MySQL中的索引:
基本法则:索引应该构建在被用作查询条件的字段上
索引类型:
B+ Tree索引:使用B+树的数据结构来存储数据的;顺序存储;每一个叶子节点到根结点的距离是相同的
左前缀类型 适合范围查找 可以使用B-Tree索引的查找类型:全键值、键值范围或键前缀查找 ; 全值匹配:和索引中的所有列匹配(精确查找某个值) 比如:‘yanguo‘
匹配最左前缀:只精确匹配起头部分 比如:‘yang%‘
匹配范围值:
精确匹配某一列并范围匹配另一列
不适合适合B-Tree索引的场景:
如果不从最左列开始,索引无效:(Age,Name)
不能跳过索引中的列:(StuID,Name,Age) 不能跳过索引条件,全满足才能匹配到数据
如果查询中某个列是为范围查询,那么其右侧的列都无法再使用索引优化查询(StuID,Name)
Hash索引:基于哈希表(把每一个键提取出来做哈希运算,运算出的结果放置在哈希表中,并分段)
特别适用于精确匹配索引中的所有列(键值对)
注意:只有Memory存储引擎支持显示hash索引
适用场景:
只支持等值比较查询:包括=,IN(),<=>;
不适合使用hash索引的场景:
存储的非为值的顺序,因此,不适用于顺序查询
不支持模糊匹配
空间索引(R-Tree): MyISAM支持空间索引 (了解即可)
全文索引(FULLTEXT):在文本中查找关键词 (了解即可)
索引优点:
高性能索引策略:
在索引中一定不一要进行算数运算(即独立使用列:尽量避免其参与运算) SELECT * FROM students WHERE Age+20>50; #一旦对于列做了算数运算,则这个列将无法用成索引 左前缀索引:索引构建于字段的左侧的多少字符,要通过索引选择性来评估 索引选择性:不重复的索引值和数据表的记录总数的比值 多列索引:ADN操作时更适合使用多列索引 选择合适的索引列次序:将选择性最高放左侧
通过EXPLAIN来分析索引的有效性:
EXPLAIN SELECT clause :获取查询执行计划信息,用来查看查询优化器如何执行查询
输出字段含义:
id:当前查询语句中,每个select语句的编号
注:UNION查询的分析结果会出现----额外匿名临时表
select_type:
简单查询为SIMPLE
复杂查询:
E.G mysql> EXPLAIN select name,Age FROM students WHERE Age>(SELECT avg(Age) FROM students);
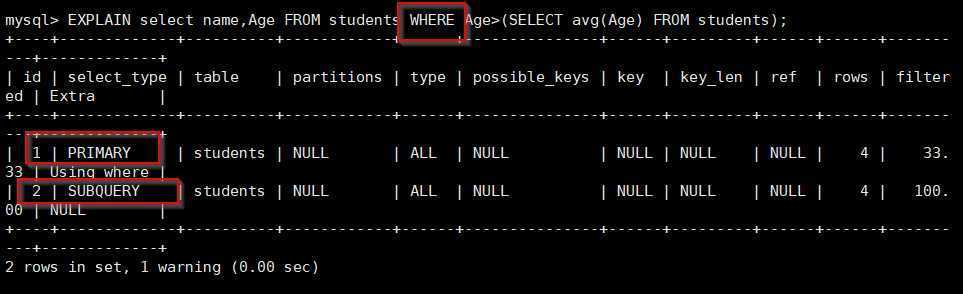
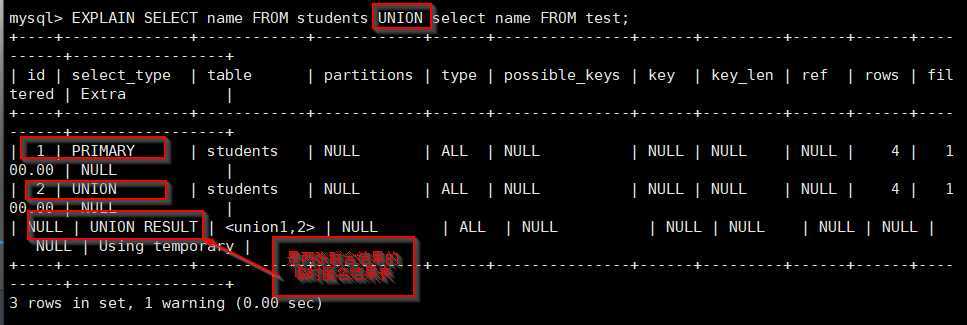
table:SELECT语句关联到的表
type :关联类型或访问类型 即MySQL决定的如何去查询表中的行的方式 (记住)
possible_keys :查询可能会用到的索引
key :查询中使用了的索引
key_len : 在索引使用的字节数
ref:在利用key字段所表示的索引完成查询时所有的列或某常量值
rows:MySQL估计为找所有的目标行而需要读取的行数
Extra:额外信息
原文:https://www.cnblogs.com/liuzhiyun/p/13196733.html