1.HashSet集合存储数据的结构(哈希表)
2.哈希表的健壮史:
* JDK1.8版本之前:哈希表=数组+链表
* JDK1.8版本之后:哈希表=数组+链表;
哈希表=数组+红黑树(提高查询的速度)
3.哈希表的特点:速度快
4.哈希表储存数据的过程:
首先在数组结构里:把元素进行了分组(相同的哈希值的元素是一组)
链表/红黑树结构把哈希值的元素连接到一起
(数组的初始容量是16)
存储数据到集合中,先计算元素的哈希值,并将哈希值放到数组当中,相同哈希值的
元素按照链表的格式连接起来在对应哈希值的位置,
如果链表长度超过了8位,那么就会把链表转换为红黑树(提高查询的速度)
5.哈希值:是一个十进制的整数,由系统随机给出(就像对象的地址值,是一个逻辑对峙,是模拟出来的地址,不是实际储存的物理地址)
* 在Object类有一个方法,可以获取对象的哈希值
int hashCode()
返回该对象的哈希码值。
* 源码:public native int hashCode()
(native:代表该方法调用的是本地操作系统的方法)


6.String类的哈希值
* String类重写Object类的hashCode方法

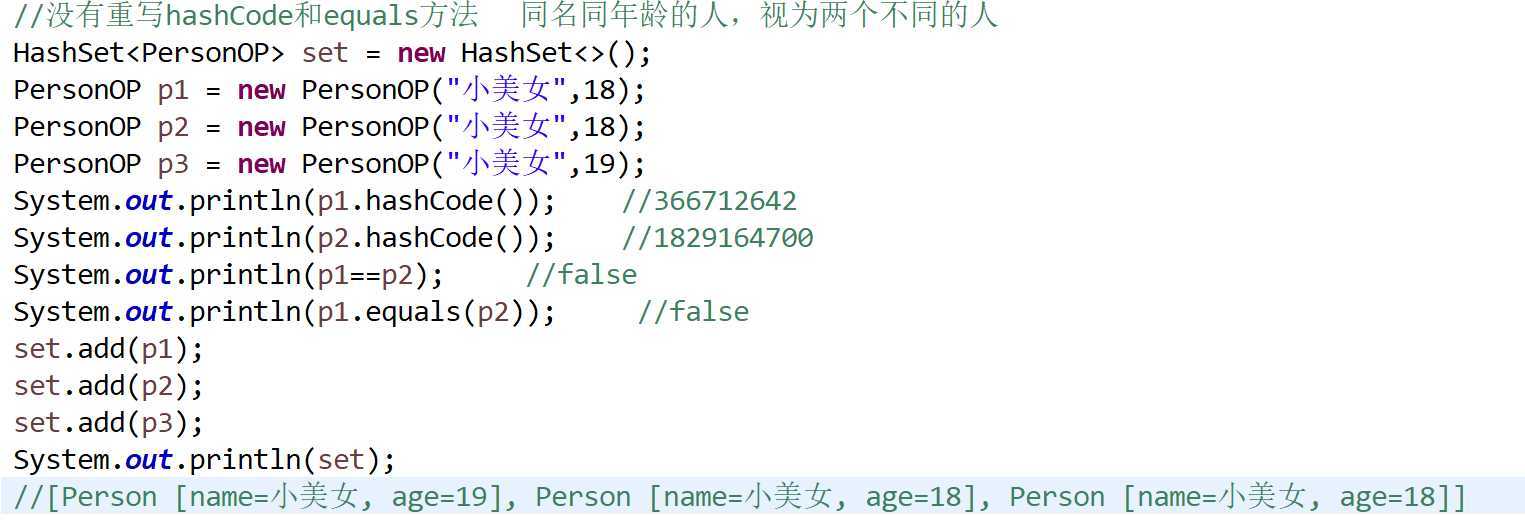
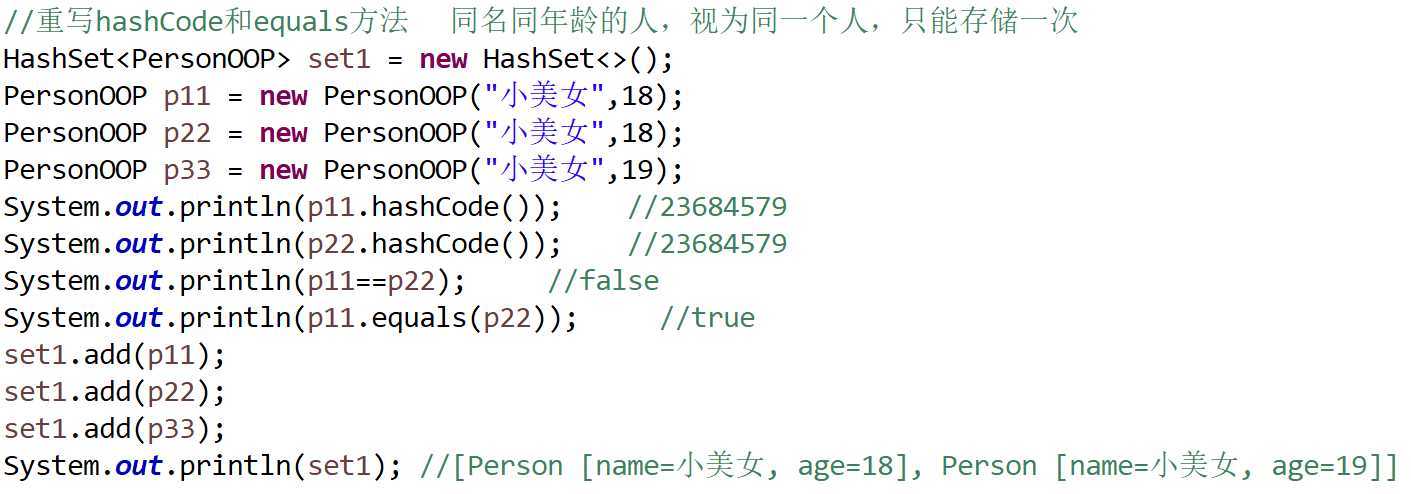
7. Set集合不允许存储重复元素的原理

* new HashSet<>();即在堆内存中开辟了哈希表,哈希表=数组+链表/红黑树
* Set集合在调用add方法的时候,add方法会调用元素的hashCode方法和equals方法判断元素是否重复
*
* set.add(s1);
* add方法会调用s1的hashCode方法,计算字符串“abc”的哈希值,哈希值是:96354
* 在集合中找有没有96354这个哈希值的元素,发现没有
* 就会把s1存储到集合中
*
* set.add(s2);
* add方法会调用s2的hashCode方法,计算字符串“abc”的哈希值,哈希值是:96354
* 在集合中找有没有96354这个哈希值的元素,发现有(哈希冲突)
* s2会调用equals这个哈希值相同的元素进行比较s2.equals(s1),返回true
* 两个元素的哈希值相同,equals方法返回true,认定两个元素相同
* 就不会把s2储存到集合中
*
* set.add("重地");
* add方法会调用“重地”s1的hashCode方法,计算字符串“重地”的哈希值,哈希值是:1179395
* 在集合中找有没有1179395这个哈希值的元素,发现没有
* 就会把“重地”存储到集合中
*
* set.add("通话");
* add方法会调用“通话”的hashCode方法,计算字符串“通话”的哈希值,哈希值是:1179395
* 在集合中找有没有1179395这个哈希值的元素,发现有(哈希冲突)
* “通话”会调用equals这个哈希值相同的元素进行比较"通话".equals("重地"),返回false
* 两个元素的哈希值相同,equals方法返回false,认定两个元素不同
* 就会把"通话"储存到集合中
*
* "通话"和"重地"挂在数组的同一位置上,提高数组的查询速度
*
* Set集合不允许存储重复元素的原理:
* 前提:存储的元素必须重写hashCode方法和equals方法,系统的类(默认重写) 自定义的类(自己重写)
原文:https://www.cnblogs.com/JIA1314JJ/p/13289442.html