KafKa的基本认识,写的很好的一篇博客
https://www.cnblogs.com/sujing/p/10960832.html
问题:
1、kafka是什么?
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据,具有高性能、持久化、多副本备份、横向扩展能力。
2、kafka的工作原理
Kafka采用的是点对点的模式,消费者主动的去kafka集群拉取消息,与producer相同的是,消费者在拉取消息的时候也是找leader去拉取。
- kafka节点之间如何复制备份的?
- kafka消息是否会丢失?为什么?
- kafka最合理的配置是什么?
- kafka的leader选举机制是什么?
- kafka对硬件的配置有什么要求?
- kafka的消息保证有几种方式?
- kafka为什么会丢消息?
Kafka使用场景
1.为何使用消息系统
2.我们为何需要搭建Apache Kafka分布式系统
3.消息队列中点对点与发布订阅区别
1 Kafka简介
Kafka:是一个高吞吐量、分布式的发布-订阅消息系统。kafka是一款开源的、轻量级的、分布式、可分区和具有复制备份[Replicated]的、基于Zookeeper协调管理的分布式流平台的功能强大的消息系统。
Kafka特性:
- 能够允许发布和订阅流数据
- 存储流数据时提供相应的容错机制
- 当流数据到达时能够被及时处理[近乎实时性的消息处理能力,可以高效地存储消息和查询消息]
Kafka消息系统最基本的体系结构: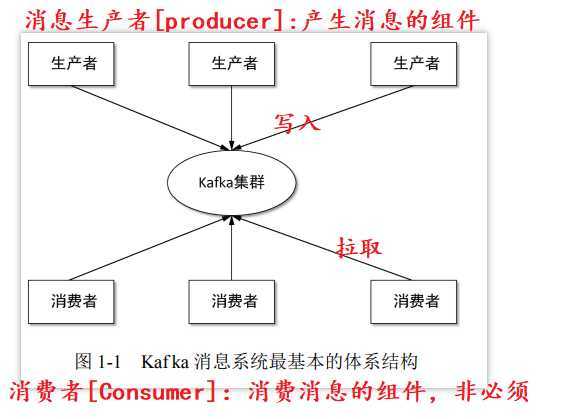
Kafka基本概念[核心概念]:
- Topic& 分区 &Log:Topic 是用于存储消息的逻辑概念,可以看作一个消息集合。每个 Topic 可以有多个生产者向其中推送(push)消息,也可以有任意多个消费者消费其中的消息。每个分区[对应一个磁盘的文件夹]由一系列有序、不可变的消息组成,是一个有序队列。Log 由多个 Segment 组成,每个 Segment 对应一个日志文件和索引文件。每个分区在物理上对应为一个文件夹,分区的命名规则为主题名称后接“—”连接符,之 后再接分区编号,分区编号从 0 开始,编号最大值为分区的总数减 1。日志段:一个日志又被划分为多个日志段(LogSegment)[逻辑概念],日志段是 Kafka 日志对象分片的最小单位。一个日志段对应磁盘上一个具体日志文件和 两个索引文件。日志文件是以“.log”为文件名后缀的数据文件,用于保存消息实际数据。两个索引文件分别以“.index”和“.timeindex”作为文件名后缀,分别表示消息偏移量索引文件和消息时间戳索引文件。
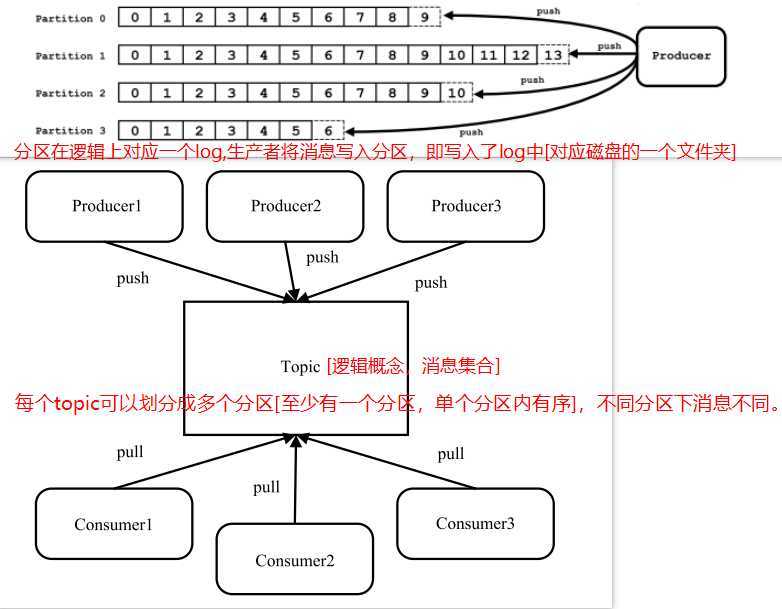
- 消息:Kafka通信的基本单位,消息由一串字节构成,其中主要由 key 和 value 构成,key 和 value 也都是 byte 数组。key的主要作用是根据一定的策略,将此消息路由到指定的分区中,这样就可以保证包含同一 key 的消息全部写入同一分区中,key 可以是 null。消息的真正有效负载是 value 部分的数据。
- 副本:每个 Partition 可以有多个副本,每个副本中包含的消息是一样的。每个分区至少有一个副本,当分区中只有一个副本时,就只有 Leader 副本,没有 Follower 副本。所有的读写请求都由选举出 的 Leader 副本处理,其他都作为 Follower 副本,Follower 副本仅仅是从 Leader 副本处把数据拉取到本地之后,同步更新到自己的 Log 中。Kafka 提供两种删除老数据的策略, 一是基于消息已存储的时间长度,二是基于分区的大小。
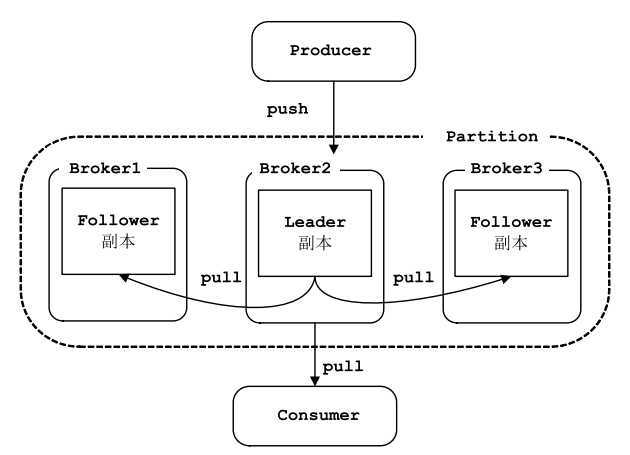
- 偏移量:任何发布到分区的消息会被直接追加到日志文件(分区目录下以“.log”为文件名后缀的 数据文件)的尾部,而每条消息在日志文件中的位置都会对应一个按序递增的偏移量。
- 代理:每一个Kafka实例称为代理(Broker),也称为kafka服务器。Kafka集群一般包含一台或多台服务器,可以在一台服务器上配置一个或多个代理。
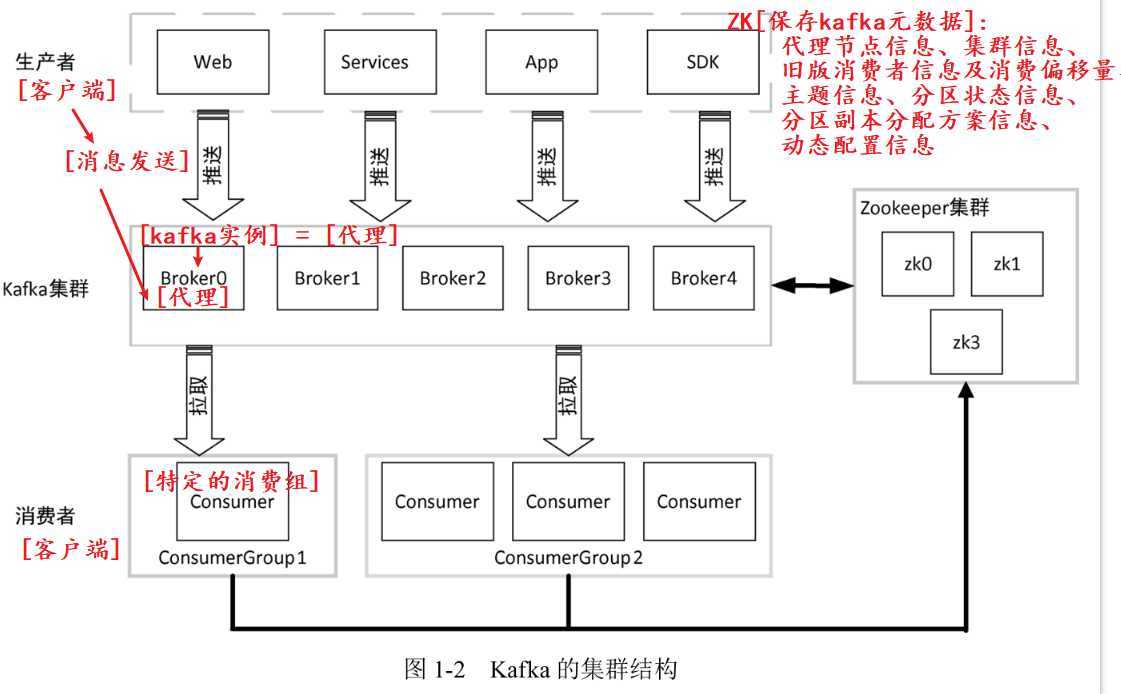
- 生产者:将消息发给代理,也就是向Kafka代理发送消息的客户端。
- 消费者和消费组:消费者(Comsumer)以拉取(pull)方式拉取数据,它是消费的客户端。在 Kafka 中每一 个消费者都属于一个特定消费组(ConsumerGroup),我们可以为每个消费者指定一个消费组, 以 groupId 代表消费组名称,通过 group.id 配置设置。
- ISR:Kafka 在 ZooKeeper 中动态维护了一个 ISR(In-sync Replica),即保存同步的副本列表,该 列表中保存的是与 Leader 副本保持消息同步的所有副本对应的代理节点 id。ISR(In-Sync Replica)集合表示的是目前“可用”(alive)且消息量与 Leader 相差不多的副本集合,这是整个副本集合的一个子集。
- ZooKeeper:Kafka 利用 ZooKeeper 保存相应元数据信息,Kafka元数据信息包括如代理节点信息、Kafka 集群信息、旧版消费者信息及其消费偏移量信息、主题信息、分区状态信息、分区副本分配方 案信息、动态配置信息等。
Kafka集群架构:根据业务逻辑产生消息,在根据路由规则将消息发送到指定分区的Leader副本所在的Broker上。
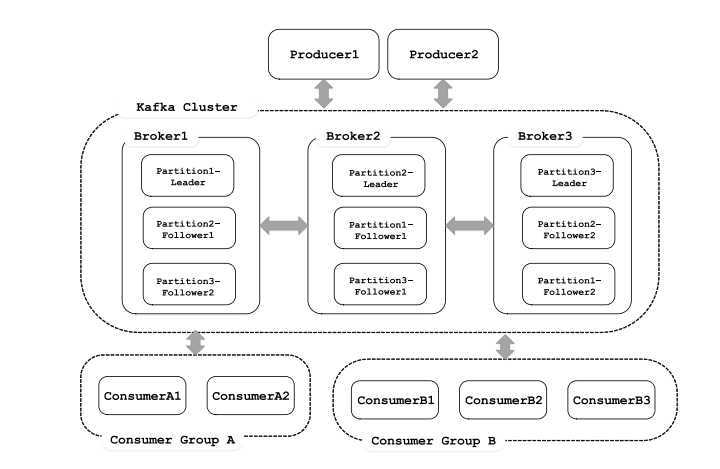
Kafka设计概述:
- 动机:统一、实时处理大规模数据的平台。[类似数据库日志系统]
- (1)具有高吞吐量来支持诸如实时的日志集这样的大规模事件流。
- (2)能够很好地处理大量积压的数据,以便能够周期性地加载离线数据进行处理。
- (3)能够低延迟地处理传统消息应用场景。
- (4)能够支持分区、分布式,实时地处理消息,同时具有容错保障机制。
- 特性:消息持久化、高吞吐量、扩展性、多客户端支持、Kafka Streams、安全机制、数据备份、轻量级、消息压缩。
- (1)消息持久化:Kafka 高度依赖于文件系统来存储和缓存消息。
- (2)高吞吐量:Kafka 将数据写到磁盘,充分利用磁盘的顺序读写。 同时,Kafka 在数据写入及数据同步采用了零拷贝(zero-copy)技术,完全在内核中操作,从而避免了内核缓冲区与用户缓冲区之间数据的拷贝,操作效率极高。Kafka 还支持数据压缩及批量发送,同时 Kafka 将每个主题划分为多个分区。
- (3)扩展性:集群能够自动感知,重新进行负责均衡及数据复制。
- 应用场景:
- (1)消息系统。[在应用系统中可以将kafka作为传统的消息中间件,实现消息队列和消息的发布/订阅]
- (2)应用监控。
- (3)网站用户行为追踪。[用作日志收集中心,多个系统产生的日志统一收集到Kafka中,然后由数据分析平台进行统一处理]
- (4)流处理。
- (5)持久性日志。[Kafka 可以为外部系统提供一种持久性日志的分布式系统。日志可以在多个节点间进行备份,Kafka为故障节点数据恢复提供了一种重新同步的机制。]
- (6)kafka用作系统中的数据总线,将其接入多个子系统中,子系统会将产生的数据发送到kafka中保存,之后流转到目的系统中。
KafKa的基本认识
原文:https://www.cnblogs.com/wendyw/p/13034083.html