Description of Java Conceptual Diagram(java结构)
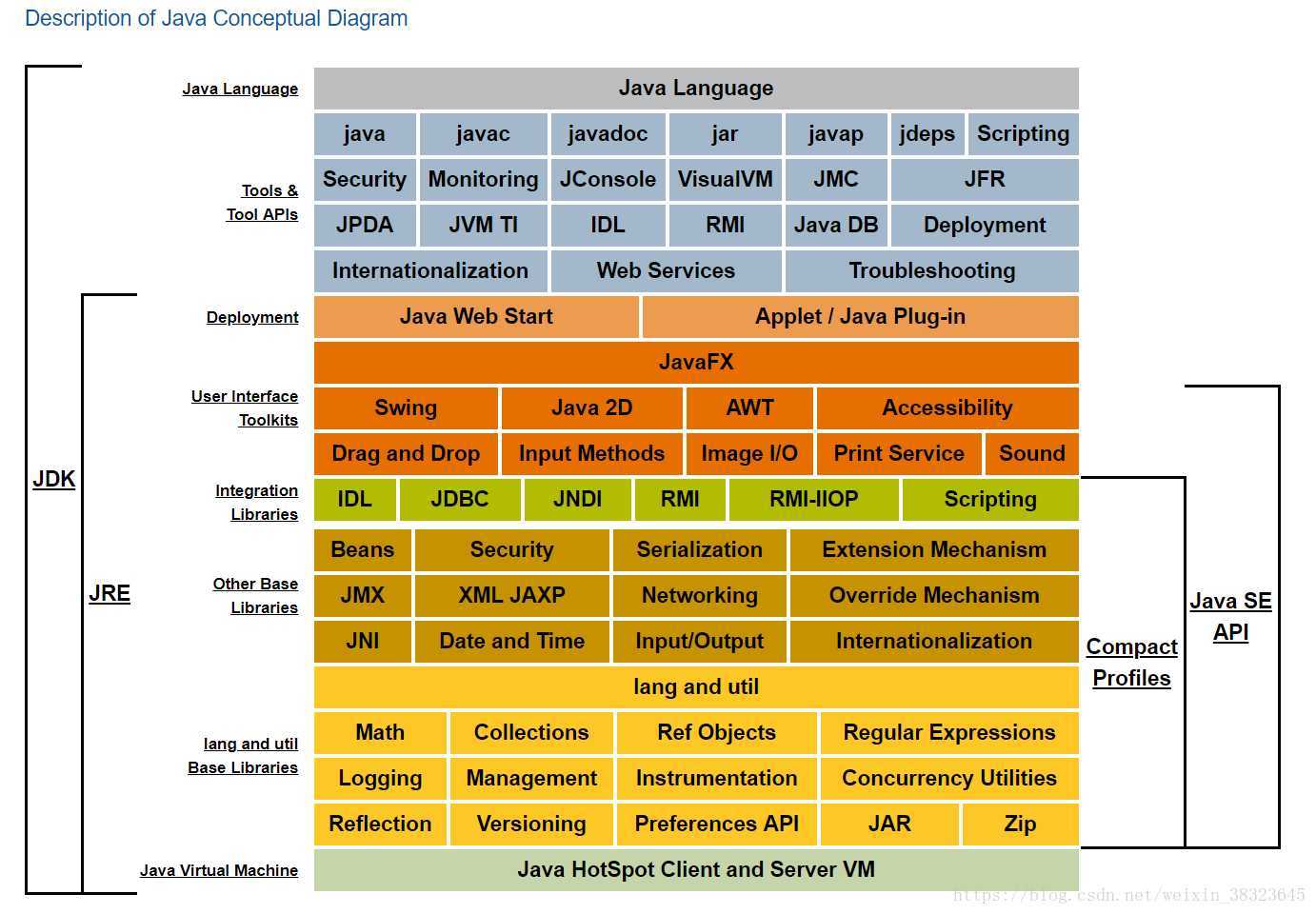
以上就是java结构体系, 主要由两部分构成,
第一部分是java 工具(Tools&Tool APIs), 比如java命令, javac, javap命令.
第二部分是: JRE,也就是java running enveriment. jre是Java的核心, 里面定义了java运行时需要的核心类库, 比如:我们常用的lang包, util包, Math包, Collection包等等.这里还有一个很重要的部分JVM(最后一部分青色的) ava 虚拟机, 这部分也是属于jre, 是java运行时环境的一部分.
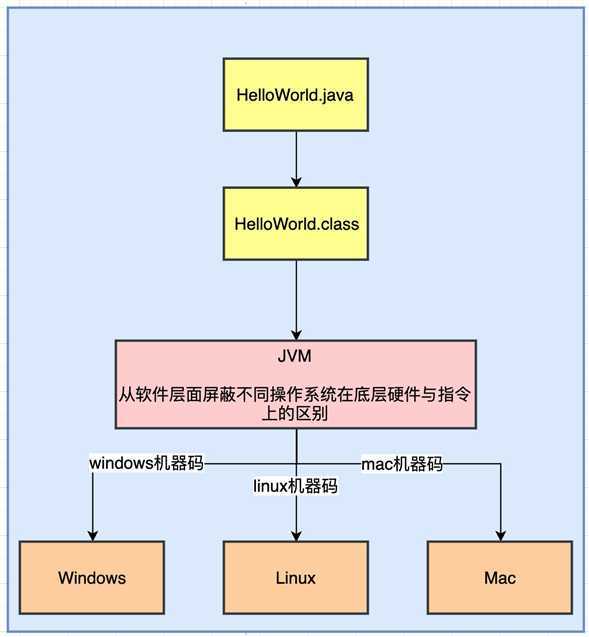
我们来简单看一下java语言是如何实现跨平台的特性的?
跨平台指的是, 程序员开发出的一套代码, 在windows平台上能运行, 在linux上也能运行, 在mac上也能运行. 我们都知道, 机器最终运行的指令都是二进制指令. 但是同样的代码, 在windows上生成的二进制指令可能是1101, 但是在linux上是1201, 而在mac上是1301. 这样同样的代码, 如果要想在不同的平台运行, 放到相应的平台, 还要修改代码, 那么java跨平台特性是怎么做到的呢?
原因在于jdk, 我们最终是将程序编译成二进制码,把他丢在jvm上运行的, 而java虚拟机是jre的一部分. 我们在不同的平台下载的jdk是不同的. windows平台要选择下载适用于windows的jdk, linux要选择适用于linux的jdk, mac要选择适用于mac的jdk. 不同平台的jvm针对该平台有一个特定的实现
JVM有三块组成: 类装载子系统, 运行时数据区(内存模型) , 字节码执行引擎
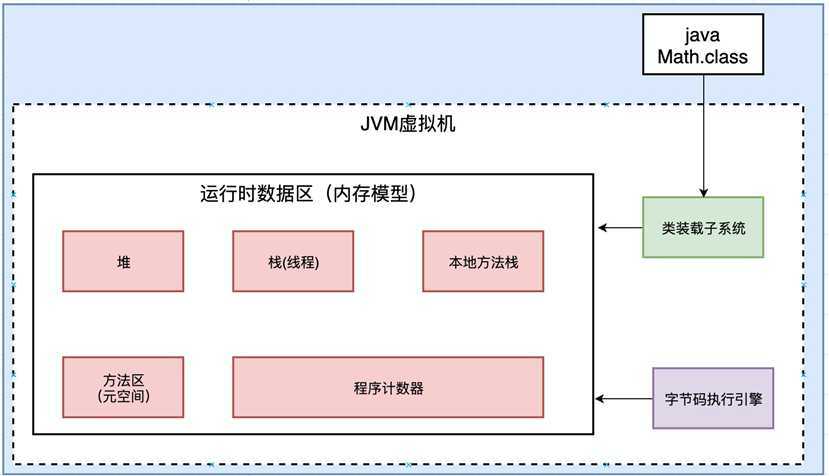
其中类装载子系统是C++实现的, 他把类加载进来,放入到虚拟机中. 然后, 字节码执行引擎去虚拟机中读取数据. 字节码执行引擎也是c++实现的. 我们重点研究运行时数据区
我们举个例子来说一下:
package com.lxl.jvm; public class Math { public static int initData = 666; public static User user = new User(); public int compute() { int a = 1; int b = 2; int c = (a + b) * 10; return c; } public static void main(String[] args) { Math math = new Math(); math.compute(); } }
当我们在执行main方法的时候, 都做了什么事情呢?
第一步: 由类加载子系统加载Math.class类, 然后将其丢到内存区域, 这个就是前面博客研究的部分,类加载的过程, 我们看源码也发现,里面好多代码都是native本地的, 是c++实现的
第二步: 在内存中处理字节码文件
第三步: 由字节码执行引擎执行java虚拟机中的内存代码, 而字节码执行引擎也是由c++实现的
这里最核心的部分是第二部分运行时数据区(内存模型), 我们后面的调优, 都是针对这个区域来进行的.
下面详细来说内存区域
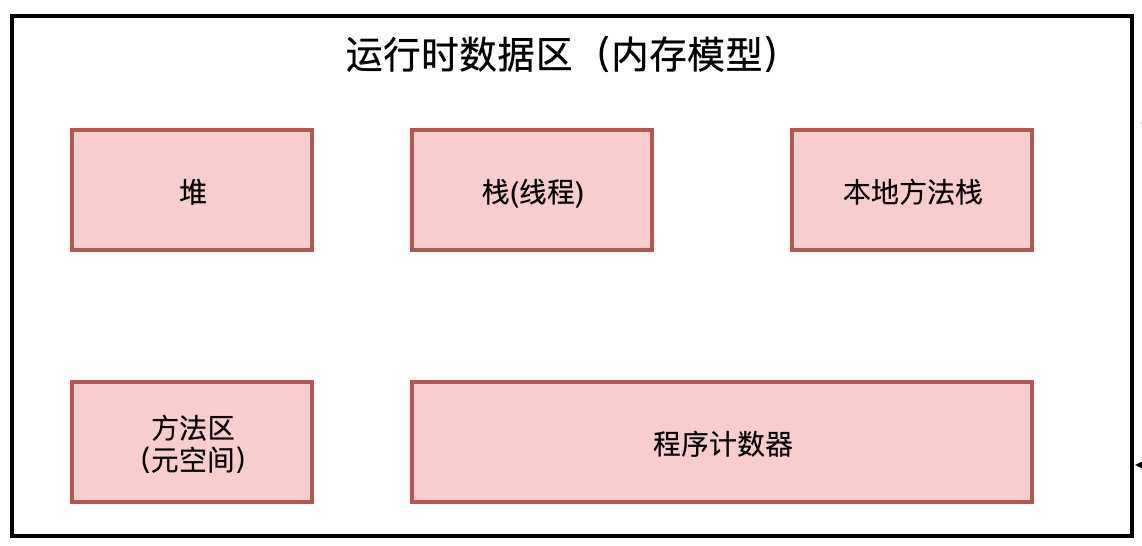
这是java的内存区域, 内存区域干什么的呢?内存区域其实就是放数据的,各种各样的数据放在不同的内存区域
先来说说栈:
还是用Math的例子来说
当程序运行的时候, 会创建一个线程, 创建线程的时候, 就会在大块的栈空间中分配一块小空间, 用来存放当前要运行的线程的变量
public static void main(String[] args) { Math math = new Math(); math.compute(); }
这段代码要运行,首先会在大块的栈空间中给他分配一块小空间. 比如这里的math这个局部变量就会被保存在分配的小空间里面.
在这里面我们运行了math.compute()方法, 我们看看compute方法内部
public int compute() { int a = 1; int b = 2; int c = (a + b) * 10; return c; }
里面还有a, b, c这样的局部变量, 这些局部变量放在那里呢? 就放在上面分配的栈小空间里面.
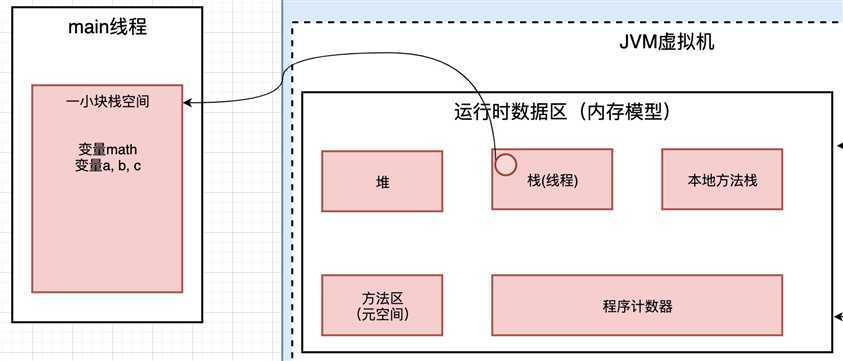
效果如上图, 在栈空间中, 分配一块小的区域, 用来存放Math类中的局部变量
如果再有一个线程呢? 我们就会再次在栈空间中分配一块小的空间, 用来存放新的线程内部的变量
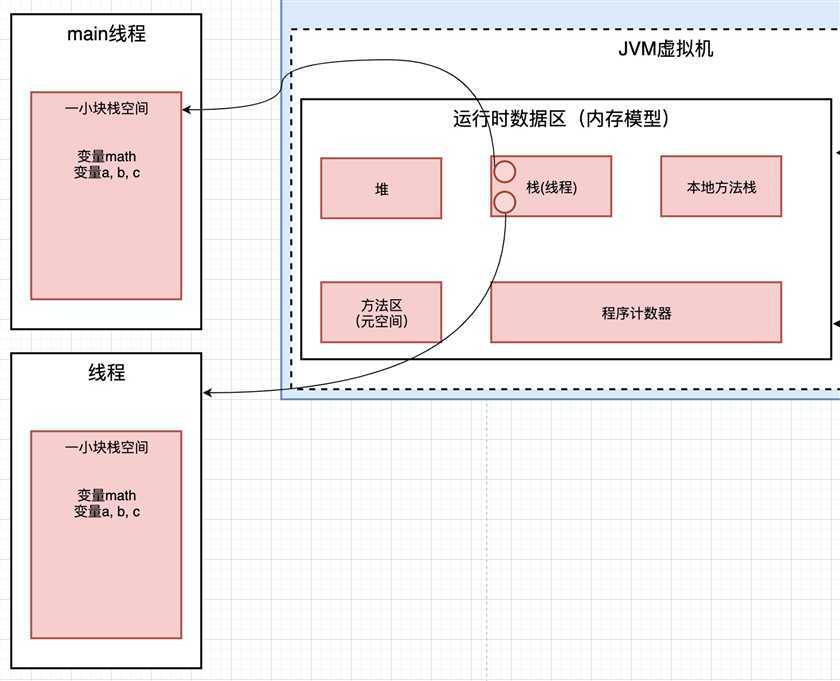
什么是栈帧呢?
package com.lxl.jvm; public class Math { public static int initData = 666; public static User user = new User(); public int compute() { int a = 1; int b = 2; int c = (a + b) * 10; return c; } public static void main(String[] args) { Math math = new Math(); math.compute(); } }
还是这段代码, 我们来看一下, 当我们启动一个线程运行main方法的时候, 首先会在占空分配一块区域,叫做栈帧空间.
二当程序运行的compute()计算方法的时候, 又要去调用compute()方法, 这时候会在分配一个栈帧空间.
为什么要将一个线程中的不同方法放在不同的栈帧里面呢?
一方面: 我们不同方法里的局部变量是不能相互访问的. 比如compute的a,b,c在main里能访问么? 当然不能, 使用栈帧做了很好的隔离作用
另一方面: 方便垃圾回收, 我的一个方法用完了, 就返回了, 拿着里面的变量就是垃圾了, 后面直接回收这个栈帧就好了.
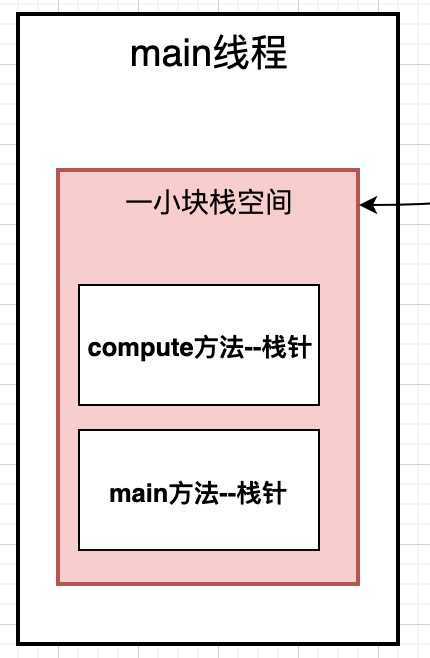
如下图, 在Math中两个方法, 当运行到main方法的时候, 会将main方法放到一块栈针空间, 这里面仅仅是保存main方法中的局部变量, 当执行到compute方法的时候, 这时会开辟一块compute栈针空间, 这部分空间仅存放compute()方法的局部变量. 这样做的好处是什么呢?
不同的方法开辟出不同的内存空间, 这样方便我们各个方法的局部变量进行管理, 同时也方便与垃圾回收, 不用了, 就可以被回收掉了.
我们学过栈算法, 栈算法是先进后出的. 那么我们的内存模型里的栈和算法里的栈一样么?有关联么?
我们java内存模型中的栈使用的就是栈算法, 现金后出
as
原文:https://www.cnblogs.com/ITPower/p/13222648.html