流处理,对kafka产生的数据流进行处理:
val lines = kafkaStream.flatMap { batch =>
batch.value().split("\n")
}
// 用正则匹配将日志格式化,并同时完成日期时间转时间戳
val simpleDateFormat = new SimpleDateFormat("dd/MMM/yyyy:HH:mm:ss Z", Locale.ENGLISH)
val logRecords = lines.map { row =>
val pattern: Regex = """^(\S+) (\S+) (\S+) \[([\w:/]+\s[+\-]\d{4})\] "(\S+)\s?(\S+)?\s?(\S+)?" (\d{3}|-) (\d+|-)\s?"?([^"]*)"?\s?"?([^"]*)?"?$""".r
val options = pattern.findFirstMatchIn(row)
if (options.isDefined) {
// 若匹配,返回格式化日志结构
val matched = options.get
log(matched.group(1), matched.group(2), matched.group(3),
String.valueOf(simpleDateFormat.parse(matched.group(4)).getTime),
matched.group(5), matched.group(6), matched.group(7), matched.group(8), matched.group(9))
}
else {
// 若不匹配,用空值跳过
log("foo", "foo", "foo", "0", "foo", "foo", "foo", "foo", "0")
}
}
上面就是对kafka产生的数据流处理,kafka的数据流是直接产生到log文件里面的。根据换行符分隔成一个日志数组。经过正则匹配得到日志的其他部分。
接下来就是对获得的信息进行一个统计了。

可以将统计的信息放到redis里面进行存储。
接下来就是利用逻辑回归模型对日志分类了。根据learning文件里面提供的接口进行调用。
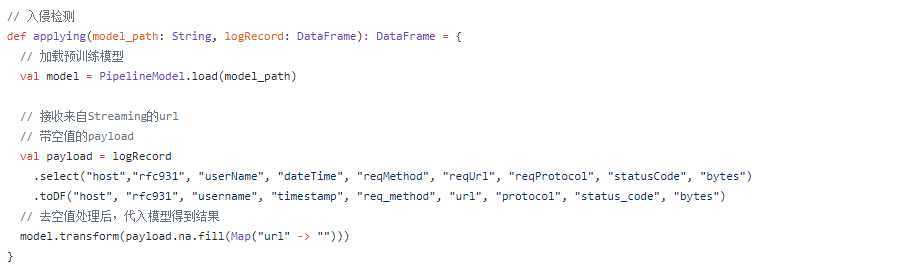
model.transform是模型开始处理数据的方法,括号中的是对数据进行了一定的处理,将url为空值的数据替换为了""
原文:https://www.cnblogs.com/blog-lmk/p/13215036.html