用php正则表达式截取字符串,但是却变成了乱码。
文件编码都是utf8的,代码如下:
1 <?php 2 header("Content-type:text/html;charset=UTF-8"); 3 4 $pattern_1 = ‘/\s+?(\S+)?$/‘; 5 $pattern_2 = ‘/[ \f\n\r\t\v]+?(\S+)?$/‘; 6 7 $str_1 = ‘加强和改进党的作风‘; 8 $str_2 = ‘加强和改进你的作风‘; 9 10 echo "1:"; 11 echo preg_replace($pattern_1, ‘‘, $str_1); 12 13 echo "<br>2:"; 14 echo preg_replace($pattern_1, ‘‘, $str_2); 15 16 echo "<br>3:"; 17 echo preg_replace($pattern_2, ‘‘, $str_1); 18 19 echo "<br>4:"; 20 echo preg_replace($pattern_2, ‘‘, $str_2); 21 ?>
根据菜鸟教程,正则表达式中\s和[ \f\n\r\t\v]应该是等效的,但是结果却不一样。如下图
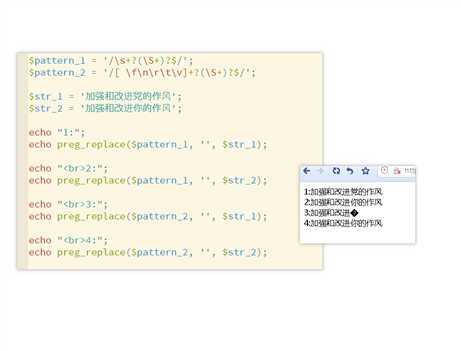
第三句出现了乱码,而字符串换了一个字又不乱码了。很是奇怪,在【博问】中提问,有大佬给予了解释,转过来如下:
由于你正则没有加u,所以匹配的时候不会把utf8字符看成一个字符,而是三个字符
党这个字,utf8编码是e5859a,中间的85,在unicode编码里面是NEL字符,就是unicode的换行符,如下图

PHP用的正则解析器是PCRE,PCRE中\v代表垂直空白符,所以NEL字符也被包括在内
如果你要解决这个问题,就在正则后面加u,比如/[ \f\n\r\t\v]+?(\S+)?$/u
以下文字来自官方文档,由于中文翻译有点误导,所以最好直接看英文,Perl 5 no longer includes vertical tab in its set of whitespace characters. The \v escape that was in the Perl documentation for a long time was never in fact recognized. However, the character itself was treated as whitespace at least up to 5.002. In 5.004 and 5.005 it does not match \s.
原文:https://www.cnblogs.com/html55/p/13257278.html