type(None) NoneType
type(np.nan) float
为什么在数据分析中需要用到的是浮点类型的空而不是对象类型?
np.nan + 1 nan None + 1 --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-5-3fd8740bf8ab> in <module> ----> 1 None + 1 TypeError: unsupported operand type(s) for +: ‘NoneType‘ and ‘int‘
在pandas中如果遇到了None形式的空值则pandas会将其强转成NAN的形式。
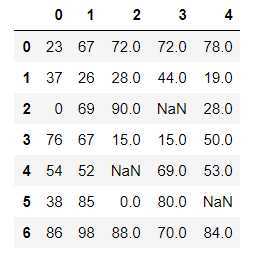
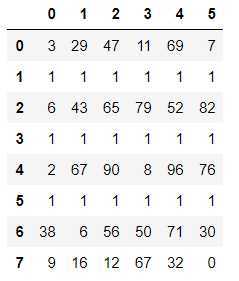
df = DataFrame(data=np.random.randint(0,100,size=(7,5))) df.iloc[2,3] = None df.iloc[4,2] = np.nan df.iloc[5,4] = None df
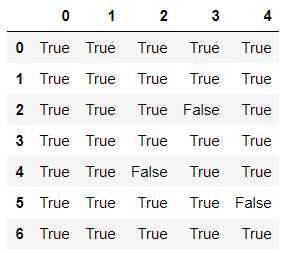
df.isnull()
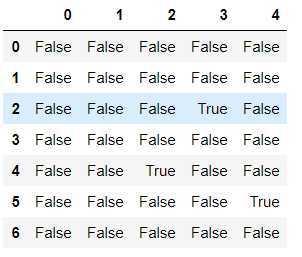
#哪些行中有空值 #any(axis=1)检测哪些行中存有空值 df.isnull().any(axis=1) #any会作用isnull返回结果的每一行 #true对应的行就是存有缺失数据的行
df.notnull()
df.notnull().all(axis=1)

#将布尔值作为源数据的行索引
df.loc[df.notnull().all(axis=1)] #取出不含空的行
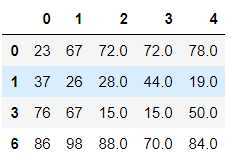
#获取空对应的行数据
df.loc[df.isnull().any(axis=1)]
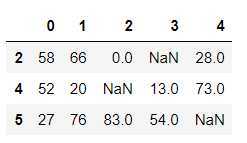
df.loc[-df.isnull().any(axis=1)] #前面取反 也可以取出非空行
#获取空对应行数据的行索引
indexs = df.loc[df.isnull().any(axis=1)].index
indexs
df.drop(labels=indexs,axis=0) #将空行删除 drop系列 axis 相反 0表示行
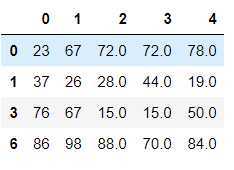
方式2:
df.dropna(axis=0) #可以直接将缺失的行或者列进行删除
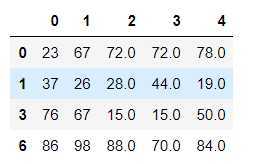
对缺失值进行覆盖
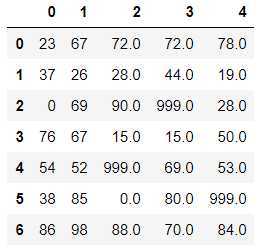
df.fillna(value=999) #使用指定值将源数据中所有的空值进行填充
# 使用上面的自定义任意值 填充 可能会对我们后面的分析有偏导,这里如果不能填充有意义的值建议使用下面的 #使用空的近邻值进行填充 相对来说有意义 #method=ffill向前填充,bfill向后填充 ffill----> f forward 向前 bfill -----> b backward 向后 df.fillna(axis=0,method=‘bfill‘)
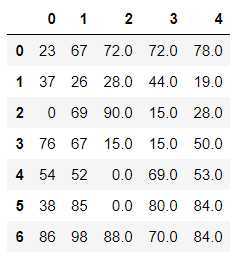
df
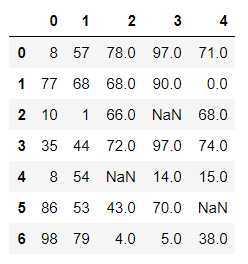
for col in df.columns: #检测哪些列中存有空值 if df[col].isnull().sum() > 0:#说明df[col]中存有空值 isnull如果没有空值 全是False 那么再.sum就是0 False 0 True 1 mean_value = df[col].mean() df[col] = df[col].fillna(value=mean_value)
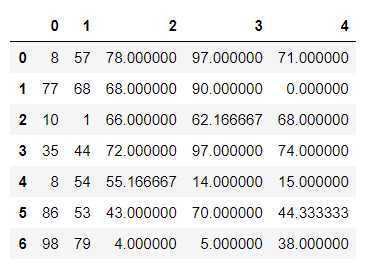
数据说明:
数据处理目标:
数据处理过程:
无标准答案,按个人理解操作即可,请把自己的操作过程以文字形式简单描述一下,谢谢配合。
测试数据为testData.xlsx
data = pd.read_excel(‘./data/testData.xlsx‘).drop(labels=[‘none‘,‘none1‘],axis=1) #删除none 和 none1两列 无用数据 data
data.shape #删除空行前数据形状
(1060, 8)
#删除空对应的行数据
data.dropna(axis=0).shape #删除后数据形状 空行并不多可以直接删除
(927, 8)
#填充
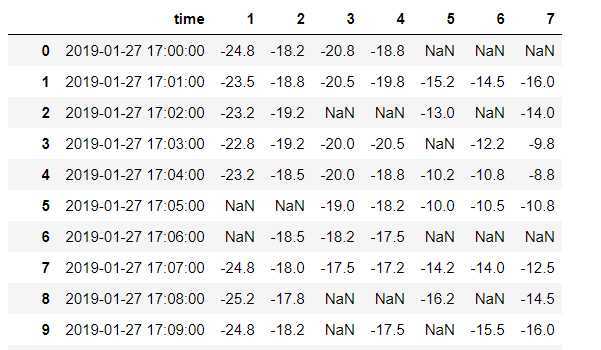
data.fillna(method=‘ffill‘,axis=0).fillna(method=‘bfill‘,axis=0) #用列向上填充 因为是一个机器的数据 偏差应该不会太大 因为有可能第一行或者最后一行有空值 填充不到 向前填充一次再向后填充一次百分之一万没有空值了
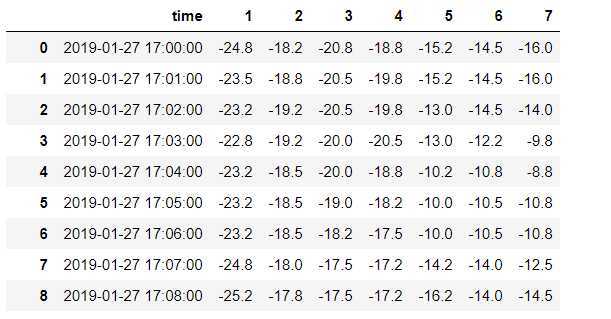
df = DataFrame(data=np.random.randint(0,100,size=(8,6))) df.iloc[1] = [1,1,1,1,1,1] df.iloc[3] = [1,1,1,1,1,1] df.iloc[5] = [1,1,1,1,1,1] df
#检测哪些行存有重复的数据
df.duplicated(keep=‘first‘) # 保留第一行值 以第一行为参照模板

df.loc[~df.duplicated(keep=‘first‘)]
#一步到位删除
df.drop_duplicates(keep=‘first‘)
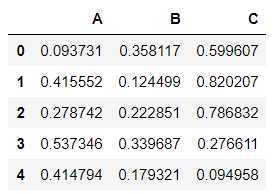
df = DataFrame(data=np.random.random(size=(1000,3)),columns=[‘A‘,‘B‘,‘C‘]) df.head()
#制定判定异常值的条件
twice_std = df[‘C‘].std() * 2
twice_std
0.5664309886908782
df.loc[~(df[‘C‘] > twice_std)]
原文:https://www.cnblogs.com/linranran/p/13301485.html