项目来源厦门大学林子雨老师得Spark学习项目中,里面为部分项目代码和实验截图
读取文件
from pyspark import SparkConf, SparkContext from pyspark.sql import SparkSession from pyspark.ml.feature import StringIndexer, IndexToString from pyspark.ml import Pipeline import os import pandas as pd import matplotlib.pyplot as plt import mpl_toolkits.basemap from pyspark.sql.functions import count, when, split, posexplode conf = SparkConf().setMaster("local").setAppName("preprocessing") sc = SparkContext(conf = conf) sc.setLogLevel(‘WARN‘) # 减少不必要的log输出 spark = SparkSession.builder .config(conf = SparkConf()) .getOrCreate() rawFile = ‘earthquake.csv‘ rawData = spark.read.format(‘csv‘) .options(header=‘true‘, inferschema=‘true‘) .load(rawFile)
数据预处理
# 拆分‘Date‘到‘Month‘,‘ Day‘, ‘Year‘ newData = rawData.withColumn(‘Split Date‘, split(rawData.Date, ‘/‘)) attrs = sc.parallelize([‘Month‘,‘ Day‘, ‘Year‘]).zipWithIndex().collect() for name, index in attrs: newColumn = newData[‘Split Date‘].getItem(index) newData = newData.withColumn(name, newColumn) newData = newData.drop(‘Split Date‘) newData.show(5)
+----------+--------+--------+---------+----------+-----+---------+-----+----+----+ | Date| Time|Latitude|Longitude| Type|Depth|Magnitude|Month| Day|Year| +----------+--------+--------+---------+----------+-----+---------+-----+----+----+ |01/02/1965|13:44:18| 19.246| 145.616|Earthquake|131.6| 6.0| 01| 02|1965| |01/04/1965|11:29:49| 1.863| 127.352|Earthquake| 80.0| 5.8| 01| 04|1965| |01/05/1965|18:05:58| -20.579| -173.972|Earthquake| 20.0| 6.2| 01| 05|1965| |01/08/1965|18:49:43| -59.076| -23.557|Earthquake| 15.0| 5.8| 01| 08|1965| |01/09/1965|13:32:50| 11.938| 126.427|Earthquake| 15.0| 5.8| 01| 09|1965| +----------+--------+--------+---------+----------+-----+---------+-----+---
利用经纬度进行位置可视化(哪里发生了地震)
data = rawData.select(‘Latitude‘, ‘Longitude‘, ‘Magnitude‘).dropna() locationPd = data.toPandas() # 世界地图 basemap = mpl_toolkits.basemap.Basemap() basemap.drawcoastlines() # 数据可视化 plt.scatter(locationPd.Longitude, locationPd.Latitude, color=‘g‘, alpha=0.25, s=locationPd.Magnitude) plt.title(‘Location‘) plt.xlabel(‘Longitude‘) plt.ylabel(‘Latitude‘) plt.show()
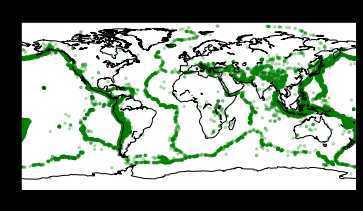
级数与深度的关系
data = rawData.select(‘Depth‘, ‘Magnitude‘).dropna() vsPd = data.toPandas() # 数据可视化 plt.scatter(vsPd.Depth, vsPd.Magnitude, color=‘g‘, alpha=0.1) plt.title(‘Depth vs Magnitude‘) plt.xlabel(‘Depth‘) plt.ylabel(‘Magnitude‘) plt.show()
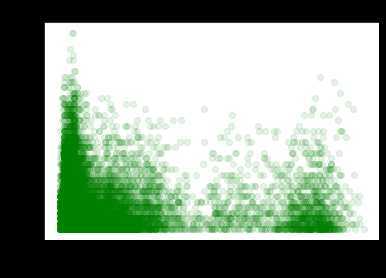
为了节约篇幅,只写了两个实验进来
如何利用pyspark进行数据分析,spark工作流程以及地图可视化
原文:https://www.cnblogs.com/jiaxinHuang/p/13232244.html