第一个真正意义上将深度学习一个用在图像增强上的网络。
图像来源于网络上的开源数据集,将原始的数据集划分为训练集和测试集。
训练集的数据从图像中提取了422500个点,然后将这些图像像素数据归一化到[0,1]区间中。原始的图像是正常光照下的,论文这里是采用MATLAB中的-imadjust将图像进行伽马非线性调暗。
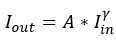
γ<1,图片变亮;γ=1,图片不变;γ>1,图片变暗。
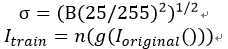
B在(0,1)区间内,n(·)为噪音函数,g(·)为伽马调暗函数。
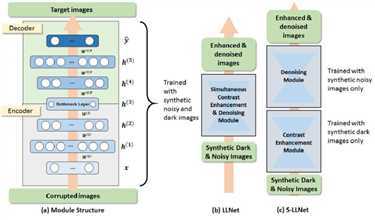
采用三层去噪自动编码器(DA)堆叠起来作为encoder,每个DA的损失函数为:
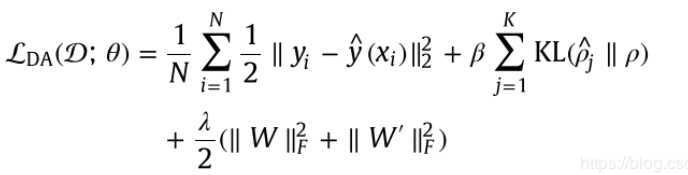
其中,N是patch数,θ是模型参数矩阵,λ、β、是交叉验证的参数,KL是散度函数,用于计算隐藏层中的稀疏性:
![]()
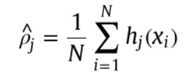
整个网络结构称为堆叠稀疏去噪自动编码器(SSDA),其损失函数为:
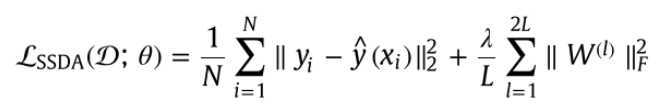
LLNET:将调暗并带有噪音的图片作为输入进行训练。
S-LLNET:将调暗的图片和带有噪音的图片分别输入进行训练。
PSNR量化含有噪声图像的失真程度,PSNR值越大,图片的降噪效果越好。
SSIM被用来评价两幅图片的相似相似度。
定义γ=3,=18或25,分别测试了在正常光、暗光、噪点、暗光加噪点情况下的几组图片。结果如下:
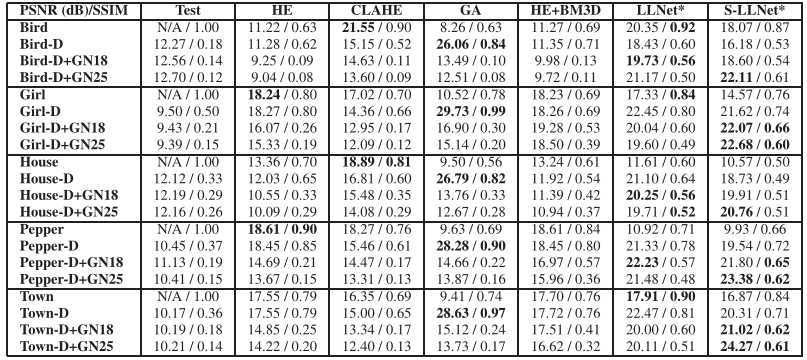
作者通过实验得到,增加DA层的数量可以提升网络的性能,但是减小padding stride的尺寸并不能提升网络性能。
原文:https://www.cnblogs.com/codejess/p/13215355.html