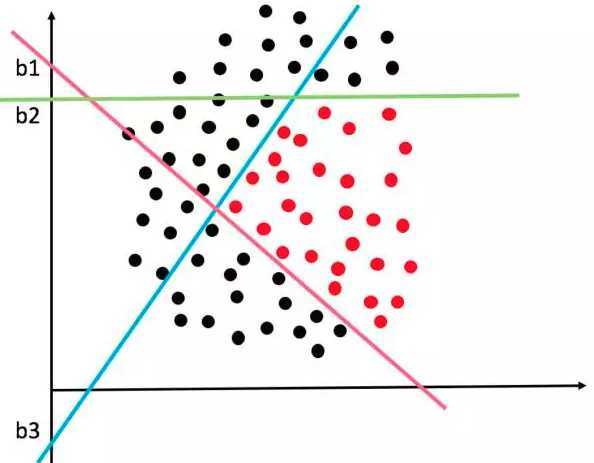
数据:工资和年龄(2个特征)
目标:预测银行会贷款多少钱(标签)
考虑:工资和年龄都会影响最终银行贷款的结果,那么它们各自有多大的影响?(参数)
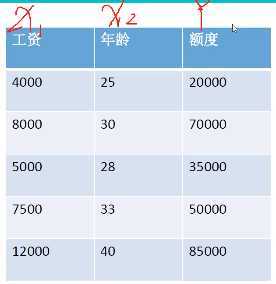
通过图表可以看出随着工资和年龄的增长,贷款额度也随之增长。X1和X2的数量级是不同的,因此需要增加两个因子:θ1x1+θ2x2=y ,在已知x1,x2,y的情况下建立回归方程。方程的目标就是求出最合适的θ1、θ2,这样就知道工资和年龄对贷款额度到底有多大的影响。
X1、X2就是我们的两个特征(年龄、工资),Y是银行最终会借给我们多少钱。
找到最合适的一条线(想象一个高维)来最好的拟合我们的数据点。(无法满足所有,满足尽可能多的点)
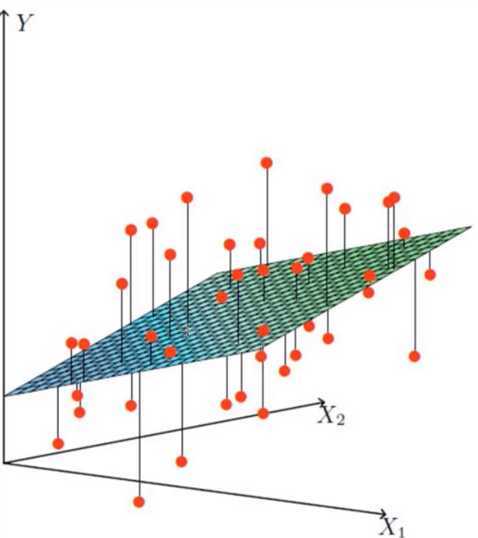
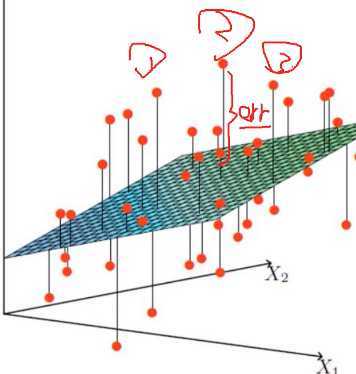
图中红点是样本数据,想根据给定的数据集拟合一个平面,使得各个样本数据到达平面的误差最小。
这个图就是机器如何进行预测的(回归)它会根据贷款的历史数据(年龄和工资分别对应于X1与X2)找出来最好的拟合线(面)来进行预测,这样新的数据来了之后直接带入进去就可以得出来该给多少钱了。
整合是把偏置项和权重参数项放到了一起(加了个θ0让其都等于1)。
一个传统的神经网络就可以看成多个逻辑回归模型的输出作为另一个逻辑回归模型的输入的“组合模型”。
因此,讨论神经网络中的偏置项b的作用,就近似等价于讨论逻辑回归模型中的偏置项b的作用。
逻辑回归模型本质:利用 y = WX + b 这个函数画决策面,其中W为模型参数,也是函数的斜率;b为函数的截距。
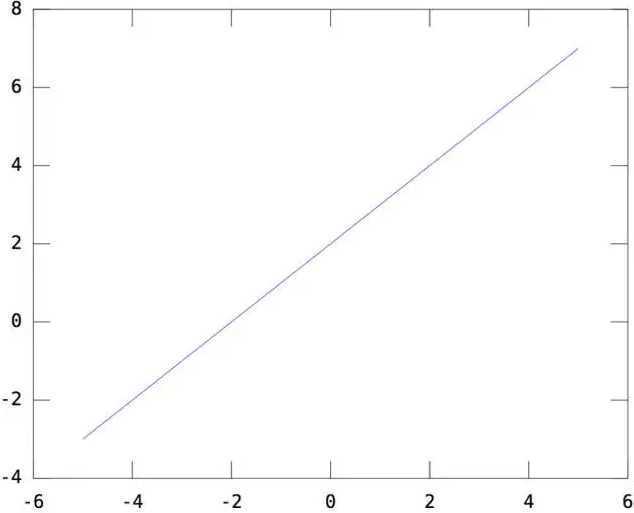
一维情况:W=[1],b=2,y=WX+b得到一个截距为2,斜率为1的直线如下所示:
二维情况:W=[1 1],b=2,则 y=WX+b得到一个截距为2,斜率为[1 1]的平面如下所示:
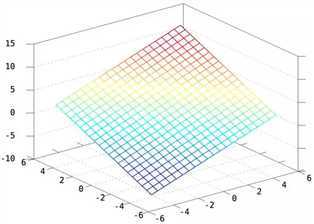
显然y=WX+b这个函数,就是2维/3维/更高维空间的直线/平面/超平面。如果没有偏置项b,则只能在空间里画过原点的直线/平面/超平面。
因此对于逻辑回归必须加上偏置项b,才能保证分类器可以在空间任何位置画决策面。
同理,对于多个逻辑回归组成的神经网络,更要加上偏置项b。
如果隐层有3个节点,那就相当于有3个逻辑回归分类器。这三个分类器各画各的决策面,那一般情况下它们的偏置项b也会各不相同。
复杂决策边界由三个隐层节点的神经网络画出如下:
如何机智的为三个分类器(隐节点)分配不同的b呢?或者说如果让模型在训练的过程中,动态的调整三个分类器的b以画出各自最佳的决策面呢?
那就是先在X的前面加个1,作为偏置项的基底,(此时X就从n维向量变成了n+1维向量,即变成 [1, x1,x2…] ),然后,让每个分类器去训练自己的偏置项权重,所以每个分类器的权重就也变成了n+1维,即[w0,w1,…],其中,w0就是偏置项的权重,所以1*w0就是本分类器的偏置/截距啦。这样,就让截距b这个看似与斜率W不同的参数,都统一到了一个框架下,使得模型在训练的过程中不断调整参数w0,从而达到调整b的目的。
所以,如果在写神经网络的代码的时候,把偏置项给漏掉了,那么神经网络很有可能变得很差,收敛很慢而且精度差,甚至可能陷入“僵死”状态无法收敛。
银行的目标得让误差越小越好,这样才能够使得我们的结果是越准确的。
独立同分布(iid,independently identically distribution)在概率统计理论中,指随机过程中,任何时刻的取值都为随机变量,如果这些随机变量服从同一分布,并且互相独立,那么这些随机变量是独立同分布。
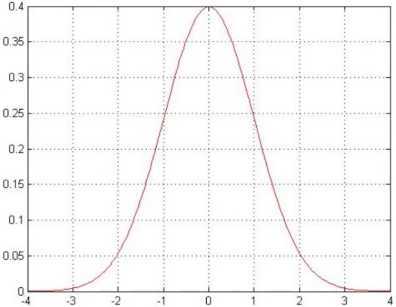
误差在0附近浮动的可能性较大,正负差距较大的可能性越来越小。符合概率统计中现实分布情况。
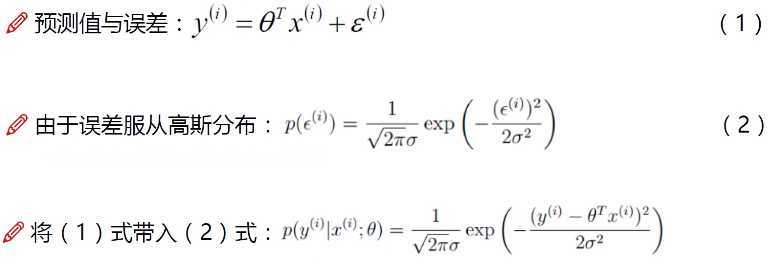
将(1)式转化为:ε(i) = y(i) - θTx(i) ,即:误差=实际值-预测值,然后带入高斯分布函数(2)式,就将误差项都替换为了x,y。
p(x;θ)代表:在给定θ的情况下x的取值;
p(y|x;θ)代表:在给定x的情况下,还给定某种参数θ的情况下,y的概率密度函数。
由于x和θ是一个定值,所以θTx(i) 可以理解为一个定值C。
似然函数是一种关于模型中参数的函数,用来表示模型参数中的似然性。
已知样本数据x(x1,x2,...,xn)组合,要使用什么样的参数θ和样本数据组合后,可以恰好得到真实值?
要让误差项越小越好,则要让似然函数越大越好,由此将问题转为求L(θ)的最大值。
引入似然函数如下:(Π从...到...的积)
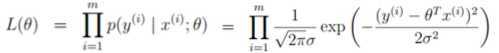
连续型变量相互独立的充要条件是联合概率密度等于边缘概率密度的乘积。因此变量符合独立同分布前提下,联合概率密度等于边缘概率密度的乘积成立。
p(y(i) | x(i);θ):什么样的x和θ组合完后,能成为y的可能性越大越好。m项的乘积非常难解,难以估计,因此要想办法转为加法。
对数似然:乘法难解,加法相对容易,对数里面乘法可以转换成加法,因此对式子左右两边取对数。
log(AB) = logA + logB
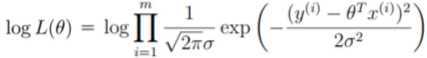
首先,取对数不影响函数的单调性,保证输入对应的概率的最大最小值对应似然函数的最值。
其次,减少计算量,比如联合概率的连乘会变成加法问题,指数亦可。
最后,概率的连乘将会变成一个很小的值,可能会引起浮点数下溢,尤其是当数据集很大的时候,联合概率会趋向于0,非常不利于之后的计算。依据ln曲线可知,很小的概率(越接近0)经过对数转换会转变为较大的负数,解决下溢问题。
取对数虽然会改变极值,但不会改变极值点。任务依然是求极值,因此L(θ)和logL(θ)两者是等价的。
继续处理: ,由于log A·B = logA + logB,因此可以将累乘转换为累加: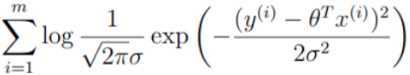 。
。
进一步观察发现,可以将上面的式子看作是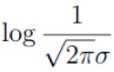 和
和 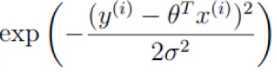 两部分的组合,即log A·B = logA + logB。
两部分的组合,即log A·B = logA + logB。
这里要求解是的 θ,因此其他的都可以看作是常数项。 因此可以把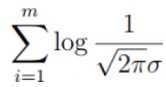 看作是m倍的常数项:
看作是m倍的常数项: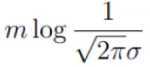 。
。
再观察另一个部分: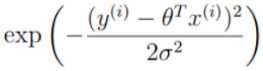 ,exp:高等数学里以自然常数e为底的指数函数,它同时又是航模名词,全称Exponential(指数曲线)。由于给对数取不同的底数只会影响极值,但不会影响极值点。
,exp:高等数学里以自然常数e为底的指数函数,它同时又是航模名词,全称Exponential(指数曲线)。由于给对数取不同的底数只会影响极值,但不会影响极值点。
将这一部分底数取e,则与exp(x)的以e为底的指数发生抵消,再将常数项提取出来,可以将公司转成这种累加形式: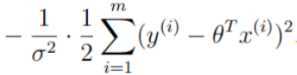
公式到这里就不能继续化简了,毕竟每个人的年龄(x)和每个有多少钱(y)是不同的,因此,必须从第一个样本迭代到第m个样本。最终简化为: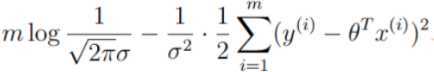
之前的目标:x和θ组合完后,成为y的可能性越大越好。因此现在要求得极大值点。A是一个恒为正的常数,B中包含平分因此也是一个正数。因此是两个正数间的减法。
如要求值越大越好,因此B: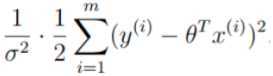 必须越小越好。
必须越小越好。
现在就将目标转换为求解最小二乘法。
从上面的推导可以得出结论:要求让似然函数越大越好,可转化为求θ取某个值时使J(θ)最小的问题。
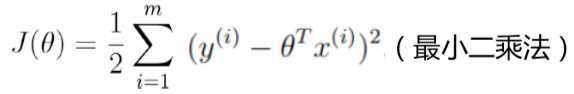
求解最小二乘法的方法一般为两种:矩阵式、梯度下降法。
数据集含有m个样本,每个样本有n个特征时:
矩阵式的推导如下所示:
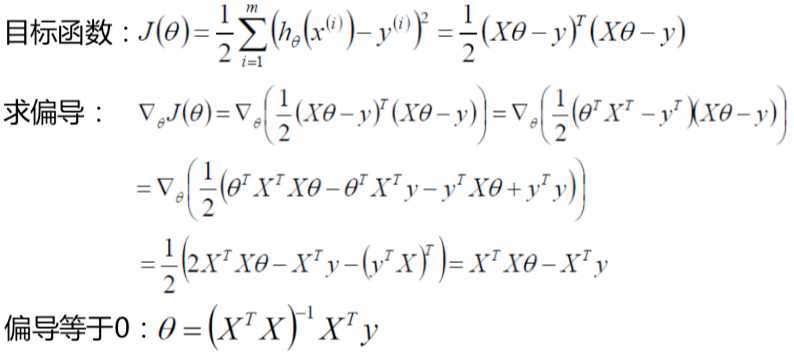
让J(θ)对θ求偏导,当偏导等于零时,则这个θ就是极值点。XT代表X矩阵的转置,XT与X的乘积一定会得到一个对称阵。
另外存在公式: θTXTXθ 等于 2XTXθ。
XTX的逆矩阵为:(XTX)-1 ,将这个逆矩阵分别乘到偏导结果等式两边,左边期望是零,推导得到:
0 = θ - (XTX)-1 · XTy,转换等式得到:θ=(XTX)-1XTy
这种方法存在的问题:不存在学习的过程;矩阵求逆不是一个必然成功的行为(存在不可逆);
原文:https://www.cnblogs.com/xiugeng/p/12977373.html