声学模型是指给定声学符号(音素)的情况下对音频特征建立的模型。
用 \(X\) 表示音频特征向量 (观察向量),用 \(S\) 表示音素 (隐藏/内部状态),声学模型表示为 \(P(X|S)\)。
但我们的机器是个牙牙学语的孩子,并不知道哪个音素具体的发出的声音是怎么样的。我们只能通过大量的数据去教他,比如说在拼音「é」的时候对应「鹅」的发音,而这个过程就是 GMM 所做的,根据数据建立起「é」这个拼音对应的音频特征分布,即 \(P(x|s=é)\)。孩子学会每个拼音的发音后,就可以根据拼音拼读一个单词 / 一个句子,但你发现他在读某段句子的时候,听起来好像怪怪的,你检查发现是他把某个拼音读错了,导致这句话听起来和常理不符。而这个怪怪的程度就是你听到这个音频特征序列的时感觉这个音频序列以及其背后的拼音出现的可能性的倒数,这部分则是通过 HMM 来建模的。
总结一下,GMM 用于对音素所对应的音频特征分布进行建模,HMM 则用于音素转移和音素对应输出音频特征之间关系的建模。
即为隐马尔可夫模型(Hidden Markov model,HMM)
HMM 脱胎于马尔可夫链,马尔可夫链表示的是一个系统中,从一个状态转移到另一个状态的所有可能性。但因为在实际应用过程中,并不是所有状态都是可观察的,不过我们可以通过可观察到的状态与隐藏状态之间的可能性。因此就有了隐马尔可夫模型。
HMM 要遵循的假设:
一阶马尔可夫假设:下一个状态只依赖于当前的状态。因此多阶马尔可夫链可简化为
输出无关假设:每个输出只取决于当前 (内部/隐藏) 状态,和前一个或多个输出无关。
声学模型为什么要用HMM?
因为声学模型建立的是在给定音素序列下输出特定音频特征序列的似然 \(P(X|S)\),但在实际情况中,我们只知道音频特征序列,并不知道其对应的音素序列,所以我们需要通过 HMM 建立音频特征与背后的每个音素的对应关系,以及这个音素序列是怎么由各个音素组成的。
上两个假设可以引申出 HMM 中主要的两种概率构成:
HMM 的三个经典问题
??:后文提到的状态即指的是内部 / 隐藏状态。
评估问题就是说,我已知模型参数 \(\theta\) (输出概率以及转移概率),最后得到的观察序列为某个特定序列 \(X\) 的概率是多少。
在刚才的例子中,就是孩子已经知道每个拼音后面可能接什么拼音,每个拼音怎么读,当他读出了某段声音,这段声音的概率是多少。
因为在观察序列固定的情况下,有多种可能的状态序列 \(S\),而评估问题就是要计算出在所有可能的状态下得到观察序列的概率,表示为
在当前的公式里,我们暂时先忽略固定的参数 \(\theta\)。根据一阶马尔可夫假设,时刻 \(t\) 的状态都只取决于时刻 t-1 的状态,因此单个状态序列出现的概率表示为
其中, \(\pi_k\) 表示时刻1下状态为 \(k\) 的概率。
根据输出无关假设,在时刻 \(t\) 观察序列的值只取决于时刻 \(t\) 的状态,因此观察序列关于状态序列的似然表示为
因此整个观察序列出现的概率为
由于 \(i,j,k\) 都表示可能的状态,假设有 \(n\) 种状态,那么计算该概率的事件复杂度就为 \(O(n^T)\),可谓是指数级别了。
因此,前人开动了脑筋,提出了在该问题上将时间复杂度将为多项式时间的方法。
该方法采用了分治 / 动态规划的思想,在时刻 \(t\) 下的结果可以利用时刻 \(t-1\) 的结果来计算。
在时刻 \(t\),观察序列的概率表示为前 \(t\) 个时刻的观察序列与时刻 \(t\) 所有可能的状态同时出现的概率和
其中, \(N\) 表示所有可能的状态的集合。
而连加符号的后面部分被定义为前向概率 \(\alpha_t(j)\),而它可以被上一个时刻的前向概率迭代表示。
通过该方法,当前时刻下某个状态的概率只需要遍历上一时刻所有状态的概率 (\(n\)),然后当前时刻的所有状态的概率和也只需要遍历当前的所有状态就可以计算得到 (\(n\)),考虑到观察序列持续了 \(T\) 个时刻,因此时间复杂度降为 \(O(n^2T)\)。
整个过程总结如下
解码问题就是说在得到 HMM 模型之后,我们如何通过观察序列找到最有可能的状态序列。在语音识别中,在给定的音频片段下,找到对应的各个音素。
还是刚才的例子,我们需要猜测孩子读出的这段声音最有可能对应什么样的拼音序列,这就是解码问题。
数学表示
给定在时间 \(t\) 下的内部状态为 \(j\),局部最优概率 \(v_t(j)\) 表示的是在时刻 \(t\) 观察序列与最优内部状态序列的联合概率。
同样也可以根据时间递归表示为
算法具体流程如下
在表示上很类似于上面的前向算法,只是加和变成了取最大值。具体推导流程也就不再赘述了。两者的区别可以看下图(来源) ,红线表示解码路径,黑线表示评估路径。
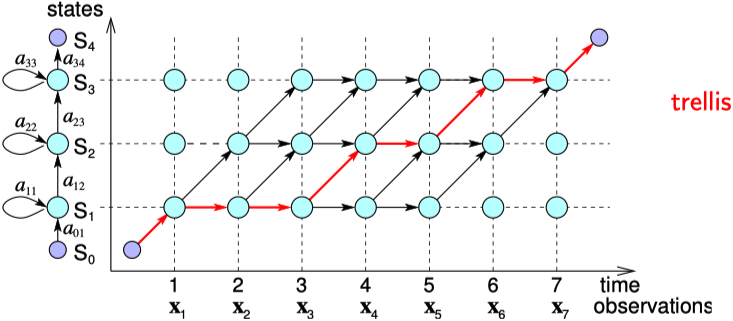
不过这张图是简化的状态,即状态序列 \(S\) 是确定的情况下的状态转移与观察序列之间的关系。
??思考:为何每次取局部最优最后就能得到全局最优?
这和一阶马尔可夫假设有关,因为每一个时刻的状态只取决于上一个时刻的状态,因此只要上一个时刻每一个状态的前向概率是最大的,再乘上这一时刻对某个状态的转移概率和输出概率,而这两个概率在参数表里是固定的,因此再选出乘出来的概率最大即可保证该时刻在这个时刻为这个状态的概率最大,直到最后一个时刻。(类似于动态规划的状态转移方程思想)
训练 (learning) 问题主要是如何学习 HMM 模型参数(输出概率和表现概率)的问题。在语音识别中,即在一开始只有音频和标注的情况下,如何学习到模型。
还是刚刚那个例子,假如说你没有教孩子,但给了他本语文教材和对应的录音磁带,他需要通过教材中的拼音和磁带中的录音来训练语感 (比如说哪个拼音读什么音,每个拼音之后可能会跟什么拼音)。他自学成才了以后我们才能做刚刚那两个问题。
所以说训练问题是评估和解码问题的基础,但是是三个问题中最复杂的,因为它是无闭式解的。
HMM 参数估计方法:
HMM训练问题的标准算法,又称前向后向算法,是 EM 算法的特例。
后向算法的表示和前向算法类似,而后向概率 \(\beta_t(i)\) 表示的是在给定 \(t\) 时刻状态为 \(i\),看到时刻 t+1 到时刻 \(T\) 观察序列的概率,表示为
最后,整个观察序列出现的概率用后向算法表示为
为了能学习 HMM 模型参数,我们可以通过一个最大似然估计的变体评估我们的转移概率 \(\hat{a}_{ij}\) ,可以表示为
但如何计算这些次数是个问题,假设我们可以估计在时刻 \(t\) 和给定观察序列下从状态 \(i\) 转移到状态 \(j\) 的概率,那我们就可以把每个时刻的概率加起来作为从状态 \(i\) 转移到状态 \(j\) 的总次数。
我们定义了一个「状态转移占有(occupation)率」 \(\xi_{t}(i,j)\) ,作为给定所有观察序列的情况下在时刻 \(t\) 状态为 \(i\) 后下一时刻转移到状态 \(j\) 的概率,表示为
下图(修改自来源)直观地展示了 \(\xi_{t}(i,j)\) 分子部分的计算过程,因此其分子可以表示为 \(\alpha_{t}(i) a_{i j} \beta_{t+1}(j) b_{j}\left(x_{t+1}\right)\)
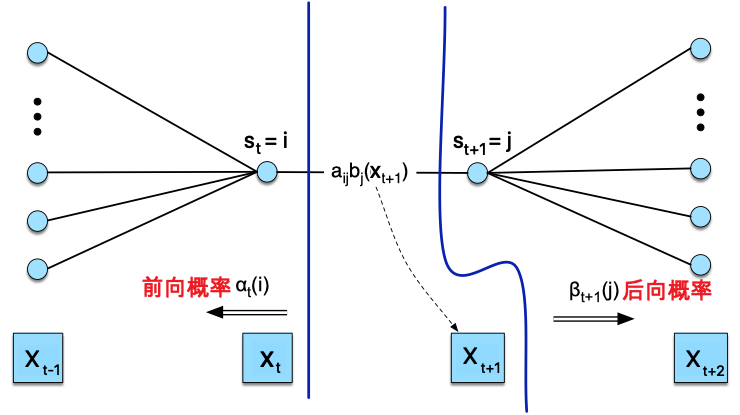
而其分母部分则可以表示为某个时刻所有状态的前向概率和后向概率的乘积和
因此 \(\xi_{t}(i,j)\) 最后可表达为
我们可以把各个时刻的 \(\xi_{t}(i,j)\) 加起来作为「从状态 \(i\) 转移到状态 \(j\) 的期望次数」,再将状态 \(j\) 所有可能的状态下的期望次数加和就可以得到「从状态 \(i\) 转移到所有状态的期望次数」,从而计算得到 \(\hat{a}_{ij}\)。
我们同样需要一个用于计算输出概率 \(\hat{b}_j(v_k)\) 的最大似然估计公式,\(v_k\) 表示的是输出序列中的第 \(k\) 个音素对应的音频特征。
为了计算这个公式,我们需要知道在给定观察序列的情况下在时刻 \(t\) 的状态为 \(i\) 的概率,我们将其称为「状态占有率」 \(\gamma_{t}(i)\),
而分子部分的概率其实刚刚我们在计算 \(\xi_{t}(i,j)\) 分母时已经用到了,即时刻 \(t\) 下为状态 \(i\) 的前向概率乘上后向概率。
得到了 \(\gamma_{t}(i)\) 以后,就可以用他来计算 \(\hat{b}_j(v_k)\) 了,我们加上了所有 \(x_t\) 为 \(v_k\) 的 时刻的 \(\gamma_{t}(i)\) 作为分子,而分母就是所有时刻的 \(\gamma_{t}(i)\) 之和。
同时,\(\hat{a}_{ij}\) 的分母也可以用 \(\gamma_{t}(i)\) 来表示
得到新的 HMM 参数 \(\theta_1\) 后,又可以计算得到新的 \(\theta_2\),同样又可以估计得到新的最佳 \(\theta_1\),一直迭代这个过程直到收敛。
在 E 步建立 \(P(\gamma,\xi | x, a, b)\),然后 M 步 找到将上式最大化的参数 \(a, b\),具体流程如下
尽管从原理上来讲前向后退算法可以完全无监督地学习参数,但实际上初始化非常重要。 因此,通常会给算法额外的信息。 例如,对于基于 HMM 的语音识别,通常手动设定 HMM 结构,并且从一组观察序列 \(X\) 中仅训练输出概率和(非零的)转移概率。
高斯混合模型 (Gaussian mixture model,GMM) 就是用混合的高斯随机变量的分布来拟合训练数据(音频特征)形成的模型。该方法提供了一种基于规则的方法来衡量一个音素和被观察音频帧的「距离」。
给定一个音素,我们可以使用 GMM 学习观察值的特征向量,这个概率分布允许我们在给定一个音素(状态)下计算音频段的似然 \(P(x | s)\).
假设观察向量中某个特征 \(x\) 的分布为正态分布,那么该特征 \(x\) 的似然函数可以表示为均值为 \(\mu\) 方差为 \(\sigma^2\) 的高斯分布
在被标记了状态的训练数据下,我们可以计算的到关于状态 \(i\) 的均值和方差
高斯分布易于从训练数据中学习并且让我们有了一个良好的似然函数 \(f(x|\mu,\sigma)\)。在语音识别中我们可以为每个音素(状态)学到一个高斯分布,这将作为似然概率,也可以作为 HMM 中的输出概率。
根据 HMM 在时刻 \(t\) 下所处状态 \(i\) 的概率,将每个观察向量 \(x_t\) 按比例分配给每个可能的状态 \(i\)。而在时刻 \(t\) 处于状态 \(i\) 的概率在 HMM 中为表示为状态占有率 \(\gamma_t(i)\),因此可以在将高斯分布的参数期望表示为
在多变量高斯分布中,我们将均值 \(\mu\) 替换为多个特征均值的向量 \(\boldsymbol{\mu} = \left(\mu_1,\ldots,\mu_n\right)^T\),将方差 \(\sigma\) 替换为协方差矩阵 \(\Sigma\in\mathbb{R}^{n\times n}\),其中第 \(i\) 行 \(j\) 列个元素表示为 \(\sigma_{ij}^2 = E\left[(x_i-\mu_i)(x_j-\mu_j)\right]\),最终的高斯分布表示为
通过快速傅立叶变化 FFT 得到的特征之间是相关的,但通过梅尔倒谱相关系数 MFCC 得到的特征之间是不相关的。在特征不相关的情况下,协方差矩阵是对角阵,计算和存储代价小了很多。这样我们就可以单独考虑每个声学特征的方差。
但单个高斯分布可能并不能很好地来对特征的分布进行建模 (现实世界总是没有那么理想化),因此采用多个加权的高斯分布来对对特征分布建模。
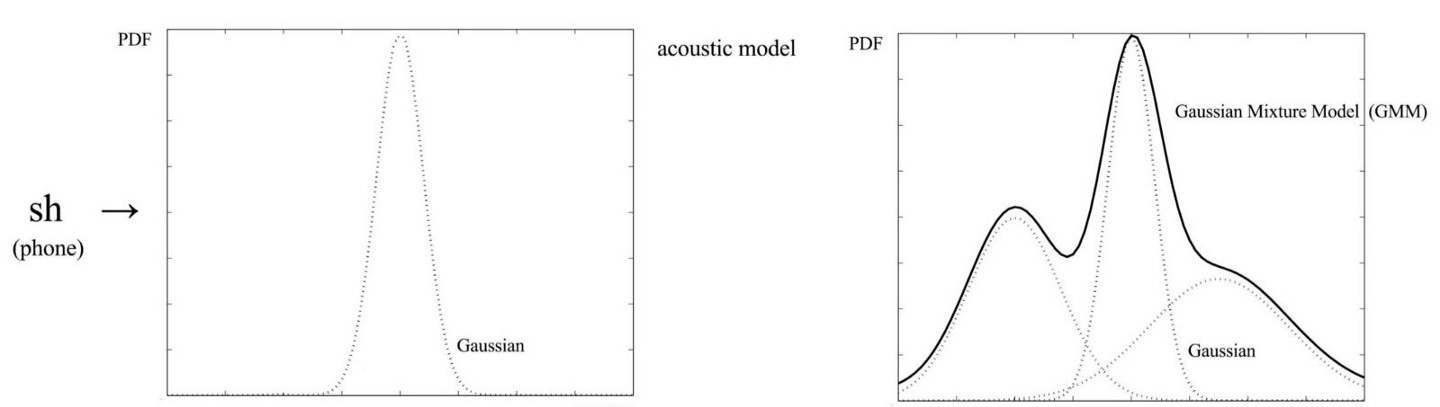
比如说上图(来源)中的3分量 GMM,有6个高斯参数加上3个权重。
因此,对于一个 HMM 的状态 \(j\),观察特征向量 \(x\) 的似然函数可以表示为
其中 M 为 GMM 的分量数,而 \(c_{j m}\) 表示的是在状态 \(j\) 下第 \(m\) 个分量的权重。
在实际的 GMM 训练中,通常采用 EM 算法来进行迭代优化,以求取 GMM 中的加权系数及各个高斯函数的均值与方差等参数。
缺点:
最后再重声一下,GMM 用于对音素所对应的音频特征分布进行建模,而 HMM 则用于音素转移和音素对应输出音频特征之间关系的建模。
写不动了,HMM 和 GMM 梳理推导了好久,如果各位读者有不懂的欢迎留言讨论~??
参考链接:
原文:https://www.cnblogs.com/IO382/p/13205135.html