使用Spring Cloud 中的 Ribbon 和 Feign 实现负载均衡机制。但是有个问题需要注意下:
多个微服务之间调用的时候,假设微服务A调用微服务B和微服务C,微服务B和微服务C又在调用其他的微服务,这就是所谓的“扇出”。
如果扇出的链路上某个微服务的调用响应时间过长或者不可用,那么对微服务A的调用就会占用越来越多的系统资源,进而引起系统崩溃,这就是所谓的“雪崩效应”。
为了应对服务雪崩,一种常见的做法是手动服务降级。而 Hystrix 的出现,给我们提供了另一种选择。
Hystrix,英文意思是豪猪,全身是刺,刺是一种保护机制。Hystrix也是Netflix公司的一款组件。
Hystrix的作用是什么?:实现服务熔断降级处理,保护微服务,防止雪崩效应发生。
Hystrix是Netflix开源的一个延迟和容错库,用于隔离访问远程服务、第三方库、防止出现级联失败也就是雪崩效应。
服务雪崩效应是一种因服务提供者的不可用导致服务调用者的不可用,并将不可用逐渐放大的过程
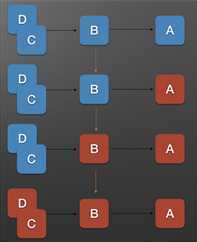
上图中,A 为服务提供者,B 为 A 的服务调用者,C 和 D 是 B 的服务调用者。
当 A 的不可用,引起 B 的不可用,并将不可用逐渐放大 C 和 D 时,服务雪崩就形成了。
我把服务雪崩的参与者简化为 服务提供者 和 服务调用者,
并将服务雪崩产生的过程分为以下三个阶段来分析形成的原因:
1、服务雪崩的每个阶段都可能由不同的原因造成:比如
2、形成重试加大流量的原因有
3、服务调用不可用产生的主要原因是:
针对造成服务雪崩的不同原因,可以使用不同的应对策略:
1、流量控制
2、 改进缓存模式
3、服务自动扩容
4、服务调用者降级服务
出现这种“雪崩效应”肯定是可怕的,在分布式系统中,我们无法保证某个服务一定不出问题,
Hystrix 可以解决。Hystrix 是一个用于处理分布式系统的延迟和容错的开源库,在分布式系统里,
许多服务无法避免会调用失败,比如超时、异常等等,Hystrix能够保证在一个服务出现问题的情况下,
不会导致整体服务的失败,避免级联故障,以提高分布式系统的弹性。
所以叫“断路器”。“断路器”是一种开关装置,就好比我们家里的熔断保险丝,当出现突发情况,会自动跳闸,避免整个电路烧坏。
那么当某个服务发生故障时,通过 Hystrix,会向调用方返回一个符合预期的、可处理的默认响应(也称备选响应,即fallBack),
而不是长时间的等待或者直接返回一个异常信息。这样就能保证服务调用方可以顺利的处理逻辑,而不是那种漫长的等待或者其他故障。
这就叫“服务熔断”,就跟熔断保险丝一个道理。
服务熔断机制是应对雪崩效应的一种微服务链路保护机制。当扇出链路的某个微服务不可用或者响应时间太长,就会进行服务的降级,
快速熔断该节点微服务的调用,返回默认的响应信息。当检测到该节点微服务调用响应正常后即可恢复。
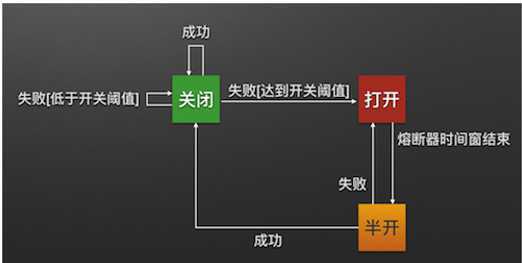
熔断器状态机有3个状态:
熔断器有三个状态 CLOSED、 OPEN、HALF_OPEN 熔断器默认关闭状态
当 Hystrix Command 请求后端服务失败数量超过一定阈值,断路器会切换到开路状态 (Open)。
这时所有请求会直接失败而不会发送到后端服务。
断路器保持在开路状态一段时间后 (默认 5 秒),自动切换到半开路状态 (HALF-OPEN)。
这时会判断下一次请求的返回情况,如果请求成功,断路器切回闭路状态 (CLOSED),否则重新切换到开路状态 (OPEN)。
快照时间窗:断路器确定是否打开需要统计一些请求和错误数据,而统计的时间范围就是快照时间窗,默认为最近的 10 秒。
请求总数下限:在快照时间窗内,必须满足请求总数下限才有资格进行熔断。默认为 20,意味着在 10 秒内,
如果该 Hystrix Command 的调用此时不足 20 次,即时所有的请求都超时或其他原因失败,断路器都不会打开。
错误百分比下限:当请求总数在快照时间窗内超过了下限,比如发生了 30 次调用,如果在这 30 次调用中,
有 16 次发生了超时异常,也就是超过 50% 的错误百分比,在默认设定 50% 下限情况下,这时候就会将断路器打开。
SpringCloud之服务容错保护(熔断器Hystrix)、雪崩效应
原文:https://www.cnblogs.com/64Byte/p/13283013.html