Redis是C语言开发的一个高性能键值对的内存数据库,它属于NoSQL
数据类型支持不同
Redis支持5种数据类型,Memcached只支持key-value结构
单个value,redis支持最大1GB,memcached支持1MB
数据持久化支持
Memcached不支持数据持久化
集群
Memcached本身不支持分布式,只能由客户端通过像一致性哈希这样的分布式算法来实现分布式存储
Redis有自带的redis cluster,引入了主从复制、哨兵来保证数据的完整,解决单点故障问题
完全基于内存,绝大部分请求是内存操作
使用单线程,避免了不必要的上下文切换和竞争
多路IO复用模型,可以处理并发的连接。内部采用epoll+redis自己实现的事件框架,epoll中的读、写、关闭、连接都转化成了事件
Redis内部使用文件事件处理器 file event handler,这个文件事件处理器是单线程的,所以Redis才叫做单线程的模型。它采用IO多路复用机制同时监听多个Socket,根据Socket上
的事件来选择对应的事件处理器进行处理。
文件事件处理器的结构包含 4 个部分:
多个Socket
IO多路复用程序
文件事件分派器
事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)
多个Socket可能会并发产生不同的操作,每个操作对应不同的文件事件,但是IO多路复用程序会监听多个Socket,会将Socket产生的事件放入队列中排队,事件分派器每次从队列中取
出一个事件,把该事件交给对应的事件处理器进行处理。
因为Redis是基于内存的操作,CPU不是瓶颈,瓶颈最有可能是机器内存的大小或网络带宽。
不需要各种锁的消耗
Redis的各种数据结构可能会进行很细粒度的操作,比如在很长的列表后面添加一个元素,或者在hash当中添加或删除。使用单线程不需要考虑锁的问题
利用IO多路复用模型满足需求
可以多起几个Redis实例,利用多核
Redis也会开子进程或子线程去进行辅助的操作,比如持久化。
Redis在4.0版本里引入了可以被其他线程处理的删除操作,主要是Redis中有些超大键值对在删除时耗时会长,删除操作可以在后台异步操作。
6.0版本引入了多线程,主要是将读写io多线程处理,命令执行还是使用单线程
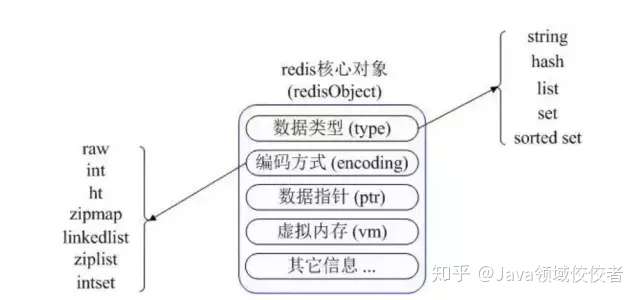
Redis 内部使用一个 redisObject 对象来表示所有的 key 和 value。
String是最常用的一种数据类型,普通的key/value存储都可以归为此类,Value 不仅是 String,也可以是数字。
String 类型是二进制安全的,意思是 Redis 的 String 类型可以包含任何数据,比如 jpg 图片或者序列化的对象。String 类型的值最大能存储 512M。
常用命令:set/get/decr/incr/mget等;
实现方式:
String在redis内部存储默认就是一个字符串,被redisObject所引用,当遇到incr、decr等操作时会转成数值型进行计算,此时redisObject的encoding字段为int。
应用场景:
这个是类似 Map 的一种结构,是一个string类型的field和value的映射表
常用命令:hget/hset/hgetall等
实现方式:Redis的Hash实际是内部存储的Value为一个HashMap
当前HashMap的实现有两种方式:当HashMap的成员比较少时,Redis为了节省内存会采用类似一维数组的方式来紧凑存储,而不会采用真正的HashMap结构,这时对应的value的redisObject的encoding为
zipmap,当成员数量增大时会自动转成真正的HashMap,此时encoding为ht。
应用场景:我们要存储一个用户信息对象数据,其中包括用户ID、用户姓名、年龄和生日,通过用户ID我们希望获取该用户的姓名或者年龄或者生日
List 是有序列表
常用命令:lpush/rpush/lpop/rpop/lrange等
实现方式:Redis list的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销,Redis内部的很多实现,包括发送缓冲队列等也都是用的这个数据结构
应用场景:
消息队列:Redis的链表结构,可以轻松实现阻塞队列,可以使用左进右出的命令组成来完成队列的设计。比如:数据的生产者可以通过Lpush命令从左边插入数据,多个数据消费者,可以使用BRpop命令阻塞的“抢”列表尾部的数据。
文章列表或者数据分页展示的应用。
比如,我们常用的博客网站的文章列表,当用户量越来越多时,而且每一个用户都有自己的文章列表,而且当文章多时,都需要分页展示,这时可以考虑使用Redis的列表,列表不但有序同时还支持按
照范围内获取元素,可以完美解决分页查询功能。比如可以通过 lrange 命令,读取某个闭区间内的元素,可以基于 List 实现分页查询
Set 是无序集合,会自动去重
常用命令:sadd/spop/smembers/sunion等
实现方式:set 的内部实现是一个 value永远为null的HashMap,实际就是通过计算hash的方式来快速排重的,这也是set能提供判断一个成员是否在集合内的原因
应用场景:
常用命令:zadd/zrange/zrem/zcard等
实现方式:Redis sorted set的内部使用HashMap和跳跃表(SkipList)来保证数据的存储和有序,HashMap里放的是成员到score的映射,而跳跃表里存放的是所有的成员,排序依据是HashMap里存的
score,使用跳跃表的结构可以获得比较高的查找效率,并且在实现上比较简单
应用场景:Redis sorted set的使用场景与set类似,区别是set不是自动有序的,而sorted set可以通过用户额外提供一个优先级(score)的参数来为成员排序,并且是插入有序的,即自动排序。当你
需要一个有序的并且不重复的集合列表,那么可以选择sorted set数据结构,比如twitter 的public timeline可以以发表时间作为score来存储,这样获取时就是自动按时间排好序的。
typedef struct redisObject{
//类型
unsigned type:4;
//编码
unsigned encoding:4;
//指向底层数据结构的指针
void *ptr;
//引用计数
int refcount;
//记录最后一次被程序访问的时间
unsigned lru:22;
}robj
因为 C 语言不具备自动回收内存功能,于是 Redis自己构建了一个内存回收机制,通过在 redisObject 结构中的 refcount 属性实现。这个属性会随着对象的使用状态而不断变化:
创建一个新对象,属性 refcount 初始化为1
对象被一个新程序使用,属性 refcount 加 1
对象不再被一个程序使用,属性 refcount 减 1
当对象的引用计数值变为 0 时,对象所占用的内存就会被释放。
为了解决循环引用而导致内存泄漏的问题,redis引入内存淘汰策略:
redis.conf 配置文件中,在 MEMORY MANAGEMENT 下有个 maxmemory-policy 配置:
maxmemory-policy :当内存使用达到 最大值 时,redis 使用的 清除策略。有以下几种可以选择:
volatile-lru 利用LRU算法移除设置过过期时间的key (LRU:最近使用 Least Recently Used )
allkeys-lru 利用LRU算法移除任何key
volatile-random 移除设置过过期时间的随机key
allkeys-random 移除随机key
volatile-ttl 移除即将过期的key(minor TTL)
noeviction (默认值)不移除任何key,只是返回一个写错误 ,默认通过这种配置,也可以对内存进行回收。
refcount 属性除了能实现内存回收以外,还能用于内存共享。
比如通过如下命令 set k1 100,创建一个键为 k1,值为100的字符串对象,接着通过如下命令 set k2 100 ,创建一个键为 k2,值为100 的字符串对象,那么 Redis 是如何做的呢?
将数据库键的 值 指针指向一个现有值的对象
将被共享的值对象引用refcount 加 1
参考:
原文:https://www.cnblogs.com/LMFrank/p/13196568.html