说明:本文为论文 《MapReduce: Simplified Data Processing on Large Clusters》 的个人理解,难免有理解不到位之处,欢迎交流与指正 。
论文地址:MapReduce Paper
MapReduce 是 Google 提出的一种用于处理和生成大数据集的 编程模型 ,具象地可以理解成一个 框架 。
该框架含有两个由用户来实现的接口:map 和 reduce ,map 函数接收一个键值对,生成一个中间键值对集合,MapReduce 框架会将所有共用一个键的值组合在一起并传递给 reduce 函数,reduce 函数接收此中间键以及该键的值的集合,将这些值合并在一起,生成一组更小的值的集合 。
该编程模型中,数据形式变换可由以下模式表示:
map: (k1, v1) -> list(k2, v2)
reduce: (k2, list(v2)) -> list(v3)
注:论文中该模式第二行表示为 reduce: (k2, list(v2)) -> list(v2) ,个人认为由于通常情况下 reduce 会对 list<v2> 做一些处理(特殊情况下不做任何处理,即 reduce 为恒等函数),生成一些不同的值,所以用 list<v3> 进行表示可以区分处理前后的差异,更具一般化 。
论文中给出了 MapReduce 的经典使用示例,即 统计文档中每个单词出现次数 ( word count 任务 ),通过此示例可以直观了解到 MapReduce 的使用方法 。
由用户实现的 map 和 reduce 函数的伪代码为:
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w,"1");
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));
通过上述伪代码可以看到:
map 函数,输入一个键值对, key 为文件名,value 为文件内容,它对文件中每一个单词都生成 中间键值对 <w, ‘1‘> ,最后返回的内容为一个键值对的集合,表示为 list(<‘cat‘, ‘1‘>, <‘dog‘, ‘1‘>, ..., <‘cat‘, ‘1‘>, <‘pig‘, ‘1‘>)reduce 函数,输入一个键值对,key 为一个单词 ,value 为该单词对应的计数的列表,即 list(‘1‘, ‘1‘, ‘1‘, ..., ‘1‘) ,列表中 ‘1‘ 的个数即为文档中该单词出现的次数,最后将单词出现的次数返回list(<‘cat‘, ‘1‘>, <‘dog‘, ‘1‘>, ..., <‘cat‘, ‘1‘>, <‘pig‘, ‘1‘>) 转化为 <‘cat‘, list(‘1‘, ‘1‘, ‘1‘, ..., ‘1‘)> 的步骤是由 MapReduce 框架来执行的上述过程可以图示为:
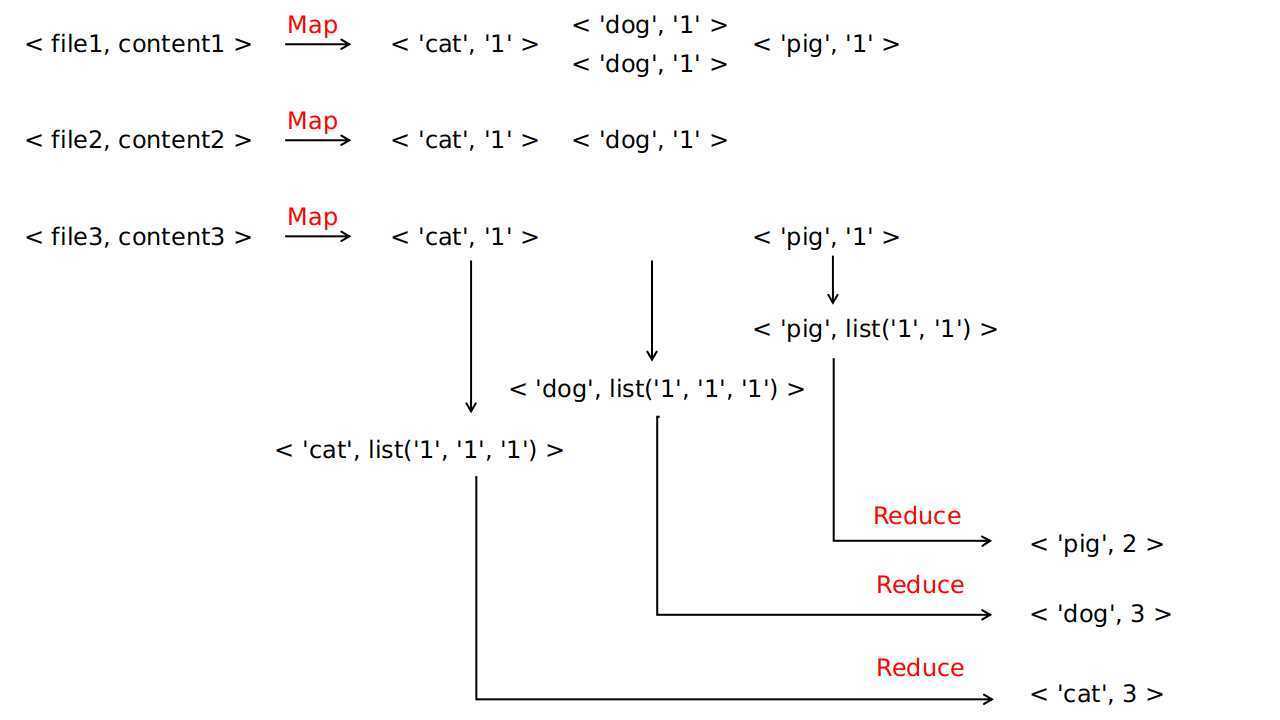
论文附录 A 有由 C++ 实现的针对文档词计数任务的 map 函数、reduce 函数 以及 调用两接口的完整程序代码,在此不做详述 。
MapReduce 模型可以有多种不同的实现方式,论文主要介绍了一种在 Google 内部广泛使用的计算环境下(通过以太网交换机连接,并由商用服务器所组成的大型集群)使用的 MapReduce 实现 。
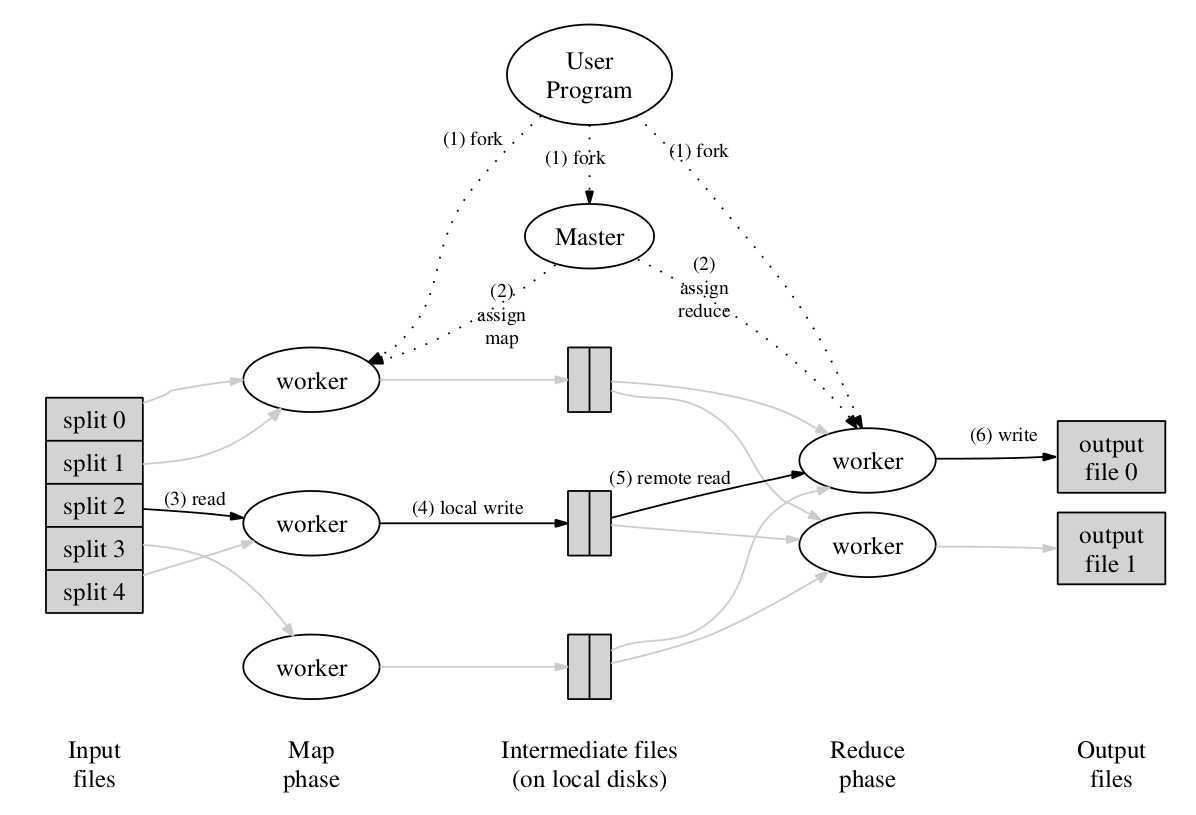
上图为此 MapReduce 框架实现的示意图,下文基于此图对 MapReduce 的执行过程进行描述,描述的序号与图中的序号相对应(这部分内容论文描述比较详细,所以以翻译为主,穿插个人理解以及补充后文中的优化细节):
M 个片段( 每个大小为 16MB~64MB ),存储在 GFS 文件系统 ,接着,它会在集群中启动多个 程序副本 。master ,剩余为 worker ,master 对 worker 进行任务分配,共有 M 个 map 任务以及 R 个 reduce 任务( M 同时为文件片段数 , R 由用户指定),master 会给每个空闲的 worker 分配一个 map 任务或者一个 reduce 任务 。master 会周期性地 ping 每个 worker ,若在一定时间内无法收到某个 worker 的响应,那么 master 将该 worker 标记为 fail :
该 worker 上完成的 map 任务必须重新执行,因为 map 任务数据结果保存在 worker 的本地硬盘中,worker 无法访问了,则输出数据也无法访问;该 worker 上完成的 reduce 任务不需要重新执行,因为输出结果已存储在全局文件系统中 。
目前的实现选择中断 MapReduce 计算,客户端可检查该 master 的状态,并根据需要重新执行 MapReduce 操作 。
此模式是为了 节约网络带宽 。
将输入数据( 由 GFS 系统管理 )存储在集群中服务器的本地硬盘上,GFS 将每个文件分割为大小为 64MB 的 Block ,并且对每个 Block 保存多个副本(通常3个副本,分散在不同机器上)。master 调度 map 任务时会考虑输入数据文件的位置信息,尽量在包含该相关输入数据的拷贝的机器上执行 map 任务 。若任务失败,master 尝试在保存输入数据副本的邻近机器上执行 map 任务,以此来节约网络带宽 。
此模式是为了缓解 straggler (掉队者) 问题 ,即 :一台机器花费了异常多的时间去完成 最后几个 map 或 reduce 任务,导致整个计算时间延长的问题 。可能是由于硬盘问题,可能是 CPU 、内存、硬盘和网络带宽的竞争而导致的 。
解决此问题的方法是:当一个 MapReduce 计算 接近完成 时,master 为正在执行中的任务执行 备用任务 ,当此任务完成时,无论是主任务还是备用任务完成的,都将此任务标记为完成 。这种方法虽然多使用了一些计算资源,但是有效降低了 MapReduce Job 的执行时间 。
某些情况下,每个 map 任务生成的中间 key 会有明显重复,可使用 Combiner 函数 在 map worker 上将数据进行部分合并,再传往 reduce worker 。
Combiner 函数 和 Reduce 函数的实现代码一样,区别在于两个函数输出不同,Combiner 函数的输出被写入中间文件,Reduce 函数的输出被写入最终输出文件 。
这种方法可以提升某些类型的 MapReduce 任务的执行速度( 如 word count 任务)。
对于有服务器故障而可能导致的 reduce 任务可能读到部分写入的中间文件 的问题 。可以使用 临时中间文件 ,即 map 任务将运算结果写入临时中间文件,一旦该文件完全生成完毕,以原子的方式对该文件重命名 。
适合PB级以上海量数据的离线处理
隐藏了并行化、容错、数据分发以及负载均衡等细节
允许没有分布式或并行系统经验的程序员轻松开发分布式任务程序
伸缩性好,使用更多的服务器可以获得更多的吞吐量
集群中所有服务器既执行 GFS ,也执行 MapReduce 的 worker
master 调度时会优先使 map 任务执行在存储有相关输入数据的服务器上
reduce worker 直接通过 RPC 从 map worker 获取中间数据,而不是通过 GFS ,因此中间数据只需要进行一次网络传输
R 远小于中间 key 的数量,因此中间键值对会被划分到一个拥有很多 key 的文件中,传输更大的文件( 相对于一个文件拥有更少的 key )效率更高
《MapReduce: Simplified Data Processing on Large Clusters》论文研读
原文:https://www.cnblogs.com/brianleelxt/p/13231463.html