摘自:我是康小小
当我们去商店购物时,我们通常有一个标准的购物清单,每个购物的人都有一个独特的清单,取决于他们的需求和喜好,家庭主妇可能会为家庭晚餐购买健康的食材,而单身汉可能会购买啤酒和薯条。了解这些购物模式有助于通过多种方式提高销售额,如果有一对物品,X和Y经常被购买:

虽然我们可能知道某些物品经常会一起购买,但问题是,我们如何去发现这些关联关系?(很典型的就是啤酒和尿布的问题)除了增加销售利润外,关联规则还可以用于其他领域。例如,在医学诊断中,了解哪些症状容易并存,有助于提高患者的护理水平和药物处方。
关联规则分析是一种揭示项商品之间如何相互关联的技术,有三个常用的指数来衡量关联关系。
指数一:支持度(Support)
支持度表示一个项集的流行程度,用一个项集出现的事务的比例来衡量。在下面的表1中,apple的支持率是8个中的4个,即50%。项集还可以包含多个项,例如,苹果、啤酒、大米的支持率是8个中的2个,即25%。

如果你发现超过一定比例的商品销售往往会对您的利润产生重大影响,你可以考虑将该比例作为支持度阈值,然后,可以将支持度的值高于此阈值的项集标识为重要项集。
指数二:置信度(Confidence)
置信度表示在X被购买的前提下,Y被购买的概率,表示为{X -> Y},这是通过X交易的比例来衡量的,其中项目Y也出现在交易中。在表1中,{苹果->啤酒} 的置信度为3/4,即75%。
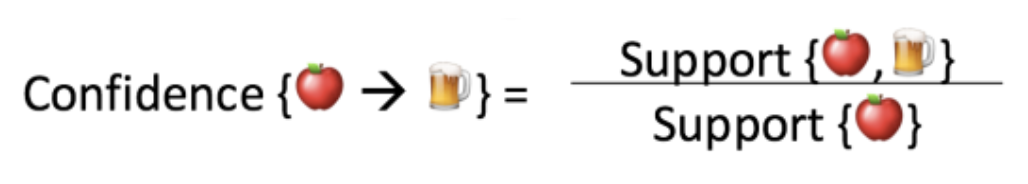
但是置信度指数的一个缺点是它可能会误导关联的重要性,因为它只说明了苹果有多受欢迎,而不是啤酒。如果啤酒在一般情况下也很受欢迎,那么包含了苹果的订单中同时包含啤酒的可能性将更高,从而提高了置信度指数。为了说明这两个组成项目的基础普及率,我们使用了第三个措施,称为提升度(Lift)。
指数三:提升度(Lift)
提升度表示在购买X时购买Y的可能性,同时控制Y项的流行程度。在表1中,{苹果->啤酒} 的提升度为1,表明了苹果和啤酒之间没有关联。提升度的值大于1意味着,购买X的情况下很有可能购买Y,反之,提升度的值小于1,表示用户购买X的时候不大可能购买Y。

我们使用来自Arules R库的杂货交易数据集,包含了30天内杂货店的实际交易,下面的网络图显示所选商品之间的关联。大的圆圈表示较高的支持度,而红色圆圈表示较高的提升度
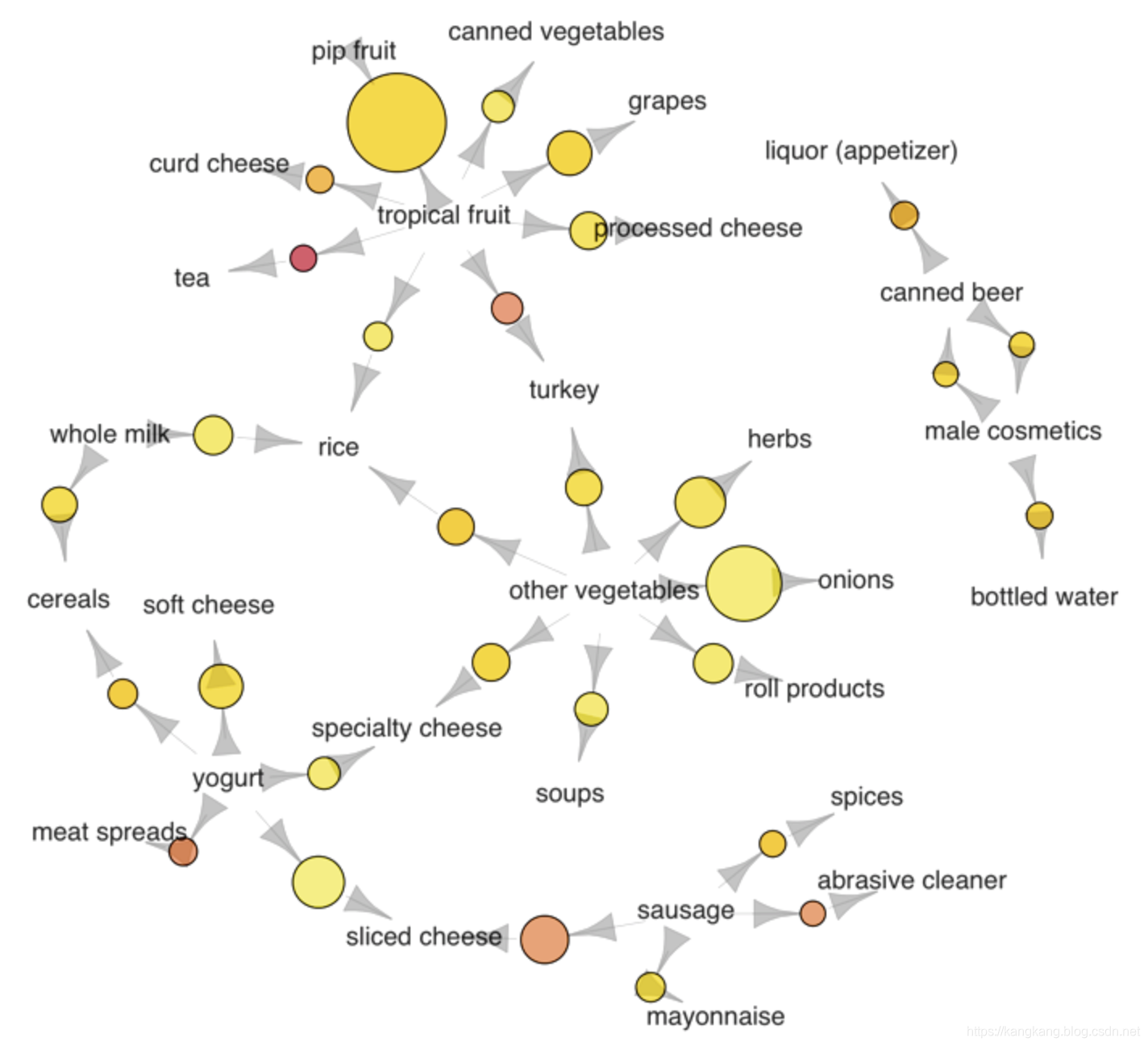
所选项目之间的关联,使用ArulesViz R库可视化后,可以观察到几种购买模式。例如:
回想一下,置信度指数的一个缺点是它倾向于歪曲关联的重要性。为了证明这一点,我们返回主数据集,选择3个包含啤酒的关联规则:

表2. 啤酒相关的关联规则
{啤酒->苏打水} 规则的置信度最高,为20%。然而,啤酒和苏打水经常出现在所有交易中(见表3),因此它们的关联可能只是侥幸而已。这是由{啤酒->苏打水}的提升值确定的,即1,表示啤酒和苏打水之间没有关联。
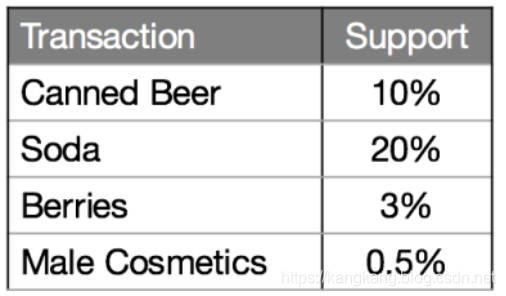
表3.商品单独的支持度
另一方面,由于一般男性化妆品的购买量很少,{啤酒->男性化妆品} 规则的置信度很低,但是,从比较高的提升度指数2.6推断,当有人购买男性化妆品时,他很可能也会购买啤酒,反过来说,{啤酒->浆果} 也是正确的,当提升值低于1时,我们可以得出结论,如果有人购买浆果,他可能会厌恶啤酒。
很容易计算出单个项目集的流行度,比如{啤酒->苏打水}。但是,营业者通常不会询问单个项集。相反,所有者更希望拥有一个流行项目集的完整列表。要获得这个列表,需要计算每个可能的项目配置的支持值,然后短列满足最小支持阈值的项目集。
在一个只有10个商品的商店中,要检查的可能搭配总数将达到1023个,这个数字在一个有数百个商品的商店中呈指数增长。
那么有没有办法减少需要考虑的商品配置数量?
先验(Apriori)原理可以减少我们要检验的项集的数量,简单的描述先验原则就是:
如果一个项集不经常出现,那么它的所有超集也必须不经常出现。这意味着,如果发现{啤酒}不常见,我们可以期望{啤酒->披萨)也同样或更不常见。所以,在合并流行项集列表时,我们不需要考虑{啤酒->比萨},也不需要考虑包含啤酒的任何其他项集配置。
查找高支持度的项集
使用先验原理,使用先验原理,可以缩减需要检查的项集的数量,并且可以通过以下步骤获得常用项集的列表:
这个迭代过程在下面的动画GIF中进行了说明:

使用先验算法减少候选项集
可以从动画中看到,apple的支持度较低,因此它被删除了,不需要考虑包含apple的所有其他项集配置,这个操作可以减少一半以上的项集数量。
这里需要注意,您在步骤1中选择的支持度阈值可以基于正式分析的经验或者是过去历史的经验,如果你发现超过一定比例的商品销售往往会对您的利润产生重大影响,可以考虑将该比例作为支持度阈值(称为最小支持度)。
查找高置信度和支持度的项集
我们在前面已经看到了如何使用Apriori算法来识别高支持的项集,同理也可用于识别高置信度或提升的项目关联,一旦确定了高支持度项集,找到具有高置信度或提升度的规则就不需要进行计算,因为置信度和提升度的值是使用支持值计算的。
以寻找高置信度规则为例,如果规则 {啤酒, 薯条->苹果} 置信度比较低,所有其他同样的组成项并且苹果在右边的规则,也会有低的置信度。特别是,
{啤酒->苹果,薯条}
{薯条->苹果,啤酒}
也会有一个比较低的置信度,和之前一样,可以使用Apriori算法修剪较低级别的候选项规则,从而减少需要检查的候选规则。
局限性
计算代价很高。尽管Apriori算法减少了要考虑的候选项集的数量,但是当存储库存较大或支持阈值较低时,这个数量仍然可能很大。但是,另一种解决方案是可以通过使用高级数据结构(如哈希表)来减少比较的数量,以便更有效地对候选项集进行排序。
虚假的联想。对大量库存的分析将涉及更多的项集配置,并且可能需要降低支持阈值来检测某些关联。然而,降低支持度阈值也可能增加检测到的虚假关联的数量。为了确保已识别的关联是可归纳的,可以首先从培训数据集中提取关联,然后在单独的测试数据集中评估它们的支持度和置信度。
原文:https://www.cnblogs.com/liyuewdsgame/p/13264724.html