图像分类、目标检测、分割是计算机视觉领域的三大任务。
目标检测的基本思路:同时解决定位(localization) + 识别(Recognition)。 多任务学习,带有两个输出分支。一个分支用于做图像分类,即全连接+softmax判断目标类别,和单纯图像分类区别在于这里还另外需要一个“背景”类。另一个分支用于判断目标位置,即完成回归任务输出四个数字标记包围盒位置(例如中心点横纵坐标和包围盒长宽),该分支输出结果只有在分类分支判断不为“背景”时才使用。
常见经典的基于深度学习的目标检测算法如图所示:
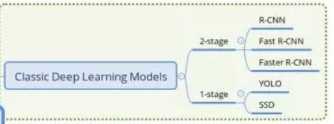
目前目标检测领域的深度学习方法主要分为两类:两阶段(Two Stages)的目标检测算法、一阶段(One Stage)目标检测算法。两阶段(Two Stages):首先由算法(algorithm)生成一系列作为样本的候选框,再通过卷积神经网络进行样本(Sample)分类。常见的算法有R-CNN、Fast R-CNN、Faster R-CNN等等。一阶段(One Stage ):不需要产生候选框,直接将目标框定位的问题转化为回归(Regression)问题处理(Process)。常见的算法有YOLO、SSD等等。
事实证明,Fast R-CNN算法的其中一个问题是得到候选区域的聚类步骤仍然非常缓慢,所以另一个研究组,任少卿(Shaoqing Ren)、何凯明(Kaiming He)、Ross Girshick和孙剑Jiangxi Sun)提出了更快的R-CNN算法(Faster R-CNN),使用的是卷积神经网络,而不是更传统的分割算法来获得候选区域色块,结果比Fast R-CNN算法快得多。
原文:https://www.cnblogs.com/zhuwenjuan-blogs/p/13268146.html