
import os
import json
import random
import paddle
import zipfile
import numpy as np
import paddle.fluid as fluid
import matplotlib.pyplot as plt
from PIL import Image
"""参数配置
"""
train_parameters = {
"input_size": [3, 224, 224], # 输入图片的shape
"class_dim": -1, # 分类数
"src_path": ‘./maskDetect.zip‘, # 原始数据集路径
"target_path": ‘./‘, # 要解压的路径
"train_list_path": ‘./train.txt‘, # train.txt路径
"eval_list_path": ‘./eval.txt‘, # eval.txt路径
"readme_path": ‘./readme.json‘, # readme.json路径
"label_dict": {}, # 标签字典
"num_epochs": 5, # 训练迭代次数
"train_batch_size": 5, # 训练时每次喂入批次大小
"learning_strategy": { # 优化时相关参数配置
"lr": 0.001 # 学习率
}
}
"""参数初始化
"""
src_path = train_parameters[‘src_path‘]
target_path = train_parameters[‘target_path‘]
train_list_path = train_parameters[‘train_list_path‘]
eval_list_path = train_parameters[‘eval_list_path‘]
batch_size = train_parameters[‘train_batch_size‘]
· 解压数据集
def unzip_data(src_path, traget_path):
"""解压原始数据集
"""
if not os.path.isdir(traget_path + "maskDetect"):
z = zipfile.ZipFile(src_path, ‘r‘)
z.extractall(path=traget_path)
z.close()
unzip_data(src_path, target_path)
· 生成数据列表
def get_data_list(target_path, train_list_path, eval_list_path):
"""生成数据列表
"""
# 存放所有类别信息
class_detail = []
# 获取所有类别保存的文件夹名
data_list_path = target_path + ‘maskDetect/‘
class_dirs = os.listdir(data_list_path)
# 总的图像数量
all_class_images = 0
# 存放类别标签
class_label = 0
# 存放类别数目
class_dim = 0
# 存储要写进eval.txt和train.txt中的内容
trainer_list = []
eval_list = []
# 读取每个类别,[‘maskimages‘, ‘nomaskimages‘]
for class_dir in class_dirs:
if class_dir != ‘.DS_Store‘:
class_dim += 1
# 每个类别的信息
class_detail_list = {}
eval_sum = 0
trainer_sum = 0
# 统计每个类别有多少张图片
class_sum = 0
# 获取类别路径
path = data_list_path + class_dir
# 获取所有图片
img_paths = os.listdir(path)
# 遍历文件夹下每个图片
for img_path in img_paths:
name_path = path + ‘/‘ +img_path # 每张图片路径
# 每10张图片取一次图片做验证集
if class_sum % 10 == 0:
# 验证集数目+1
eval_sum += 1
eval_list.append(name_path + ‘\t%d‘ % class_label + ‘\n‘)
else:
trainer_sum += 1 # 训练集数目
trainer_list.append(name_path + ‘\t%d‘ % class_label + ‘\n‘)
# 类别数目
class_sum += 1
# 所有类别图片数目
all_class_images += 1
# 说明的json文件的class_detail数据
class_detail_list[‘class_name‘] = class_dir # 类别名称
class_detail_list[‘class_label‘] = class_label # 类别标签
class_detail_list[‘class_eval_images‘] = eval_sum # 该类数据的测试集数目
class_detail_list[‘class_trainer_images‘] = trainer_sum # 该类数据的训练集数目
class_detail.append(class_detail_list)
# 初始化标签列表
train_parameters[‘label_dict‘][str(class_label)] = class_dir
class_label += 1
# 初始化分类数
train_parameters[‘class_dim‘] = class_dim
# 乱序
random.shuffle(eval_list)
with open(eval_list_path, ‘a‘) as f:
for eval_image in eval_list:
f.write(eval_image)
random.shuffle(trainer_list)
with open(train_list_path, ‘a‘) as ff:
for train_image in trainer_list:
ff.write(train_image)
# 用于说明的json文件信息
readjson = {‘all_class_name‘: data_list_path,
‘all_class_images‘: all_class_images,
‘class_detail‘: class_detail}
jsons = json.dumps(readjson, sort_keys=True, indent=4, separators=(‘,‘, ‘: ‘))
with open(train_parameters[‘readme_path‘], ‘w‘) as f:
f.write(jsons)
print(‘生成数据列表完成.‘)
# 划分训练集和数据集,乱序并生成数据列表
# 每次生成数据列表前先清空train.txt和eval.txt
# 防止train.txt和eval.txt叠加写入数据
with open(train_list_path, ‘w‘) as f:
f.seek(0) # 游标移至文件头
f.truncate() # 截断游标后的字符
with open(eval_list_path, ‘w‘) as ff:
ff.seek(0)
ff.truncate()
# 生成数据列表
get_data_list(target_path, train_list_path, eval_list_path)
生成的readme.json文件内容:
{
"all_class_images": 185,
"all_class_name": "./maskDetect/",
"class_detail": [
{
"class_eval_images": 12,
"class_label": 0,
"class_name": "maskimages",
"class_trainer_images": 103
},
{
"class_eval_images": 7,
"class_label": 1,
"class_name": "nomaskimages",
"class_trainer_images": 63
}
]
}
生成的train.txt文件内容:
生成的eval.txt文件内容:
· 定义并构造数据提供器
def custom_reader(file_list):
"""自定义reader
"""
def reader():
with open(file_list, ‘r‘) as f:
lines = [line.strip() for line in f]
for line in lines:
img_path, lab = line.strip().split(‘\t‘)
img = Image.open(img_path)
if img.mode != ‘RGB‘: # 统一色彩空间(防止部分图像为RGBA色彩空间,程序报错)
img = img.convert(‘RGB‘)
img = img.resize((224, 224), Image.BILINEAR)
img = np.array(img).astype(‘float32‘)
img = img.transpose((2, 0, 1)) # HWC to CHW
img = img / 255 # 归一化
yield img, int(lab)
return reader
# 构造数据提供器
train_reader = paddle.batch(reader=custom_reader(train_list_path),
batch_size=batch_size,
drop_last=True)
eval_reader = paddle.batch(reader=custom_reader(eval_list_path),
batch_size=batch_size,
drop_last=True)
说明:数据预处理已合并在数据提供器定义函数之中,详细情况请参考上述代码的注释部分。
# 池化-卷积类
class ConvPool(fluid.dygraph.Layer):
def __init__(self,
num_channels, # 通道数
num_filters, # 卷积核个数
filter_size, # 卷积核尺寸
pool_size, # 池化核尺寸
pool_stride, # 池化步长
groups, # 卷积组数(连续卷积个数)
conv_stride=1,
conv_padding=1,
act=None, # 激活函数类型
pool_type=‘max‘):
super(ConvPool, self).__init__()
self._conv2d_list = []
for i in range(groups):
# add_sublayer方法:返回一个由所有子层组成的列表
conv2d = self.add_sublayer(‘bb_%d‘ % i,
fluid.dygraph.Conv2D(num_channels=num_channels, # 通道数
num_filters=num_filters, # 卷积核个数
filter_size=filter_size, # 卷积核大小
stride=conv_stride, # 步长
padding=conv_padding, # padding大小,默认为0
act=act)
)
num_channels = num_filters
self._conv2d_list.append(conv2d)
self._pool2d = fluid.dygraph.Pool2D(pool_size=pool_size, # 池化核大小
pool_type=pool_type, # 池化类型,默认是最大池化
pool_stride=pool_stride) # 池化步长
def forward(self, inputs):
x = inputs
for conv in self._conv2d_list:
x = conv(x)
x = self._pool2d(x)
return x
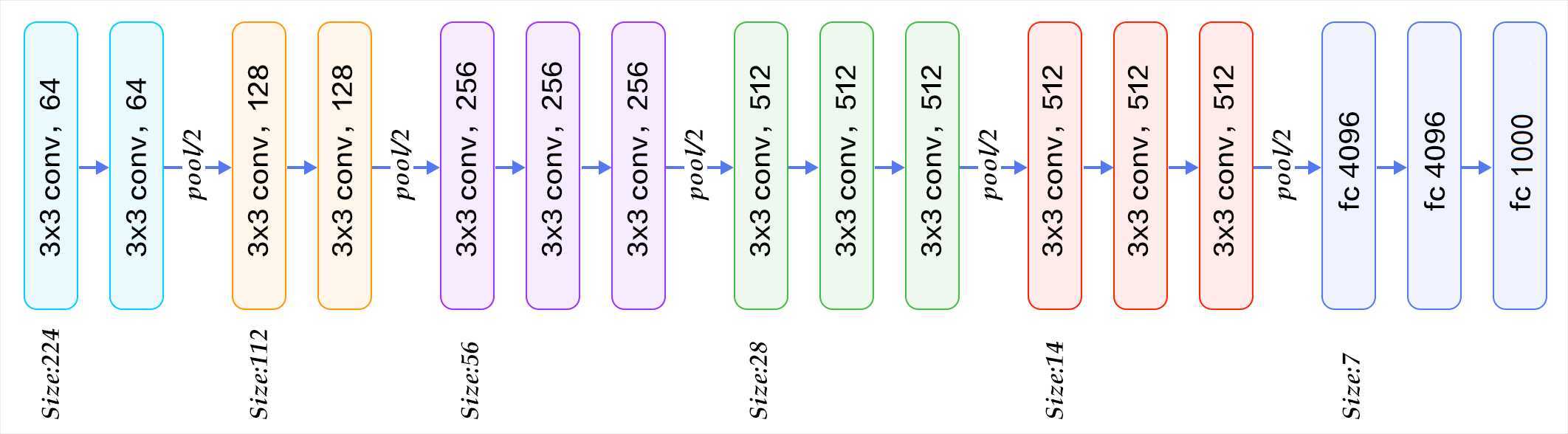
说明:由于vgg16结构存在连续卷积,并且连续卷积后都跟有一池化层,结构比较有规律,因此使用一个池化-卷积类封装卷积和池化层详细参数请参考上述代码及注释。
# VGG16网络
class VGGNet(fluid.dygraph.Layer):
def __init__(self):
super(VGGNet, self).__init__()
"""
ConvPool方法调用参数说明(以convpool01定义为例):
3 - 通道数为3
64 - 卷积核个数64
3 - 卷积核大小3×3
2 - 池化核大小2×2
2 - 池化步长2
2 - 连续卷积个数为2
"""
self.convpool01 = ConvPool(3, 64, 3, 2, 2, 2, act=‘relu‘)
self.convpool02 = ConvPool(64, 128, 3, 2, 2, 2, act=‘relu‘)
self.convpool03 = ConvPool(128, 256, 3, 2, 2, 3, act=‘relu‘)
self.convpool04 = ConvPool(256, 512, 3, 2, 2, 3, act=‘relu‘)
self.convpool05 = ConvPool(512, 512, 3, 2, 2, 3, act=‘relu‘)
# 全连接层定义
self.pool_5_shape = 512 * 7 * 7
self.fc01 = fluid.dygraph.Linear(self.pool_5_shape, 4096, act=‘relu‘)
self.fc02 = fluid.dygraph.Linear(4096, 4096, act=‘relu‘)
self.fc03 = fluid.dygraph.Linear(4096, 2, act=‘softmax‘)
def forward(self, inputs, label=None):
y = self.convpool01(inputs)
y = self.convpool02(y)
y = self.convpool03(y)
y = self.convpool04(y)
y = self.convpool05(y)
y = fluid.layers.reshape(y, shape=[-1, 512*7*7])
y = self.fc01(y)
y = self.fc02(y)
y = self.fc03(y)
if label is not None:
acc = fluid.layers.accuracy(input=y, label=label)
return y, acc
else:
return y
all_train_iter = 0
all_train_iters = []
all_train_costs = [] # 代价列表
all_train_accs = [] # 准确率列表
# 参数变化的可视化
def draw_train_process(title, iters, costs, accs, label_cost, label_acc):
plt.title(title, fontsize=24)
plt.xlabel(‘iter‘, fontsize=20)
plt.ylabel(‘cost/acc‘, fontsize=20)
plt.plot(iters, costs, color=‘red‘, label=label_cost)
plt.plot(iters, accs, color=‘green‘, label=label_acc)
plt.legend()
plt.grid()
plt.show()
def draw_process(title, color, iters, data, label):
plt.title(title, fontsize=24)
plt.xlabel(‘iter‘, fontsize=20)
plt.ylabel(label, fontsize=20)
plt.plot(iters, data, color=color, label=label)
plt.legend()
plt.grid()
plt.show()
说明:有关参数可视化函数的调用,将在训练部分代码中展示,稍安勿躁。
# 训练
with fluid.dygraph.guard():
print(train_parameters[‘class_dim‘])
print(train_parameters[‘label_dict‘])
vgg = VGGNet()
vgg.train()
optimizer = fluid.optimizer.AdamOptimizer(learning_rate=train_parameters[‘learning_strategy‘][‘lr‘],
parameter_list=vgg.parameters())
for epoch_num in range(train_parameters["num_epochs"]):
for batch_id, data in enumerate(train_reader()):
dy_x_data = np.array([x[0] for x in data]).astype(‘float32‘)
y_data = np.array([x[1] for x in data]).astype(‘int64‘)
y_data = y_data[:, np.newaxis]
# 将Numpy格式数据转换成dygraph接收的输入
img = fluid.dygraph.to_variable(dy_x_data)
label = fluid.dygraph.to_variable(y_data)
out, acc = vgg(img, label)
loss = fluid.layers.cross_entropy(out, label)
avg_loss = fluid.layers.mean(loss)
# 使用backward()方法执行反向传播
avg_loss.backward()
optimizer.minimize(avg_loss)
# 将参数梯度清零保证下一轮训练的正确性
vgg.clear_gradients()
# 记录训练中计算的数据,用于可视化
all_train_iter = all_train_iter + train_parameters["train_batch_size"]
all_train_iters.append(all_train_iter)
all_train_costs.append(loss.numpy()[0])
all_train_accs.append(acc.numpy()[0])
if batch_id % 10 == 0:
print(‘Loss at epoch {} step {}: {}, acc: {}‘.format(epoch_num,
batch_id,
avg_loss.numpy(),
acc.numpy()))
# 调用参数可视化函数进行参数可视化
draw_train_process(‘training‘, all_train_iters, all_train_costs, all_train_accs, ‘training cost‘, ‘traing_acc‘)
draw_process(‘training loss‘, ‘red‘, all_train_iters, all_train_costs, ‘training loss‘)
draw_process(‘training acc‘, ‘green‘, all_train_iters, all_train_accs, ‘training acc‘)
# 保存模型参数
fluid.save_dygraph(vgg.state_dict(), ‘vgg‘)
print(‘Final loss: {}‘.format(avg_loss.numpy()), ‘\nEnd of training‘)
参数可视化:
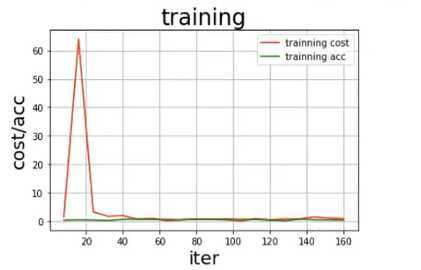
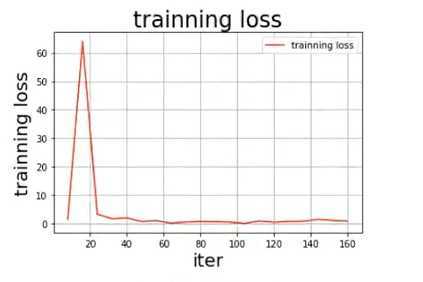
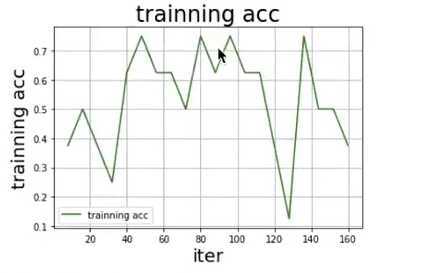
# 模型校验
with fluid.dygraph.guard():
model, _ = fluid.load_dygraph(‘vgg‘)
vgg = VGGNet()
vgg.load_dict(model)
vgg.eval()
accs = []
for batch_id, data in enumerate(eval_reader()):
dy_x_data = np.array([x[0] for x in data]).astype(‘float32‘)
y_data = np.array([x[1] for x in data]).astype(‘int64‘)
y_data = y_data[:, np.newaxis]
img = fluid.dygraph.to_variable(dy_x_data)
label = fluid.dygraph.to_variable(y_data)
out, acc = vgg(img, label)
lab = np.argsort(out.numpy())
accs.append(acc.numpy()[0])
print(‘验证集平均准确率: ‘, np.mean(accs))
def load_image(img_path):
# 预测图像预处理
img = Image.open(img_path)
if img.mode != ‘RGB‘:
img = img.convert(‘RGB‘)
img = img.resize((224, 224), Image.BILINEAR)
img = np.array(img).astype(‘float32‘)
img = img.transpose((2, 0, 1))
img = img / 255
return img
label_dict = train_parameters[‘label_dict‘]
with fluid.dygraph.guard():
model, _ = fluid.dygraph.load_dygraph(‘vgg‘)
vgg = VGGNet()
vgg.load_dict(model)
vgg.eval()
# 可视化预测图片
infer_path = ‘./2.jpg‘
img = Image.open(infer_path)
plt.imshow(img)
plt.show()
# 对预测图像进行处理
infer_imgs = [load_image(infer_path)]
infer_imgs = np.array(infer_imgs)
for i in range(len(infer_imgs)):
data = infer_imgs[i]
dy_x_data = np.array(data).astype(‘float32‘)
dy_x_data = dy_x_data[np.newaxis, :, :, :]
img = fluid.dygraph.to_variable(dy_x_data)
out = vgg(img)
lab = np.argmax(out.numpy) # argmax()返回最大数的索引
print(‘第{}个样本,被预测为: {}‘.format(i+1, label_dict[str(lab)]))
print(‘预测结束‘)
测试图像:

训练过程与结果预测:
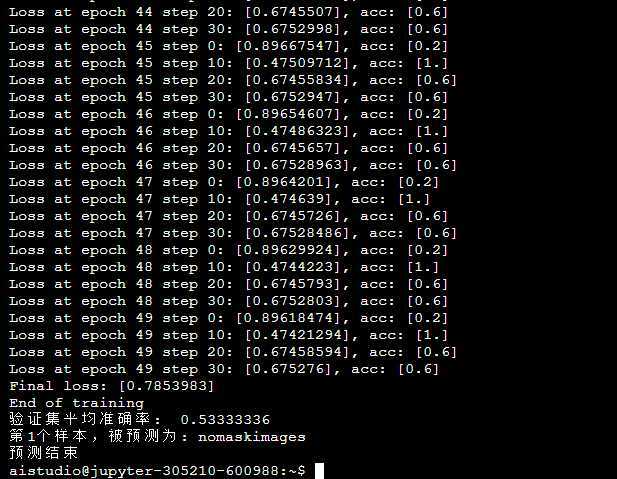
说明:相对于数据集(较小)来言,vgg16网络模型是一个十分复杂的模型,所以模型训练的最终结果并不理想,如果使用更大的数据集会得到更可观的训练效果。
百度paddle框架学习(二):使用经典VGG网络完成人脸口罩判别
原文:https://www.cnblogs.com/horacle/p/13212692.html