机器学习(machinelearning):从数据中学习得到某种规律的学科,以数据驱动的学习。
机械学习:单纯记忆数据的学习方式,即死记硬背。
模型(model):通常指我们要学习得到的函数或是映射,接受输入得到输出的转换规律,我们的目标就是得到这样的规律,不断拟合和逼近已知的数据。
经验风险/结构风险:由于数据的分布不总是符合理论分布(数据量小且有误差存在),在机器学习中经常要对预测的结果和实际结果之间的差距进行评估,于是引出了误差函数,即为经验风险或者结构风险。
深度学习(DeepLearning):利用多层神经网络以及负向反馈算法(BP)等技巧来进行学习的方法,是机器学习的一种分支。

监督学习(supervised learning):从带有标签的数据样本中进行学习(标注数据),往往用于分类、预测等问题。监督学习有两个主要的方向:分类和回归。
无监督学习:从无标签数据中进行学习(非标注数据),往往用于聚类(自动分类)、规律总结(往往我们不知道规律是什么)等问题。
可以查询演绎和归纳两种科学学习思想。
数据所表示的样本的某些属性值则被称为特征(feature), 对应所给的概括或者说明(定义样本是什么的标注,或者我们要预测的数值)就是标记(label)
我们要找的模型就是能够接受组特征然后给出预测的标签的函数。
分类和回归:根据输出值类型的不同,监督学习主要有两个方面的应用:分类和回归问题。
分类问题中预测的值是离散值,一般取值的个数是有限的,比如性别、职业、省份等;回归问题中预测的值是连续值,一般取值是无限的,比如身高体重收入等。
特征按照取值个数是否有限也分为连续型特征和离散型特征。
训练集和测试集:训练集是选取的用于训练得出模型的数据集合,测试集是用于测试模型能力的数据集合。
泛化能力:模型在非训练集数据上的计算效果,体现模型对于未知的数据的计算正确性。
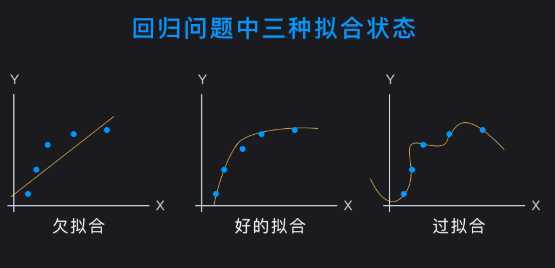
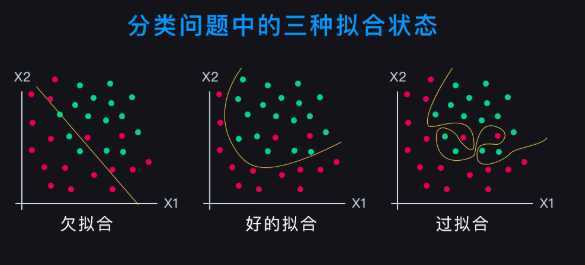
过拟合:模型过多地学习了一些不必要的特征,即过分拟合于训练集的数据,比如本来应当依照体重和身高判断健康状况,训练集中体重瘦于平均水平的人多,最后模型会倾向于判断体重较轻的人健康,甚至可能认为一些不必要的特征(比如教育水平)也会对结果产生影响;在对树叶进行学习的时候认为不仅是绿色的,而且要带有锯齿形状的物体才是树叶等
欠拟合; 拟合能力过差导致模型泛化能力低下,上述学习分辨叶子的实验中认为绿色的物体就是叶子等。
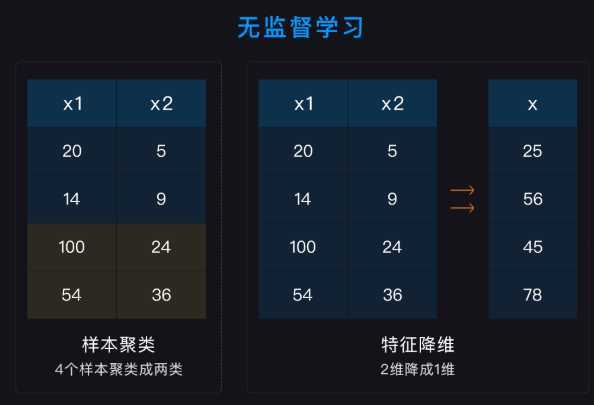
无监督学习应用主要有样本聚类和特征降维。
模型参数(model parameter): 指模型有关的量化数值,是和数据以及模型本身的数学关系有关的。
超参数: 人为设定的一些参数,比如学习率、迭代次数epoch等
原文:https://www.cnblogs.com/zy1120192493/p/13213627.html