需求:爬取这国内、国际、军事、航空、无人机模块下的新闻信息
1.找到这五个板块对应的url
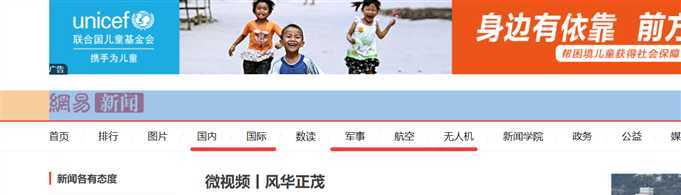
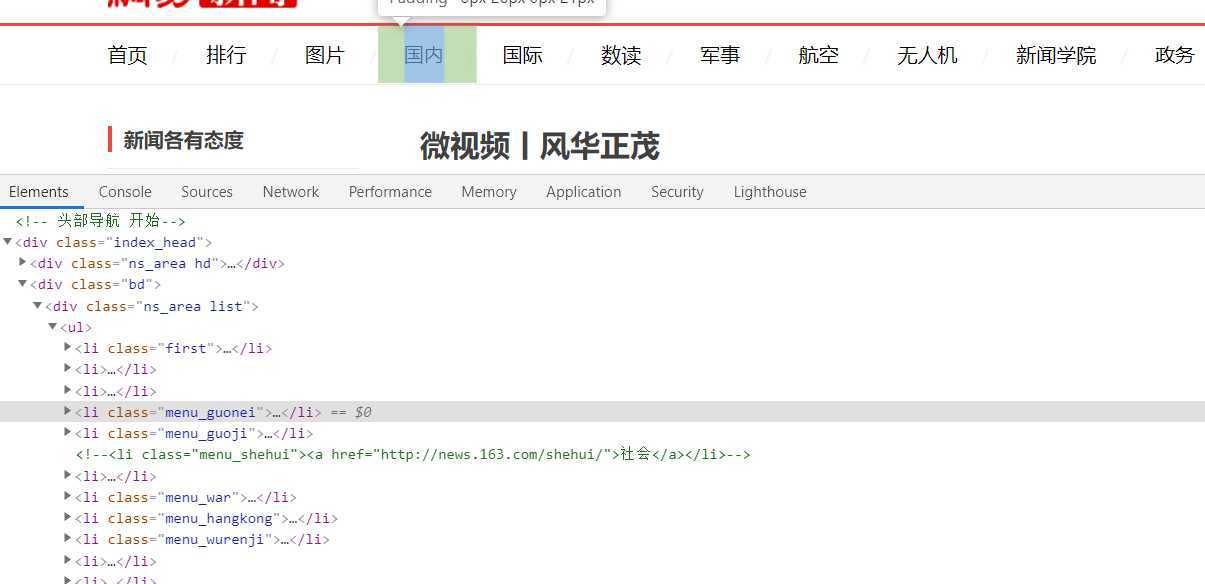
2.进入每个模块请求新闻信息
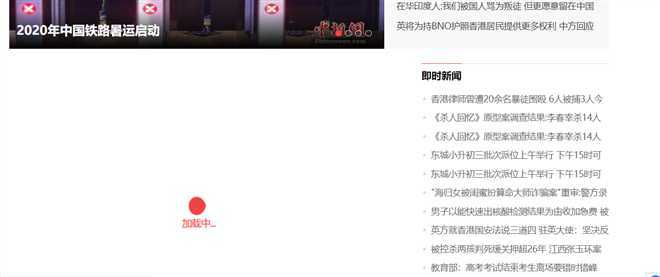
我们可以明显发现‘’加载中‘’,因此我们判断新闻数据是动态加载出来的。
3.拿到新闻的标题和详情url
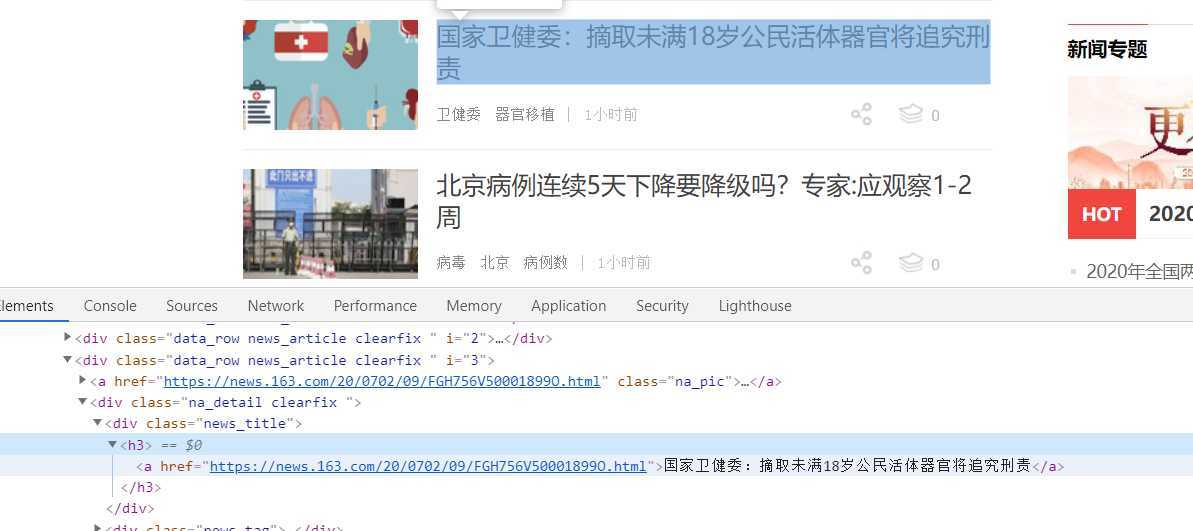
4.请求详情页 获取新闻内容
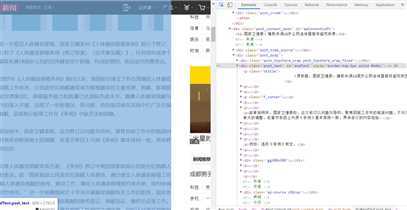
5.思路:思路已经很清晰了,请求五大板块拿到五大板块的详情页,获取每一个板块下的新闻标题和新闻详情页url,再对新闻详情页请求拿到新闻的内容。
需要注意的一点是,新闻都是动态加载出来的,因此我们用selenium来抓取新闻的数据。
6.代码实现
爬虫文件: wangyi.py
# -*- coding: utf-8 -*- import scrapy from selenium import webdriver from wangYi.items import WangyiItem class WangyiSpider(scrapy.Spider): name = ‘wangyi‘ # allowed_domains = [‘www.xxx.com‘] start_urls = [‘https://news.163.com/‘] urls = [] def __init__(self): self.bro = webdriver.Chrome(executable_path=‘D:\OldBoy_Luffy\code_practice\chapter11\爬虫\scrapy框架\chromedriver.exe‘) def parse(self, response): li_list = response.xpath(‘//*[@id="index2016_wrap"]/div[1]/div[2]/div[2]/div[2]/div[2]/div/ul/li‘) # 五大模块所在li标签的索引 index_list = [3,4,6,7,8] # 获取五大模块的url for index in index_list: model_src = li_list[index].xpath(‘./a/@href‘).extract_first() self.urls.append(model_src) # 发送请求 for url in self.urls: yield scrapy.Request(url=url, callback=self.parse_model) def parse_model(self,response): item = WangyiItem() # 每条新闻所在的div标签 div_list = response.xpath(‘/html/body/div/div[3]/div[4]/div[1]/div/div/ul/li/div/div‘) for div in div_list: # 获取标题与详情页的url title = div.xpath(‘./div/div[1]/h3/a/text()‘).extract_first() detail_url = div.xpath(‘./div/div[1]/h3/a/@href‘).extract_first() item[‘title‘] = title # 部分的新闻中可能会有广告信息 因此可能会匹配为空 跳过循环 if detail_url is None: continue # 请求详情页 请求传参 yield scrapy.Request(url=detail_url, callback=self.detail_parse,meta={‘item‘:item}) def detail_parse(self,response): item = response.meta[‘item‘] # 获取新闻内容 content = response.xpath(‘//div[@id="endText"]//text()‘).extract() content = ‘‘.join(content) item[‘content‘] = content # 存入管道 yield item def closed(self,spider): # 重写父类方法 爬虫结束时执行 self.bro.quit()
中间件middlewares.py
def process_response(self, request, response, spider): # spider就是爬虫文件中 爬虫类的实例化对象 # 拿到浏览器对象 bro = spider.bro if request.url in spider.urls: # 获取动态加载的数据 bro.get(request.url) page_text = bro.page_source # 封装成响应对象返回 new_response = HtmlResponse(url=request.url,body=page_text,encoding=‘utf-8‘,request=request) return new_response else: return response
items.py
class WangyiItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title = scrapy.Field() content = scrapy.Field()
pipelines.py
class WangyiPipeline: def open_spider(self,spider): self.fp = open(‘news.txt‘,‘w‘,encoding=‘utf-8‘) print(‘爬取开始...‘) def process_item(self, item, spider): title = item[‘title‘] content = item[‘content‘] if title is None: title=‘‘ if content is None: content = ‘‘ self.fp.write(title+‘\n‘+content) return item def close_spider(self,spider): self.fp.close() print(‘爬取结束‘)
原文:https://www.cnblogs.com/sxy-blog/p/13216168.html