基于上一次运行成功查看输出文件没有结果的经历,这一次仔细理解了pso的MapReduce代码,发现自己之前的输入数据并不符合代码要求的格式,于是加以修改了。
根据此代码,输入数据应该是如下字段:
粒子编号、位置向量1、粒子速度1、个人最优位置1、全局最优位置1、位置向量2、粒子速度2、个人最优位置2、全局最优位置2、个人最优值、全局最优值
注意:这里由于代码中维度设为2,,所以位置向量、粒子速度、个人最优位置、全局最优位置都不是单纯的标量,而是要用二维形式表示,如位置向量position要用(x1,x2)来表示。
因此,上面的如“位置向量1”后面的1仅仅代表位置向量的第1维度值而已。
不难理解,若种群所处空间维度为n,位置向量position就得用(x1,x2,...,xn)来表示,其他三者也是一样的。
个人最优值和全局最优值是根据适应度函数计算得出,设为标量。
另外,我了解到,种群维度的选择其实是与目标适应度函数的维度相关联的。代码中用到的是Ackley 函数,有关介绍可参考这里https://wenku.baidu.com/view/9e0e6838650e52ea55189870.html
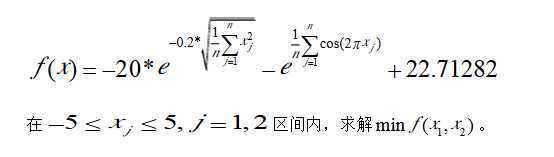
这个函数的维度就是二维,因而代码中种群所处空间维度设为2。
psodata.txt(自己编造的数据)
1 11 3 4 5 4 3 2 7 3 1 2 2 3 4 8 5 3 1 1 8 1 3 22 17 8 1 13 6 26 2 9 1 4 6 7 24 2 5 22 2 5 11 1 5 2 33 3 9 4 6 7 12 17 1 6 33 3 2 12 15 3 9 11 10 1 7 19 4 23 45 9 9 12 2 8 1 8 15 13 4 25 4 3 12 7 6 1 9 2 9 14 8 15 3 11 10 8 1 10 2 7 8 11 13 9 6 26 4 1 11 16 3 4 42 15 22 32 15 19 1 12 23 3 1 19 4 26 7 17 11 1 13 3 23 22 2 5 3 9 21 13 1 14 9 7 3 25 19 16 12 6 19 1 15 7 6 12 22 15 17 10 8 7 1 16 32 33 13 9 14 16 3 12 14 1 17 33 3 2 12 15 3 9 11 10 1 18 19 4 23 45 9 9 41 2 8 1 19 15 13 3 25 4 3 21 7 6 1 20 12 9 4 15 8 13 11 13 18 1
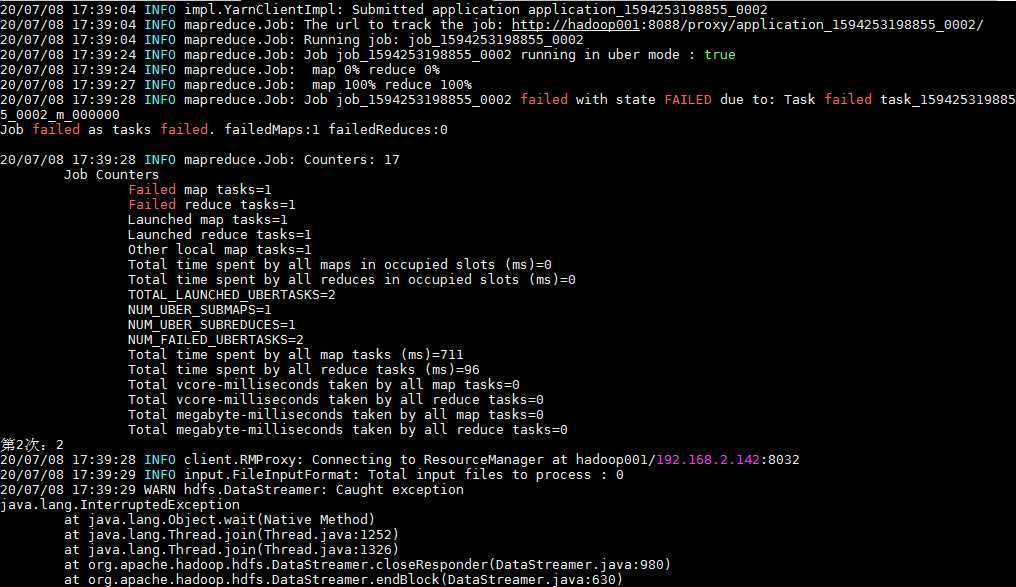
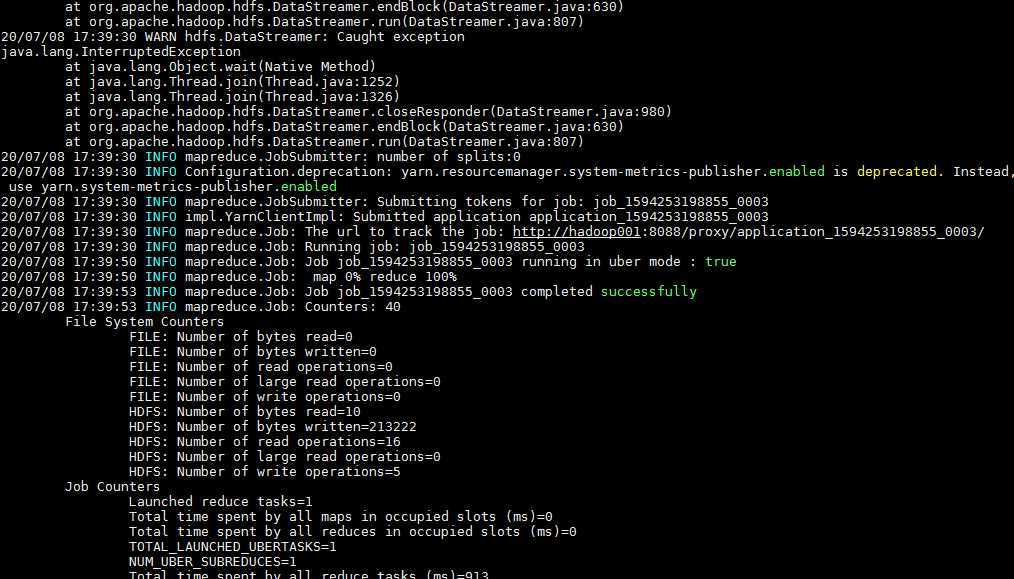
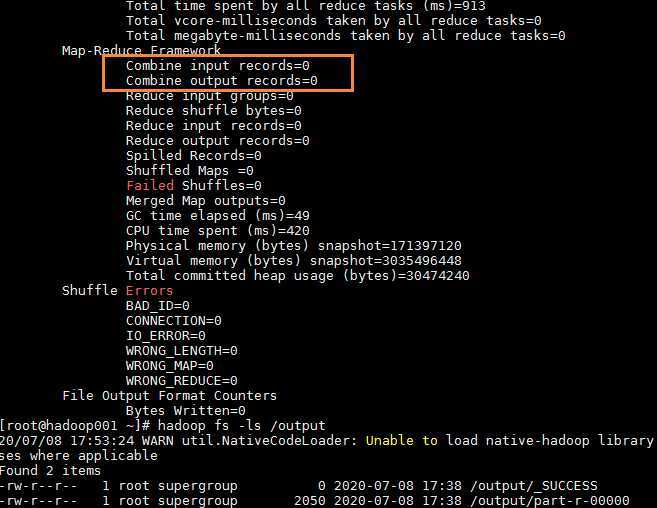
为了简练,下面是只将迭代次数设为3的jar包运行过程,发现最后得到的输出文件只有一个part-r-00000(观察得知,是第0次运行成功得到的结果,第1次运行失败了,第三次虽然也运行成功了,但是map输入记录却是0)。
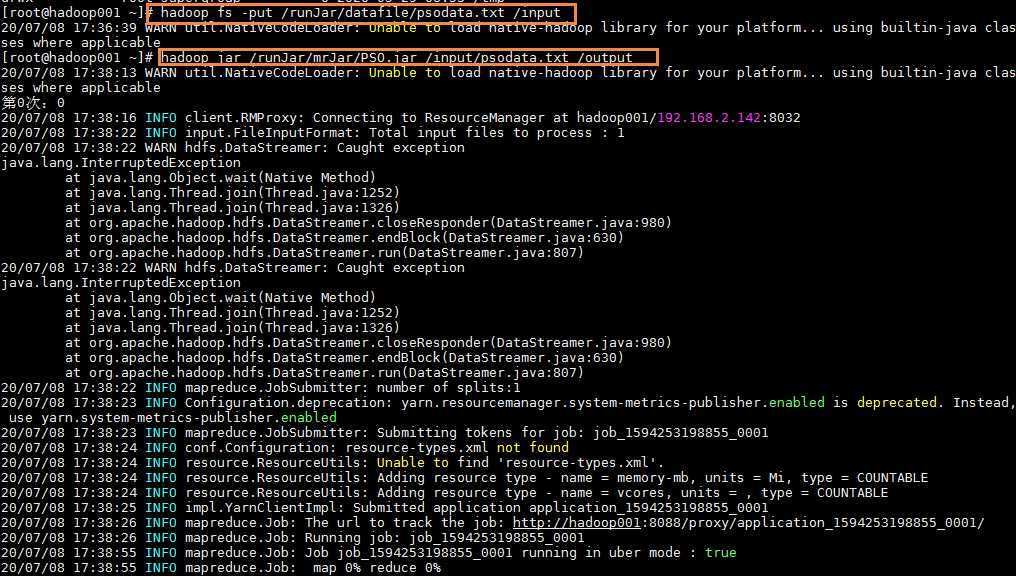
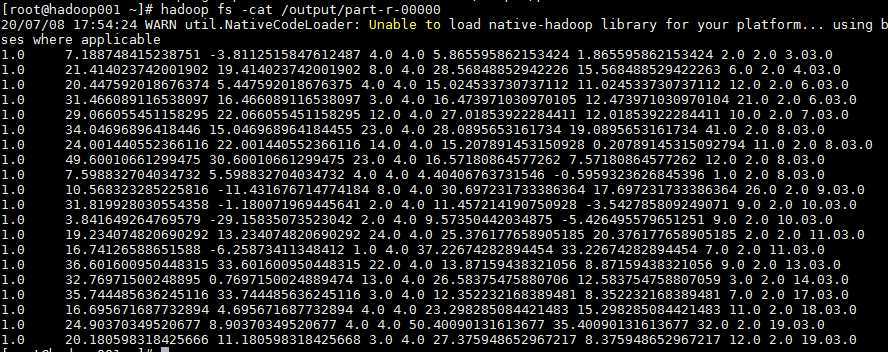
观察上面唯一一次成功得到的数据,还是满足预期的。字段含义分别是:
1(单纯设为的1)、位置向量1、粒子速度1、个人最优位置1、全局最优位置1、位置向量2、粒子速度2、个人最优位置2、全局最优位置2、个人最优值、全局最优值
种群中各个粒子状态栏中记录的全局最优位置和全局最优值是一致的,只是个人最优值有所差异,可大致判断代码执行的逻辑基本正确。
至于为什么只得到一个输出文件,接下来打算仔细分析一下。
先从作业日志着手好了
原文:https://www.cnblogs.com/y-c-m520/p/13268618.html