最近局方流媒体服务器添加了十几路入向媒体码流,导致应用程序处理阻塞,引起业务异常。
根据之前相关问题的处理经验,认为是码流不规范,导致流媒体软件处理阻塞。但是有其他的双机节点,没有码流处理阻塞问题,并且结合后来的打点分析,也排除是码流的问题。
结合系统监控日志,我们发现问题流媒体软件异常时,系统多个cpu核软中断比较高,导致cpu核ilde基本为0。
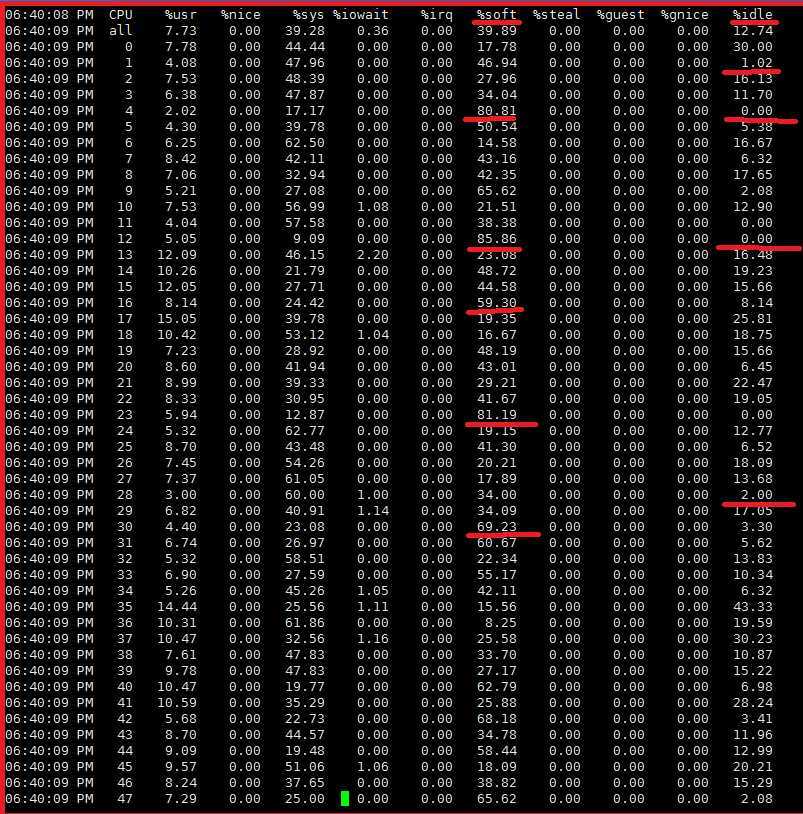
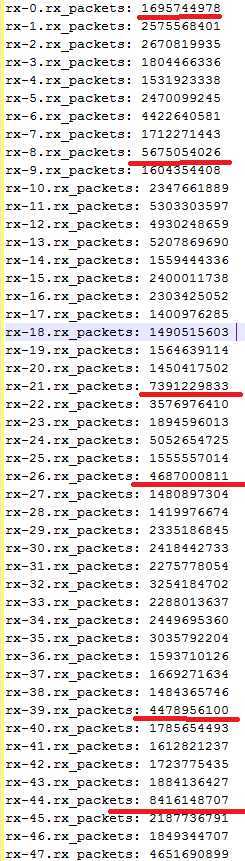
软中断一般和入向报文接收有关,所以开始排查网卡入向报文接收情况。进一步发现,网卡某些收包队列报文数是其他队列报文数的2-3倍。
排查方向聚焦到网卡RSS的hash算法。
我们抓取了线上的组播报文,在实验室做拷机复现,但是始终没有出现软中断冲高的现象。使用专业软件,也没有发现媒体TS码流有任何异常。
后来发现,我们抓取的组播码流,源和目的端口都是一样的,源IP都是同一个编码器的,组播地址不一样。对于这种流量模型,RSS hash的结果,
很有可能集中到某几个入向收包队列。调整了实验室的流量模型,立即就复现了软中断冲高的问题。
问题是RSS hash引起的看来是实锤了,但后来发现自己还是too young, too navie了:)
网口默认的RX flow hash算法是根据源目的IP+端口进行计算的,如下图所示:
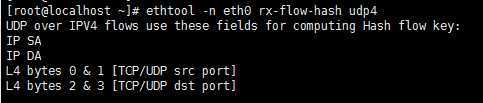
既然流量模型里,源目的端口都是一样的,就先调整udp4 rx-flow-hash为目的IP地址,入向组播流量上来后,仍然是软中断冲高。 这个结果推翻了之前的结论。
由于实验室压的流量比线上实际的要大,软中断冲高不是集中在某几个cpu核,几乎是全部冲高。于是使用perf top查看了一下系统热点:
__udp4_lib_mcast_deliver这个函数调用频繁,而且还有spin lock也是热点函数。
流媒体服务器使用的是3.10.0-327.22.2.el7.x86_64内核版本,比较了3.10.0-693.21.1.el7.x86_64内核版本,__udp4_lib_mcast_deliver函数处理是有些差异。
果断对3.10.0-327.22.2.el7.x86_64内核版本打了补丁,测试结果不要太好:)
1 /** 2 * struct udp_table - UDP table 3 * 4 * @hash: hash table, sockets are hashed on (local port) 5 * @hash2: hash table, sockets are hashed on (local port, local address) 6 * @mask: number of slots in hash tables, minus 1 7 * @log: log2(number of slots in hash table) 8 */ 9 struct udp_table { 10 struct udp_hslot *hash; 11 struct udp_hslot *hash2; //key:基于 本地端口和组播地址的hash表 12 unsigned int mask; 13 unsigned int log; 14 };
1 /* 2 * Multicasts and broadcasts go to each listener. 3 * 4 * Note: called only from the BH handler context. 5 */ 6 static int __udp4_lib_mcast_deliver(struct net *net, struct sk_buff *skb, 7 struct udphdr *uh, 8 __be32 saddr, __be32 daddr, 9 struct udp_table *udptable) 10 { 11 struct sock *sk, *stack[256 / sizeof(struct sock *)]; 12 struct udp_hslot *hslot = udp_hashslot(udptable, net, ntohs(uh->dest)); //使用入向报文的目的端口hash,找到对应的hash slot 13 int dif; 14 unsigned int i, count = 0; 15 16 spin_lock(&hslot->lock); 17 sk = sk_nulls_head(&hslot->head); //获取hash slot中第一个sock 18 dif = skb->dev->ifindex; 19 sk = udp_v4_mcast_next(net, sk, uh->dest, daddr, uh->source, saddr, dif); //查找第一个匹配的sock
20 while (sk) { // 如果找到一个匹配的sock,则放入stack数组中,等待处理数据 21 stack[count++] = sk; 22 sk = udp_v4_mcast_next(net, sk_nulls_next(sk), uh->dest, 23 daddr, uh->source, saddr, dif); //查找链表中下一个匹配的sock,即接收同一个组播组的sock 24 if (unlikely(count == ARRAY_SIZE(stack))) { //如果stack数组已经满了,则要刷新stack 25 if (!sk) //有可能 26 break; 27 flush_stack(stack, count, skb, ~0); //传递数据到sock接收队列 28 count = 0; 29 } 30 } 31 /* 32 * before releasing chain lock, we must take a reference on sockets 33 */ 34 for (i = 0; i < count; i++) 35 sock_hold(stack[i]); 36 37 spin_unlock(&hslot->lock); 38 39 /* 40 * do the slow work with no lock held 41 */ 42 if (count) { 43 flush_stack(stack, count, skb, count - 1); 44 45 for (i = 0; i < count; i++) 46 sock_put(stack[i]); 47 } else { 48 kfree_skb(skb); //如果没有匹配的sock,则释放skb 49 } 50 return 0; 51 }
1 /* 2 * Multicasts and broadcasts go to each listener. 3 * 4 * Note: called only from the BH handler context. 5 */ 6 static int __udp4_lib_mcast_deliver(struct net *net, struct sk_buff *skb, 7 struct udphdr *uh, 8 __be32 saddr, __be32 daddr, 9 struct udp_table *udptable) 10 { 11 struct sock *sk, *stack[256 / sizeof(struct sock *)]; 12 struct hlist_nulls_node *node; 13 unsigned short hnum = ntohs(uh->dest); 14 struct udp_hslot *hslot = udp_hashslot(udptable, net, hnum); //使用入向报文的目的端口hash,找到对应的hash slot 15 int dif = skb->dev->ifindex; 16 unsigned int count = 0, offset = offsetof(typeof(*sk), sk_nulls_node); 17 unsigned int hash2 = 0, hash2_any = 0, use_hash2 = (hslot->count > 10); //如果hash slot中个数大于10,就使用udptable中的hash2,也就是组播报文的目的端口和组播地址 做hash计算 18 19 if (use_hash2) { 20 hash2_any = udp4_portaddr_hash(net, htonl(INADDR_ANY), hnum) & 21 udp_table.mask; 22 hash2 = udp4_portaddr_hash(net, daddr, hnum) & udp_table.mask; 23 start_lookup: 24 hslot = &udp_table.hash2[hash2]; //获取hash2表的 hash slot 25 offset = offsetof(typeof(*sk), __sk_common.skc_portaddr_node); 26 } 27 28 spin_lock(&hslot->lock); 29 sk_nulls_for_each_entry_offset(sk, node, &hslot->head, offset) { //遍历基于(组播端口+组播地址)做hash计算的udp sock hash表 30 if (__udp_is_mcast_sock(net, sk, 31 uh->dest, daddr, 32 uh->source, saddr, 33 dif, hnum)) { //如果是匹配的组播sock,则放入stack数组,等待处理接收的skb数据 34 if (unlikely(count == ARRAY_SIZE(stack))) { 35 flush_stack(stack, count, skb, ~0); //传递skb到sock接收队列 36 count = 0; 37 } 38 stack[count++] = sk; 39 sock_hold(sk); 40 } 41 } 42 43 spin_unlock(&hslot->lock); 44 45 /* Also lookup *:port if we are using hash2 and haven‘t done so yet. */ 46 if (use_hash2 && hash2 != hash2_any) { //可能还有只绑定端口的sock,也可以接收该组播报文 47 hash2 = hash2_any; 48 goto start_lookup; 49 } 50 51 /* 52 * do the slow work with no lock held 53 */ 54 if (count) { 55 flush_stack(stack, count, skb, count - 1); //传递skb到sock接收队列 56 } else { 57 kfree_skb(skb); 58 } 59 return 0; 60 }
从两个内核的__udp4_lib_mcast_deliver函数分析来看, 3.10.0-327.22.2.el7.x86_64内核 只在udptable中基于port的hash表中做遍历。
如果服务器接收的组播报文都具有相同的端口,那么服务器加入的组播组越多,遍历基于port的hash表消耗的时间就越多,占用软中断就越高。
而3.10.0-693.21.1.el7.x86_64内核版本,在基于port的hash表超过10个(也就是相同端口的sock超过10个)sock,就使用基于端口和本地
地址的hash2表做遍历。这样减少了相同端口sock遍历的耗时,提高了向socket层传递入向组播报文的效率;因为__udp4_lib_mcast_deliver函数
是在软中断下半部调用的,所以也就减少了软中断的占用。
您的支持是对博主最大的鼓励??,感谢您的认真阅读。
本博客持续更新,欢迎您关注和交流!
本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
原文:https://www.cnblogs.com/smith9527/p/13207424.html