在做深度学习相关实验时,我一般会直接在本机 Linux 环境下进行,因为我需要基于 cuda 来启用 GPU 运算。考虑到经常还要迁移到面向客户PC机的智能服务,所以我偶尔也会选择在 Windows 上进行。在 Windows 10 中自从有了 WSL,我的选择是使用 WSL 远程连接高性能服务器,这样才能保持研发体验的一致性,我特别期望能摆脱这样的麻烦,如果能在Windows 10 本地切换一个 Linux系统又能使用 cuda 就好了,幸运的消息是,最新的 Windows 10 的更新推出 WSL2 对 cuda 的支持,我迫不及待地做了一下基准测试,想比较一下不同环境的性能表现。
我选择的几个系统环境是这样:
主要硬件配置是这样:
测试用的深度学习模型我使用的是最经典的MNIST,我比较熟悉Pytorch所以代码我采用了这个示例仓库,我修改了部分代码如下,让网络模型更大以获得更准确的读数。
class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(1, 128, 3, 1) self.conv2 = nn.Conv2d(128, 128, 3, 1) self.conv3 = nn.Conv2d(128, 128, 3, 1) self.dropout1 = nn.Dropout2d(0.25) self.dropout2 = nn.Dropout2d(0.5) self.fc1 = nn.Linear(15488, 15488//2) self.fc2 = nn.Linear(15488//2, 10) def forward(self, x): x = self.conv1(x) x = F.relu(x) x = self.conv2(x) x = F.relu(x) x = self.conv3(x) x = F.relu(x) x = F.max_pool2d(x, 2) x = self.dropout1(x) x = torch.flatten(x, 1) x = self.fc1(x) x = F.relu(x) x = self.dropout2(x) x = self.fc2(x) output = F.log_softmax(x, dim=1) return output
其中batch size我设为512,epochs设为14,以precision为FP32运行,结果对比如下:
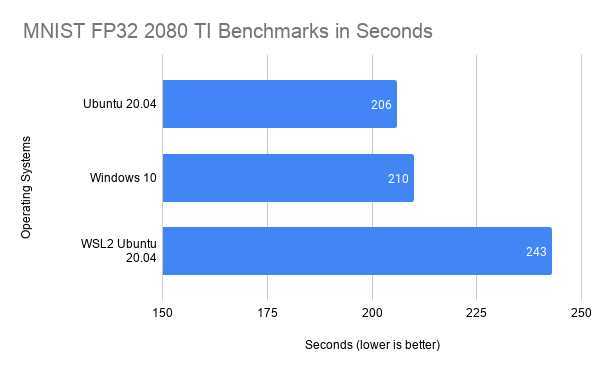
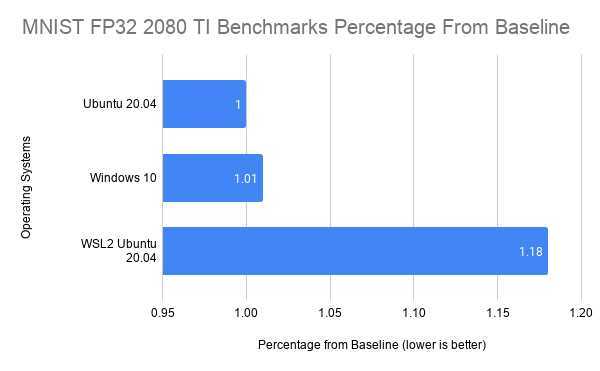
哈哈,老实说结果还凑合!WSL2 在启用 cuda 支持后比本机 Ubuntu 环境下多消耗了18%,要知道这是在 Nvidia Rtx 2080 Ti 上训练模型。目前 WSL2 对 cuda 的支持仍处于早期预览模式,期待各路工程师、研究员大神们,以及微软和 Nvidia 再打磨下,尽快达到接近本机 Ubuntu 性能的水平。如果对训练时长消耗特别严格的研究(比如海量图像、语料)来说,多花18%是很难接受的,但对我来说,训练样本数据都还比较小,一般也就到2G差不多了,所以我可以稍稍牺牲下操作系统层面的性能,采用异步训练来弥补一下,毕竟我换来的是能用 Windows 10 和 WSL2 作为我的主研发环境,不用多系统或者远程Linux系统来回切换了。
原文:https://www.cnblogs.com/BeanHsiang/p/13227523.html