线程池可以看做是线程的集合。在没有任务时线程处于空闲状态,当请求到来:线程池给这个请求分配一个空闲的线程,任务完成后回到线程池中等待下次任务(而不是销毁)。这样就实现了线程的重用。
我们来看看如果没有使用线程池的情况是这样的:
public class ThreadPerTaskWebServer {
public static void main(String[] args) throws IOException {
ServerSocket socket = new ServerSocket(80);
while (true) {
// 为每个请求都创建一个新的线程
final Socket connection = socket.accept();
Runnable task = () -> handleRequest(connection);
new Thread(task).start();
}
}
private static void handleRequest(Socket connection) {
// request-handling logic here
}
}
为每个请求都开一个新的线程虽然理论上是可以的,但是会有缺点:
所以说:我们的线程最好是交由线程池来管理,这样可以减少对线程生命周期的管理,一定程度上提高性能。
JDK给我们提供了Excutor框架来使用线程池,它是线程池的基础。
下面我们来看看JDK线程池的总体api架构:
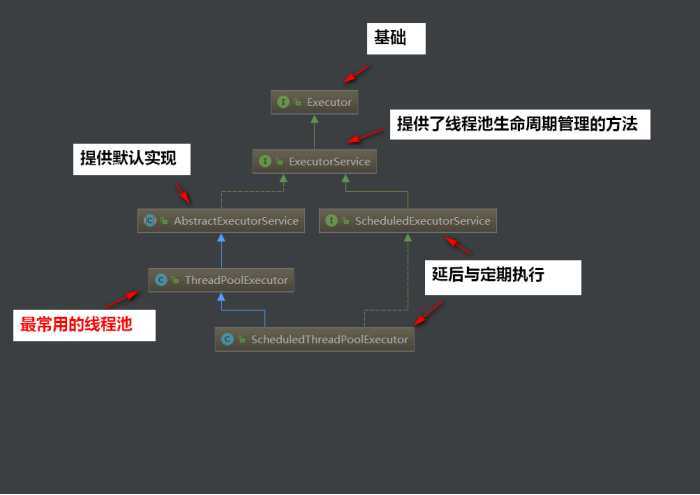
除了ScheduledThreadPoolExecutor和ThreadPoolExecutor类线程池以外,还有一个是JDK1.7新增的线程池:ForkJoinPool线程池
于是我们的类图就可以变得完整一些:
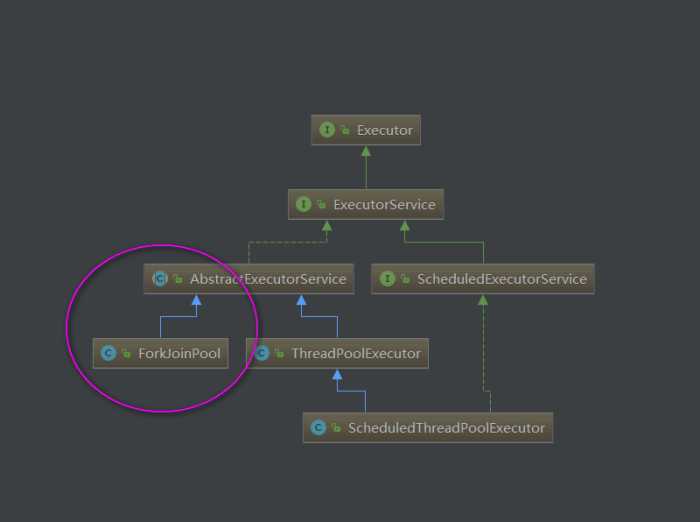
JDK1.7中新增的一个线程池,与ThreadPoolExecutor一样,同样继承了AbstractExecutorService。ForkJoinPool是Fork/Join框架的两大核心类之一。与其它类型的ExecutorService相比,其主要的不同在于采用了工作窃取算法(work-stealing):所有池中线程会尝试找到并执行已被提交到池中的或由其他线程创建的任务。这样很少有线程会处于空闲状态,非常高效。这使得能够有效地处理以下情景:大多数由任务产生大量子任务的情况;从外部客户端大量提交小任务到池中的情况。
学到了线程池,我们可以很容易地发现:很多的API都有Callable和Future这么两个东西。
Future<?> submit(Runnable task)
<T> Future<T> submit(Callable<T> task)
其实它们也不是什么高深的东西
我们可以简单认为:Callable就是Runnable的扩展。
也就是说:当我们的任务需要返回值的时,我们就可以使用Callable!
Future一般我们认为是Callable的返回值,但他其实代表的是任务的生命周期(当然了,它是能获取得到Callable的返回值的)
简单来看一下他们的用法:
public class CallableDemo {
public static void main(String[] args) throws InterruptedException, ExecutionException {
// 创建线程池对象
ExecutorService pool = Executors.newFixedThreadPool(2);
// 可以执行Runnable对象或者Callable对象代表的线程
Future<Integer> f1 = pool.submit(new MyCallable(100));
Future<Integer> f2 = pool.submit(new MyCallable(200));
// V get()
Integer i1 = f1.get();
Integer i2 = f2.get();
System.out.println(i1);
System.out.println(i2);
// 结束
pool.shutdown();
}
}
Callable任务:
public class MyCallable implements Callable<Integer> {
private int number;
public MyCallable(int number) {
this.number = number;
}
@Override
public Integer call() throws Exception {
int sum = 0;
for (int x = 1; x <= number; x++) {
sum += x;
}
return sum;
}
}
这是用得最多的线程池,所以本文会重点讲解它。
线程的状态:
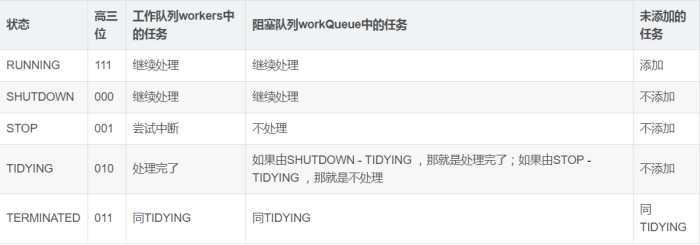
各个状态之间转换:
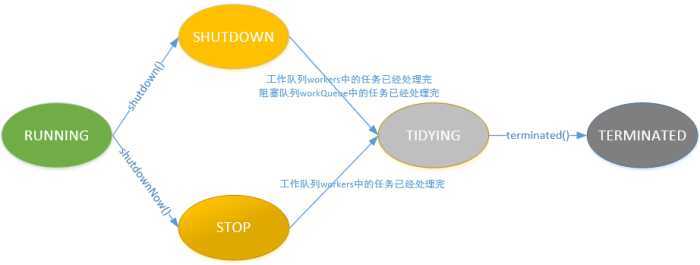
下面我就列举三个比较常见的实现池:
如果读懂了上面对应的策略呀,线程数量这些,应该就不会太难看懂了。
一个固定线程数的线程池,它将返回一个corePoolSize和maximumPoolSize相等的线程池。
非常有弹性的线程池,对于新的任务,如果此时线程池里没有空闲线程,线程池会毫不犹豫的创建一条新的线程去处理这个任务。
使用单个worker线程的Executor
我们读完上面的默认实现池还有对应的属性,再回到构造方法看看
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
1.指定核心线程数量
2.指定最大线程数量
3.允许线程空闲时间
4.时间对象
5.阻塞队列
6.线程工厂
7.任务拒绝策略
再总结一遍这些参数的要点:
线程数量要点:
线程空闲时间要点:
排队策略要点:
当线程关闭或者线程数量满了和队列饱和了,就有拒绝任务的情况了:
拒绝任务策略:
execute执行方法分了三步,以注释的方式写在代码上了
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
//如果线程池中运行的线程数量<corePoolSize,则创建新线程来处理请求,即使其他辅助线程是空闲的。
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
//如果线程池中运行的线程数量>=corePoolSize,且线程池处于RUNNING状态,且把提交的任务成功放入阻塞队列中,就再次检查线程池的状态,
// 1.如果线程池不是RUNNING状态,且成功从阻塞队列中删除任务,则该任务由当前 RejectedExecutionHandler 处理。
// 2.否则如果线程池中运行的线程数量为0,则通过addWorker(null, false)尝试新建一个线程,新建线程对应的任务为null。
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
// 如果以上两种case不成立,即没能将任务成功放入阻塞队列中,且addWoker新建线程失败,则该任务由当前 RejectedExecutionHandler 处理。
else if (!addWorker(command, false))
reject(command);
}
ThreadPoolExecutor提供了shutdown()和shutdownNow()两个方法来关闭线程池
区别:
原文:https://www.cnblogs.com/harpoonJava/p/13266496.html