读完了,接着开始处理,把读到的文本内容assign到一个字符串中组成完整的单词,然后根据其首字母查找词频。
每个单词查到词频后,使用自定义的frequency_classify()区分它在什么范围,再用word_frequency_analyze()统计在不同等级的分布。
最后报告结果,显示出每个等级的百分比。
用了乔布斯斯坦福大学的演讲稿来测试。写完代码时发现不能处理里面的破折号= =,手动把破折号先换成了冒号。
测试结果:
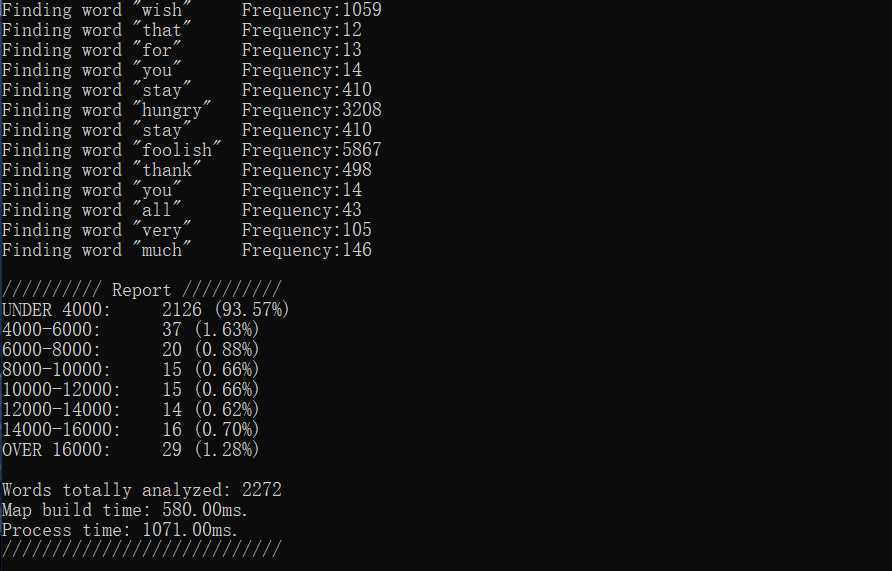
总共分析了2272个单词,93.57%的单词分布在4000以下,可见演讲稿使用的绝大多数的单词都是极其常用的单词,有4000以上的词汇量就基本能读懂。
以下是代码。
TextVolcabularyAnalyzer.cpp
#include <iostream> #include <fstream> #include <string> #include <algorithm> #include <array> #include <vector> #include <iterator> #include <map> #include <numeric> #include <iomanip> #include <ctime> #define COCA_WORDS_NUM 20201U #define WORDS_HEAD_NUM 26U #define WORDS_HEAD_A 0U #define WORDS_HEAD_B 1U #define WORDS_HEAD_C 2U #define WORDS_HEAD_D 3U #define WORDS_HEAD_E 4U #define WORDS_HEAD_F 5U #define WORDS_HEAD_G 6U #define WORDS_HEAD_H 7U #define WORDS_HEAD_I 8U #define WORDS_HEAD_J 9U #define WORDS_HEAD_K 10U #define WORDS_HEAD_L 11U #define WORDS_HEAD_M 12U #define WORDS_HEAD_N 13U #define WORDS_HEAD_O 14U #define WORDS_HEAD_P 15U #define WORDS_HEAD_Q 16U #define WORDS_HEAD_R 17U #define WORDS_HEAD_S 18U #define WORDS_HEAD_T 19U #define WORDS_HEAD_U 20U #define WORDS_HEAD_V 21U #define WORDS_HEAD_W 22U #define WORDS_HEAD_X 23U #define WORDS_HEAD_Y 24U #define WORDS_HEAD_Z 25U using namespace std; typedef enum WordFrequencyType { WORD_UNDER_4000 = 0, WORD_4000_6000, WORD_6000_8000, WORD_8000_10000, WORD_10000_12000, WORD_12000_14000, WORD_14000_16000, WORD_OVER_16000, WORD_LEVEL_NUM }TagWordFrequencyType; const string alphabet_str = "abcdefghijklmnopqrstuvwxyz"; const string report_str[WORD_LEVEL_NUM] = { "UNDER 4000: ", "4000-6000: ", "6000-8000: ", "8000-10000: ", "10000-12000: ", "12000-14000: ", "14000-16000: ", "OVER 16000: " }; TagWordFrequencyType frequency_classify(int wfrq) { if (wfrq <= 4000) { return WORD_UNDER_4000; } else if (wfrq > 4000 && wfrq <= 6000) { return WORD_4000_6000; } else if (wfrq > 6000 && wfrq <= 8000) { return WORD_6000_8000; } else if (wfrq > 8000 && wfrq <= 10000) { return WORD_8000_10000; } else if (wfrq > 10000 && wfrq <= 12000) { return WORD_10000_12000; } else if (wfrq > 12000 && wfrq <= 14000) { return WORD_12000_14000; } else if (wfrq > 14000 && wfrq <= 16000) { return WORD_14000_16000; } else { return WORD_OVER_16000; } } void word_frequency_analyze(array<int, WORD_LEVEL_NUM> & wfrq_array, TagWordFrequencyType wfrq_tag) { switch (wfrq_tag) { case WORD_UNDER_4000: { wfrq_array[WORD_UNDER_4000] += 1; break; } case WORD_4000_6000: { wfrq_array[WORD_4000_6000] += 1; break; } case WORD_6000_8000: { wfrq_array[WORD_6000_8000] += 1; break; } case WORD_8000_10000: { wfrq_array[WORD_8000_10000] += 1; break; } case WORD_10000_12000: { wfrq_array[WORD_10000_12000] += 1; break; } case WORD_12000_14000: { wfrq_array[WORD_12000_14000] += 1; break; } case WORD_14000_16000: { wfrq_array[WORD_14000_16000] += 1; break; } case WORD_OVER_16000: { wfrq_array[WORD_OVER_16000] += 1; break; } default: { break; } } } int main() { //file init ifstream COCA_txt("D:\\COCA.txt"); ifstream USER_txt("D:\\JobsSpeech.txt"); //time init clock_t startTime, endTime; double build_map_time = 0; double process_time = 0; startTime = clock(); //build time start //build COCA words map map<string, int> COCA_WordsList[WORDS_HEAD_NUM]; int readlines = 0; while (readlines < COCA_WORDS_NUM) { int frequency = 0; string word = ""; COCA_txt >> frequency; COCA_txt >> word; //transform to lower uniformly transform(word.begin(), word.end(), word.begin(), tolower); //import every word for (int whead = WORDS_HEAD_A; whead < WORDS_HEAD_NUM; whead++) { //check word head if (word[0] == alphabet_str[whead]) { //if a word already exists, only load its lower frequency if (COCA_WordsList[whead].find(word) == COCA_WordsList[whead].end()) { COCA_WordsList[whead].insert(make_pair(word, frequency)); } else { COCA_WordsList[whead][word] = frequency < COCA_WordsList[whead][word] ? frequency : COCA_WordsList[whead][word]; } } } readlines++; } endTime = clock(); //build time stop build_map_time = (double)(endTime - startTime) / CLOCKS_PER_SEC; //user prompt cout << "COCA words list imported.\nPress any key to start frequency analysis...\n"; cin.get(); startTime = clock(); //process time start //find text words vector<char> content_read; string word_readed; array<int, WORD_LEVEL_NUM> words_analysis_array{ 0 }; char char_read = ‘ ‘; //get text char one by one while (USER_txt.get(char_read)) { //only letters and ‘-‘ between letters will be received if (isalpha(char_read) || char_read == ‘-‘) { content_read.push_back(char_read); } else { //a char which is not a letter usually marks end of one word if (!content_read.empty()) { int current_word_frequency = 0; //assign letters to make the word word_readed.assign(content_read.begin(), content_read.end()); transform(word_readed.begin(), word_readed.end(), word_readed.begin(), tolower); cout << "Finding word \"" << word_readed << "\" \t"; cout << "Frequency:"; //check the word‘s head and find its frequency in COCA list for (int whead = WORDS_HEAD_A; whead < WORDS_HEAD_NUM; whead++) { if (word_readed[0] == alphabet_str[whead]) { cout << COCA_WordsList[whead][word_readed]; current_word_frequency = COCA_WordsList[whead][word_readed]; } } cout << endl; //classify this word and make statistics word_frequency_analyze(words_analysis_array, frequency_classify(current_word_frequency)); content_read.clear(); } } } endTime = clock(); //process time stop process_time = (double)(endTime - startTime) / CLOCKS_PER_SEC; //calc whole words processed int whole_words_analyzed = 0; whole_words_analyzed = accumulate(words_analysis_array.begin(), words_analysis_array.end(), 0); //report result cout << "\n////////// Report ////////// \n"; for (int i = 0;i< words_analysis_array.size();i++) { cout << report_str[i] <<"\t"<< words_analysis_array[i] << " ("; cout<<fixed<<setprecision(2)<<(float)words_analysis_array[i] * 100 / whole_words_analyzed << "%)" << endl; } cout << "\nWords totally analyzed: " << whole_words_analyzed << endl; //show run time cout << "Map build time: " << build_map_time*1000 << "ms.\n"; cout << "Process time: " << process_time*1000 << "ms.\n"; cout << "////////////////////////////" << endl; return 0; }
原文:https://www.cnblogs.com/banmei-brandy/p/13177762.html