第一种方法:判断每一行的所属范围[0,100][101,200],取出一小部分数据[0,100]排序,放入文件
第二种方法:分成N多个文件,文件内部有序,文件之间归并排序
瓶颈:单机处理文件太大
化整为零,并发执行=>Hadoop
每个服务器都有自己的数据。现在要把相同的数据放在一起,涉及不同服务器之间的数据迁移,成本较高。
数据迁移=>计算向着数据移动 => MR
文件的切割管理规范:自己知道文件块怎么划分的=>HDFS
文件线性分割成块Block,偏移量offset
一个汉字两个字节,这俩字节被分割开了怎么办??????????????????????
分散存储在集群节点中
Block可以设置副本数,副本无序分散在不同节点中
文件元数据MetaData(blockSize offset 副本);文件数据(数据本身)
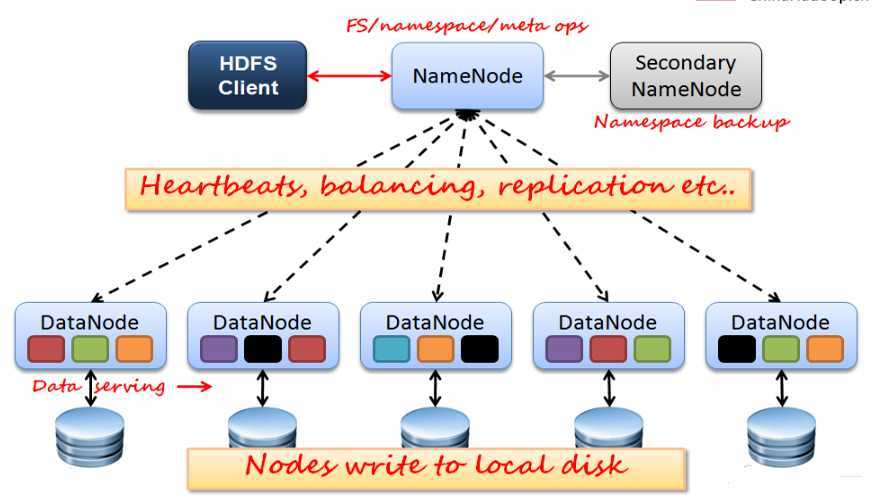
主NameNode节点保存文件元数据:单节点
从DataNode节点保存Block数据:多节点
主从保持心跳
HdfsClient与NameNode和DataNode交互。大数据架构基本都是B/S
DataNode利用服务器本地文件系统存储数据块
基于内存存储:不会和磁盘发生交换
持久化(单向 内存溢写)
服务器重启的时候用持久化数据
block位置信息持久化不存。block所在节点挂了,这时候利用持久化数据就会出问题,所以还是通过心跳机制靠谱
持久化方式一: metadata存储到磁盘文件名为“fsimage”(序列化与反序列化方式)。序列化慢 恢复块
持久化方式二: edits记录对metadata的操作日志…>Redis。 持久化快 恢复慢
原文:https://www.cnblogs.com/Coeus-P/p/13229517.html