Sqoop 是一款开源的工具,主要用于在 Hadoop(Hive) 与传统的数据库 (mysql,postgresql,...) 间进行数据的高校传递,可以将一个关系型数据库(例如:MySQL,Oracle,Postgres等)中的数据导入到 Hadoop 的 HDFS 中,也可以将 HDFS 的数据导进到关系型数据库中,底层是通过MapReduce程序实现。
1)下载地址:http://mirrors.hust.edu.cn/apache/sqoop/1.4.6/
2)上传安装包sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz到hadoop102的/opt/software路径中
3)解压sqoop安装包到指定目录,如:
[hadoop@hadoop102 software]$ tar -zxf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C /opt/module/
4)解压sqoop安装包到指定目录,如:
[hadoop@hadoop102 module]$ mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha/ sqoop
1)进入到/opt/module/sqoop/conf目录,重命名配置文件
[hadoop@hadoop102 conf]$ mv sqoop-env-template.sh sqoop-env.sh
2)修改配置文件
[hadoop@hadoop102 conf]$ vim sqoop-env.sh
增加如下内容
export HADOOP_COMMON_HOME=/opt/module/hadoop-3.1.3
export HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.3
export HIVE_HOME=/opt/module/hive
export ZOOKEEPER_HOME=/opt/module/zookeeper-3.5.7
export ZOOCFGDIR=/opt/module/zookeeper-3.5.7/conf
1)将mysql-connector-java-5.1.27-bin.jar 上传到/opt/software路径
2)进入到/opt/software/路径,拷贝jdbc驱动到sqoop的lib目录下。
[hadoop@hadoop102 software]$ cp mysql-connector-java-5.1.48.jar /opt/module/sqoop/lib/
通过bin/sqoop help命令验证
[hadoop@hadoop102 sqoop]$ bin/sqoop help
Warning: /opt/module/sqoop/bin/../../hbase does not exist! HBase imports will fail.
Please set $HBASE_HOME to the root of your HBase installation.
Warning: /opt/module/sqoop/bin/../../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /opt/module/sqoop/bin/../../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
2020-07-13 15:38:33,076 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6
usage: sqoop COMMAND [ARGS]
Available commands:
codegen Generate code to interact with database records
create-hive-table Import a table definition into Hive
eval Evaluate a SQL statement and display the results
export Export an HDFS directory to a database table
help List available commands
import Import a table from a database to HDFS
import-all-tables Import tables from a database to HDFS
import-mainframe Import datasets from a mainframe server to HDFS
job Work with saved jobs
list-databases List available databases on a server
list-tables List available tables in a database
merge Merge results of incremental imports
metastore Run a standalone Sqoop metastore
version Display version information
See ‘sqoop help COMMAND‘ for information on a specific command.
通过以下命令验证,查看mysql的库
[hadoop@hadoop102 sqoop]$ bin/sqoop list-databases --connect jdbc:mysql://hadoop102:3306/ --username root --password root
[hadoop@hadoop102 sqoop]$ bin/sqoop list-databases --connect jdbc:mysql://hadoop102:3306/ --username root --password root
Warning: /opt/module/sqoop/bin/../../hbase does not exist! HBase imports will fail.
Please set $HBASE_HOME to the root of your HBase installation.
Warning: /opt/module/sqoop/bin/../../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /opt/module/sqoop/bin/../../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
2020-07-13 15:39:51,939 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6
2020-07-13 15:39:51,977 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
2020-07-13 15:39:52,129 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
information_schema
gmail
mysql
performance_schema
sys
一般使用将mysql中的数据导入到hdfs或者hive中
--connect mysql数据库的url
--username mysql数据库的用户名
--password mysql数据库的密码
--append 向HDFS追加内容
--as-textfile 写入HDFS的时候文件格式是TEXT
--as-parquetfile 写入HDFS的时候文件格式是parquet
--delete-target-dir 在写入HDFS之前先删除存储路径
--fetch-size 每次从mysql取多少数据
-m[--num-mappers] 定义mapper的个数
-e[--query] "select * from table where age>20 and $CONDITIONS" 从mysql获取符合sql语句的数据 [不能与table\columns\wher共用]
--split-by 指定按照什么字段来进行切分
--table 指定从mysql那个表查询数据
--columns 从mysql查询哪些字段
--target-dir 数据存放到HDFS哪个路径
--where 从mysql查询数据的条件
-z[--compress] 数据写入HDFS的时候是否压缩
--compression-codec 压缩格式
--null-string 如果mysql字段类型为string的列的值为null,写到HDFS的时候写成什么
--null-non-string 如果mysql字段类型不为string的列的值为null,写到HDFS的时候写成什么
--check-column 指定根据哪个字段判断数据是否为新增/修改的数据
--incremental 指定模式[新增/修改]
--last-value 上次的导入的最后的结果值,根据该结果值判断数据是否为新增/修改数据
--fields-terminated-by 指定写入HDFS的时候列之间的分隔符
--lines-terminated-by 指定写入HDFS的时候行与行之间的分隔符
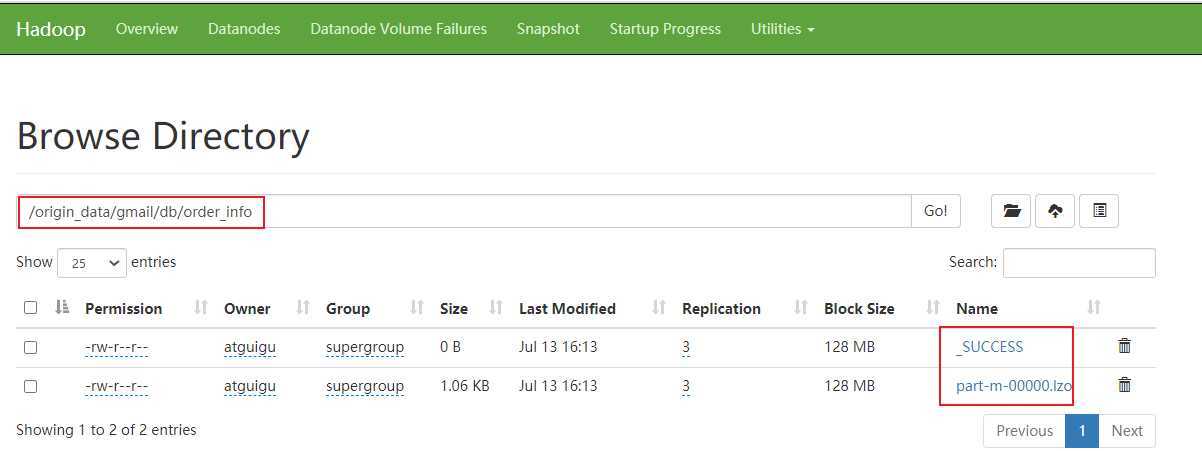
将mysql中的gmail库的order_info表的数据导入hdfs的/origin_data/gmail/db/order_info/目录下
bin/sqoop import --connect jdbc:mysql://hadoop102:3306/gmail --username root --password root --target-dir /origin_data/gmail/db/order_info/ --delete-target-dir --query "select id, final_total_amount, order_status, user_id, out_trade_no, create_time, operate_time,province_id,benefit_reduce_amount,original_total_amount,feight_fee from order_info where 1 =1 and \$CONDITIONS" --num-mappers 1 --fields-terminated-by ‘\t‘ --compress --compression-codec lzop --null-string ‘\\N‘ --null-non-string ‘\\N‘
--connect mysql数据库的url
--username mysql数据库的用户名
--password mysql数据库的密码
--hive-import 表示数据导入到hive
--hive-table 指定数据导入到hive哪个表
--create-hive-table 如果hive表不存在,则创建
--hive-overwrite 导入hive的时候如果数据存在则overwrite
--hive-partition-key 指定分区字段的字段名
--hive-partition-value 指定分区字段的字段值
一般使用数据从hive表导出到mysql中
--connect mysql数据库的url
--username mysql数据库的用户名
--password mysql数据库的密码
--columns 指定写往mysql表的哪些字段
-m mapper的个数
--table 写到Mysql哪个表
--update-key 指定按照哪个字段来进行更新
--update-mode updateonly[只更新]/allowinsert [如果update-key已经存在则更新,不存在则插入]
--input-null-string "null" 如果hive表的字段类型为string,其值为null的时候,写到mysql是什么形式
--input-null-non-string "null" 如果hive表的字段类型不为string,其值为null的时候,写到mysql是什么形式



某些特殊的维度表,可不必遵循上述同步策略。
1)客观世界维度
没变化的客观世界的维度(比如性别,地区,民族,政治成分,鞋子尺码)可以只存一份固定值。
2)日期维度
日期维度可以一次性导入一年或若干年的数据。
3)地区维度
省份表、地区表
需求详细说明
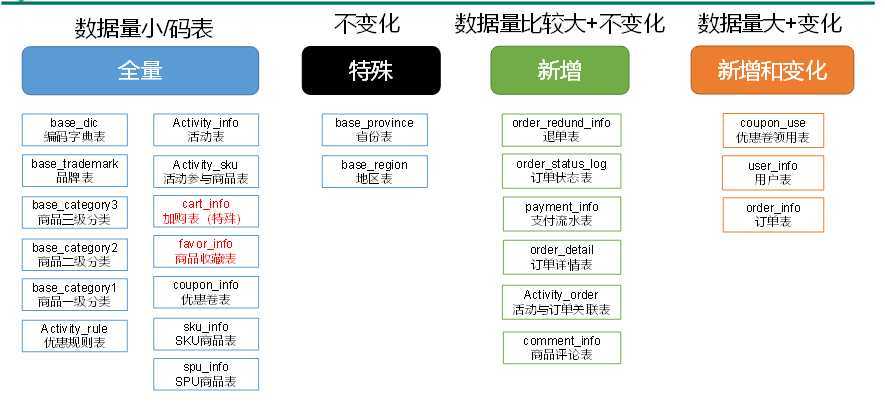
全量表:每天全量同步一次该表;
特殊表:从始至终只同步一次
新增和变化表:每天同步一次昨日创建的或昨日更新的。
脚本使用说明:
sqoop_mysql_to_hdfs.sh [first|all|表名] [日期-若不指定默认昨日]
sqoop_mysql_to_hdfs.sh first --第一次导入,导入所有表包括特殊表
sqoop_mysql_to_hdfs.sh all --每日导入昨日的数据,除了特殊表,所有表都导入一次
sqoop_mysql_to_hdfs.sh 表名 --指定具体导入的表名,单独导入
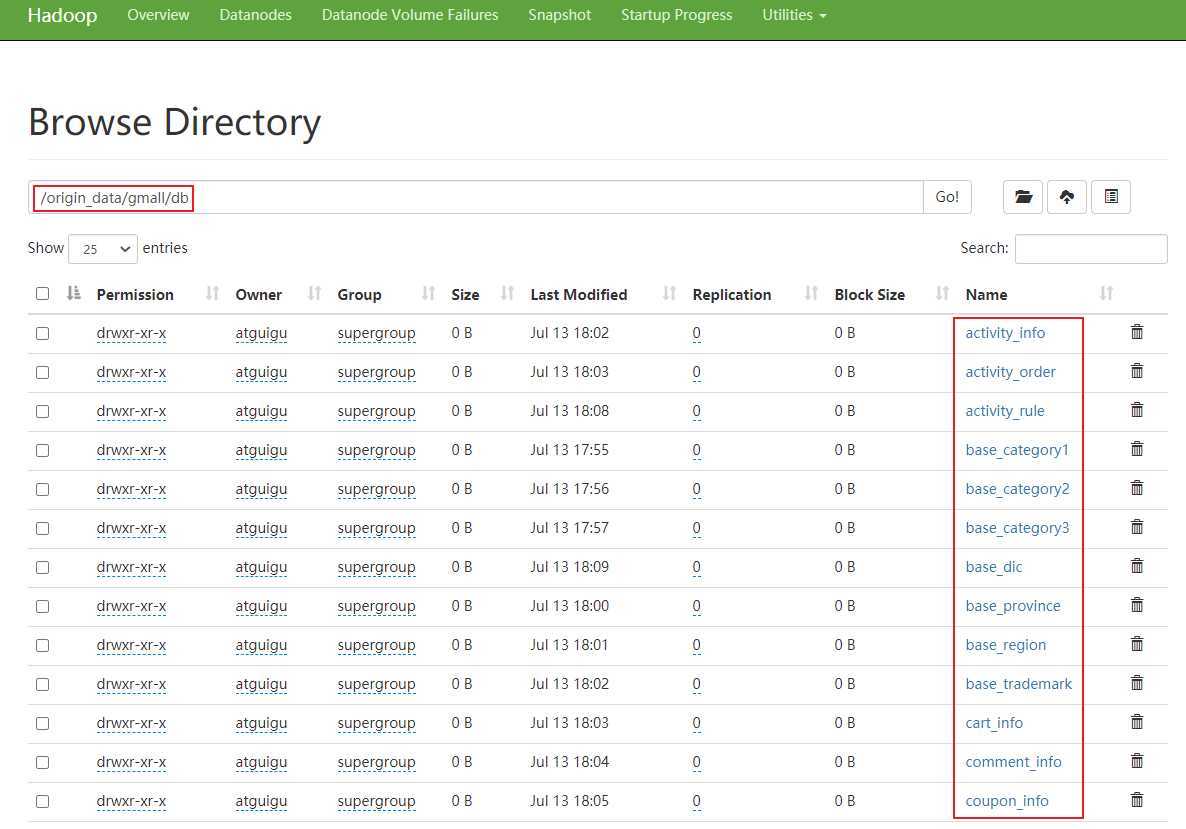
#! /bin/bash
sqoop=/opt/module/sqoop/bin/sqoop
#判断输入参数,第一个参数:first或all或具体表名 ,第二个参数:指定日期,若没有指定默认是昨日的数据。
if [ -n "$2" ] ;then
do_date=$2
else
do_date=`date -d ‘-1 day‘ +%F`
fi
#此方法为导入方法,需要2个参数:第1个指定表名,第2个指定查询条件
import_data(){
$sqoop import --connect jdbc:mysql://hadoop102:3306/gmall --username root --password root --target-dir /origin_data/gmall/db/$1/$do_date --delete-target-dir --query "$2 and \$CONDITIONS" --num-mappers 1 --fields-terminated-by ‘\t‘ --compress --compression-codec lzop --null-string ‘\\N‘ --null-non-string ‘\\N‘
#为导出的lzo压缩文件建立索引,后续该文件可分片
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer /origin_data/gmall/db/$1/$do_date
}
#具体表的导入
import_order_info(){
import_data order_info "select
id,
final_total_amount,
order_status,
user_id,
out_trade_no,
create_time,
operate_time,
province_id,
benefit_reduce_amount,
original_total_amount,
feight_fee
from order_info
where (date_format(create_time,‘%Y-%m-%d‘)=‘$do_date‘
or date_format(operate_time,‘%Y-%m-%d‘)=‘$do_date‘)"
}
import_coupon_use(){
import_data coupon_use "select
id,
coupon_id,
user_id,
order_id,
coupon_status,
get_time,
using_time,
used_time
from coupon_use
where (date_format(get_time,‘%Y-%m-%d‘)=‘$do_date‘
or date_format(using_time,‘%Y-%m-%d‘)=‘$do_date‘
or date_format(used_time,‘%Y-%m-%d‘)=‘$do_date‘)"
}
import_order_status_log(){
import_data order_status_log "select
id,
order_id,
order_status,
operate_time
from order_status_log
where date_format(operate_time,‘%Y-%m-%d‘)=‘$do_date‘"
}
import_activity_order(){
import_data activity_order "select
id,
activity_id,
order_id,
create_time
from activity_order
where date_format(create_time,‘%Y-%m-%d‘)=‘$do_date‘"
}
import_user_info(){
import_data "user_info" "select
id,
name,
birthday,
gender,
email,
user_level,
create_time,
operate_time
from user_info
where (DATE_FORMAT(create_time,‘%Y-%m-%d‘)=‘$do_date‘
or DATE_FORMAT(operate_time,‘%Y-%m-%d‘)=‘$do_date‘)"
}
import_order_detail(){
import_data order_detail "select
od.id,
order_id,
user_id,
sku_id,
sku_name,
order_price,
sku_num,
od.create_time,
source_type,
source_id
from order_detail od
join order_info oi
on od.order_id=oi.id
where DATE_FORMAT(od.create_time,‘%Y-%m-%d‘)=‘$do_date‘"
}
import_payment_info(){
import_data "payment_info" "select
id,
out_trade_no,
order_id,
user_id,
alipay_trade_no,
total_amount,
subject,
payment_type,
payment_time
from payment_info
where DATE_FORMAT(payment_time,‘%Y-%m-%d‘)=‘$do_date‘"
}
import_comment_info(){
import_data comment_info "select
id,
user_id,
sku_id,
spu_id,
order_id,
appraise,
comment_txt,
create_time
from comment_info
where date_format(create_time,‘%Y-%m-%d‘)=‘$do_date‘"
}
import_order_refund_info(){
import_data order_refund_info "select
id,
user_id,
order_id,
sku_id,
refund_type,
refund_num,
refund_amount,
refund_reason_type,
create_time
from order_refund_info
where date_format(create_time,‘%Y-%m-%d‘)=‘$do_date‘"
}
import_sku_info(){
import_data sku_info "select
id,
spu_id,
price,
sku_name,
sku_desc,
weight,
tm_id,
category3_id,
create_time
from sku_info where 1=1"
}
import_base_category1(){
import_data "base_category1" "select
id,
name
from base_category1 where 1=1"
}
import_base_category2(){
import_data "base_category2" "select
id,
name,
category1_id
from base_category2 where 1=1"
}
import_base_category3(){
import_data "base_category3" "select
id,
name,
category2_id
from base_category3 where 1=1"
}
import_base_province(){
import_data base_province "select
id,
name,
region_id,
area_code,
iso_code
from base_province
where 1=1"
}
import_base_region(){
import_data base_region "select
id,
region_name
from base_region
where 1=1"
}
import_base_trademark(){
import_data base_trademark "select
tm_id,
tm_name
from base_trademark
where 1=1"
}
import_spu_info(){
import_data spu_info "select
id,
spu_name,
category3_id,
tm_id
from spu_info
where 1=1"
}
import_favor_info(){
import_data favor_info "select
id,
user_id,
sku_id,
spu_id,
is_cancel,
create_time,
cancel_time
from favor_info
where 1=1"
}
import_cart_info(){
import_data cart_info "select
id,
user_id,
sku_id,
cart_price,
sku_num,
sku_name,
create_time,
operate_time,
is_ordered,
order_time,
source_type,
source_id
from cart_info
where 1=1"
}
import_coupon_info(){
import_data coupon_info "select
id,
coupon_name,
coupon_type,
condition_amount,
condition_num,
activity_id,
benefit_amount,
benefit_discount,
create_time,
range_type,
spu_id,
tm_id,
category3_id,
limit_num,
operate_time,
expire_time
from coupon_info
where 1=1"
}
import_activity_info(){
import_data activity_info "select
id,
activity_name,
activity_type,
start_time,
end_time,
create_time
from activity_info
where 1=1"
}
import_activity_rule(){
import_data activity_rule "select
id,
activity_id,
condition_amount,
condition_num,
benefit_amount,
benefit_discount,
benefit_level
from activity_rule
where 1=1"
}
import_base_dic(){
import_data base_dic "select
dic_code,
dic_name,
parent_code,
create_time,
operate_time
from base_dic
where 1=1"
}
#若有表一次性导入不成功,可以指定具体表名单独导入
case $1 in
"order_info")
import_order_info
;;
"base_category1")
import_base_category1
;;
"base_category2")
import_base_category2
;;
"base_category3")
import_base_category3
;;
"order_detail")
import_order_detail
;;
"sku_info")
import_sku_info
;;
"user_info")
import_user_info
;;
"payment_info")
import_payment_info
;;
"base_province")
import_base_province
;;
"base_region")
import_base_region
;;
"base_trademark")
import_base_trademark
;;
"activity_info")
import_activity_info
;;
"activity_order")
import_activity_order
;;
"cart_info")
import_cart_info
;;
"comment_info")
import_comment_info
;;
"coupon_info")
import_coupon_info
;;
"coupon_use")
import_coupon_use
;;
"favor_info")
import_favor_info
;;
"order_refund_info")
import_order_refund_info
;;
"order_status_log")
import_order_status_log
;;
"spu_info")
import_spu_info
;;
"activity_rule")
import_activity_rule
;;
"base_dic")
import_base_dic
;;
#第一次导入,要所有表导入一次
"first")
import_base_category1
import_base_category2
import_base_category3
import_order_info
import_order_detail
import_sku_info
import_user_info
import_payment_info
import_base_province
import_base_region
import_base_trademark
import_activity_info
import_activity_order
import_cart_info
import_comment_info
import_coupon_use
import_coupon_info
import_favor_info
import_order_refund_info
import_order_status_log
import_spu_info
import_activity_rule
import_base_dic
;;
#每日导入一次,除了第一次导入的特殊表外,(全量表和新增和同步表都要导入)
"all")
import_base_category1
import_base_category2
import_base_category3
import_order_info
import_order_detail
import_sku_info
import_user_info
import_payment_info
import_base_trademark
import_activity_info
import_activity_order
import_cart_info
import_comment_info
import_coupon_use
import_coupon_info
import_favor_info
import_order_refund_info
import_order_status_log
import_spu_info
import_activity_rule
import_base_dic
;;
esac
原文:https://www.cnblogs.com/wh984763176/p/13294944.html