这一章节主要讲了spark如何工作
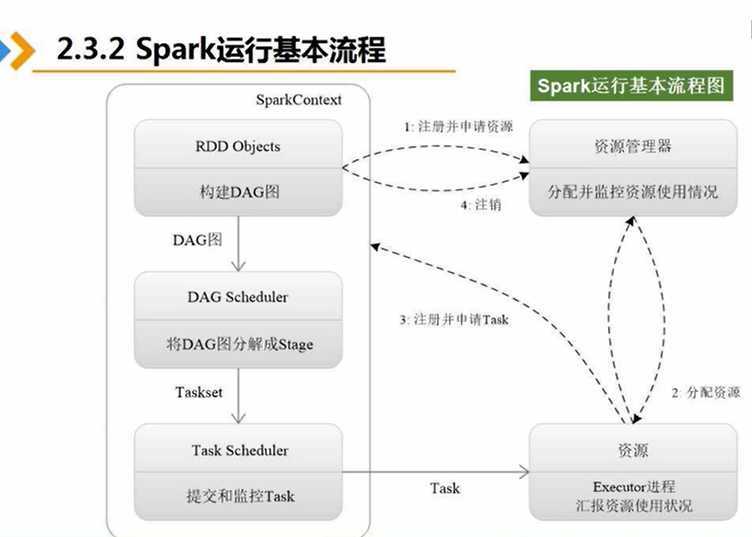
spark的架构属于主从架构,主节点复制任务的一系列操作以及资源申请,在spark主节点叫做DRIVER节点
driver节点的作用:
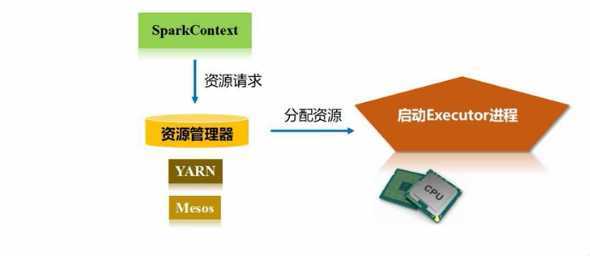
1:根据用户编写的代码会创建一个SparkContext指挥官,然后向资源管理器申请(内存和cpu等资源)进行任务的分配和监控,资源管理器接到资源申请的请求后,资源管理器会为excutor分配内存资源,这时Worker Node里面的Excutor进程就会启动,从而执行任务。(但是任务从何而来?)
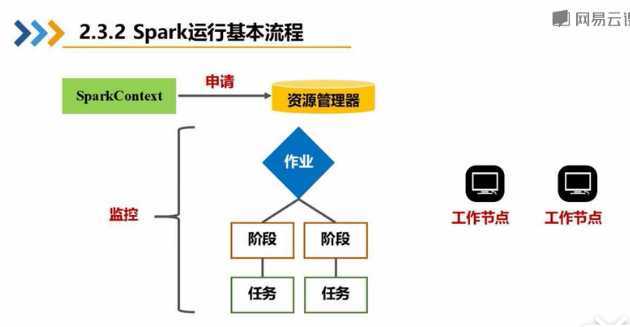
2:首先SparkconText会根据用户编写代码将需要操作的据数据集RDD对象构建DAG有向图,然后将DAG有向图交给组件DAG Scheduler,利用DAG Scheduler将有向图解析成很多阶段,每个阶段包括很多任务。最后由Task Scheuler组件将任务分发到worker Node中的线程执行。
(
为什么是操作RDD数据集,RDD数据集的优势是什么?
答:
1:大数据的计算过程中需要进行多次的迭代计算,这样就会造成中间结果的数据读写操作,导致频繁的序列化和反序列化的系统开销,因此需要利用RDD数据抽象,减少磁盘的IO开销和反复读写次数。RDD出现就是为了避免这些,用逻辑转换为一系列的转换操作。得到最终的结果。

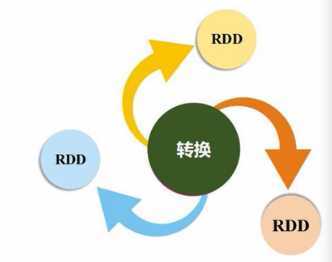
2:Rdd是一个分布式对象集合,其本质上是一个只读的分区记录集合,这样就能就行分布式计算。
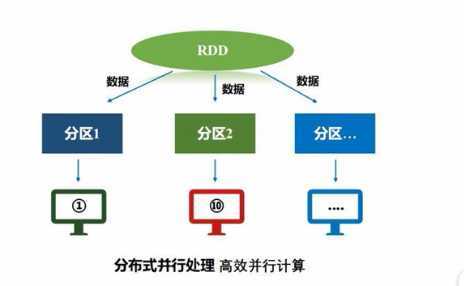
为何使用DAG有向图,DAG有向图的优势是什么?
答:不同的RDD一系列的转换操作会形成依赖关系,最终生成DAG图,可以利用优化原理实现数据的管道化处理,无需数据落地(数据不需要存储在磁盘或其他的存储器中)直接将数据扔到下一个操作中执行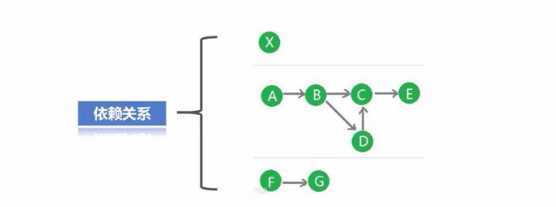
task scheuler是如何将任务进行分配?
答:在Spark中,Exceutor进程在获取资源后会创建很多的线程,线程会自己主动向task Scheduler申请任务,而task scheulder 会根据数据在哪里就会执行该任务,这样就减少额外的数据传输开销,实现了数据的本地化操作,从而达到了计算向数据靠拢。
)。
3:最后将Excutor执行的最终结果反馈到用户中
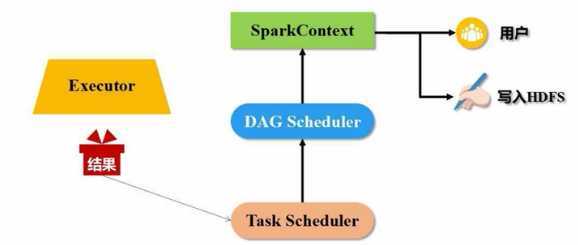
总结:Spark的运行原理中的各个组件以及RDD的出现、DAG都是SPARK能快速处理大量数据的依据和保证
原文:https://www.cnblogs.com/jiaxinHuang/p/13234679.html