深度学习其实就是有更多隐层的神经网络,可以学习到更复杂的特征。得益于数据量的急剧增多和计算能力的提升,神经网络重新得到了人们的关注。
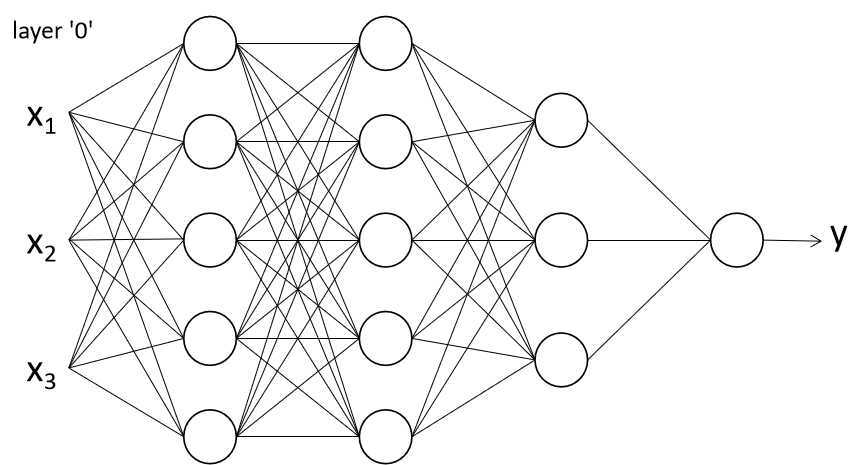

为什么神经网络需要激活函数呢?如果没有激活函数,可以推导出神经网络的输出y是关于输入x的线性组合,那么神经网络的隐层就没有任何意义,对于这样的模型,直接使用线性回归拟合就可以了。
一些常见的激活函数如下所示:
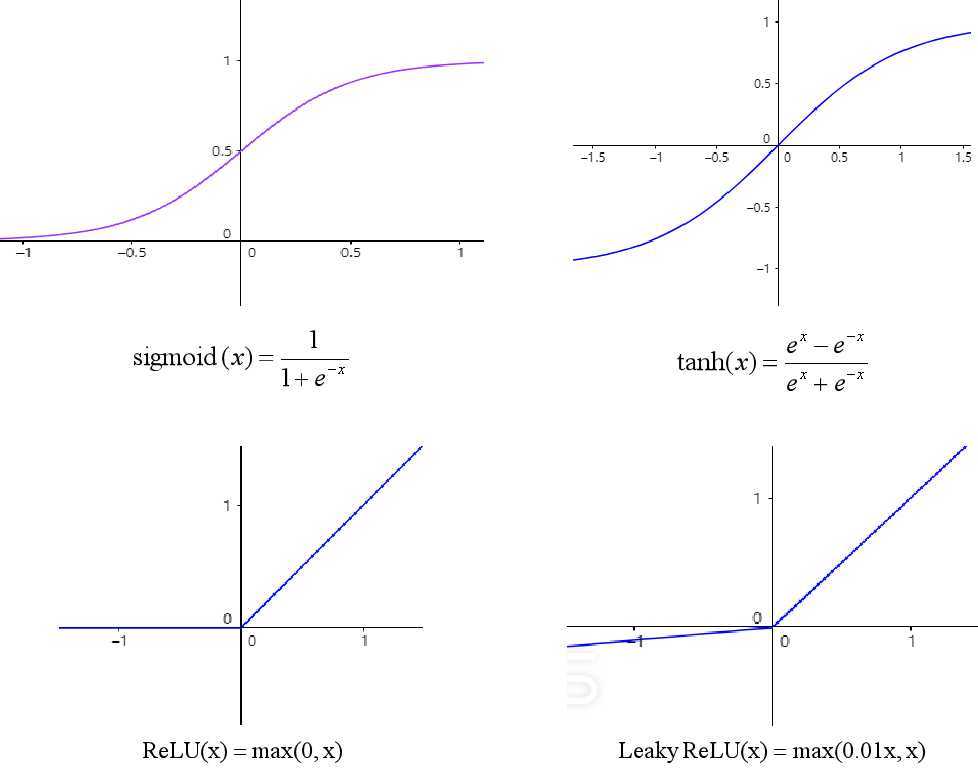
在上一篇文章中推导了BP算法,其中使用了Sigmoid函数作为激活函数,具有良好的连续性和可导性。
使用tanh函数时,神经网络中的参数能得到标准化,所有的数据会聚集在0附近,更有利于收敛。
而上面两个函数在x较大或较小时,其导数接近于0,在使用梯度下降法时会导致收敛速度慢,因此,又提出了ReLU函数。
Leaky ReLU函数是对ReLU的改良,使x为负数时导数不为0,该函数使用较少。
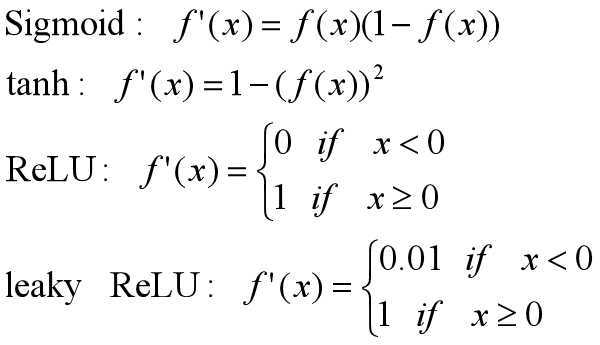
在神经网络中,每一层可以使用不同的激活函数,例如隐层使用ReLU函数,输出层使用sigmoid函数。
逻辑回归模型可以帮助我们更好地理解神经网络。
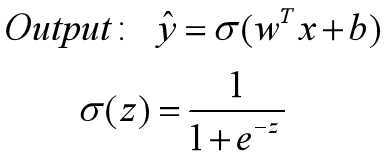
接下来需要定义损失函数(Loss function),假设有m个样本,在线性回归方程中,我们定义的损失函数是所有模型误差的平方和。理论上,也可以对逻辑回归模型沿用这个定义,但问题是这样的损失函数会是非凸的:
![]()
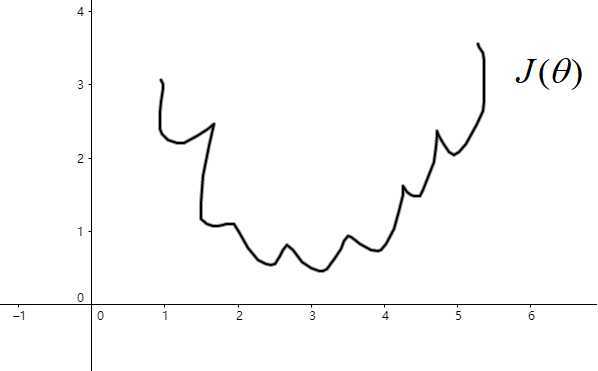
此时,损失函数里有许多局部极小值,这将影响梯度下降法寻找全局最小值。我们重新定义逻辑回归的损失函数为:
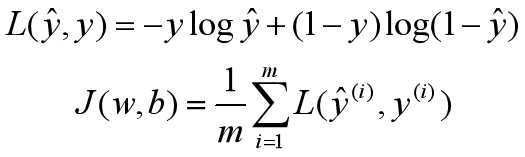
我们需要最小化损失函数。
逻辑回归中的梯度下降:
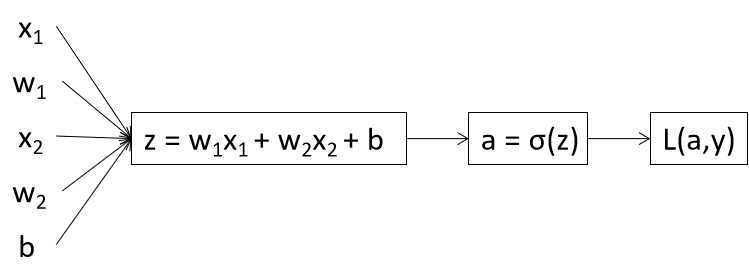
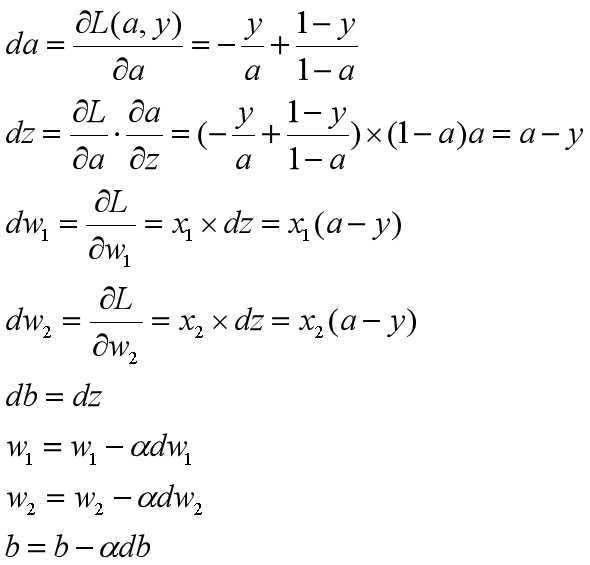
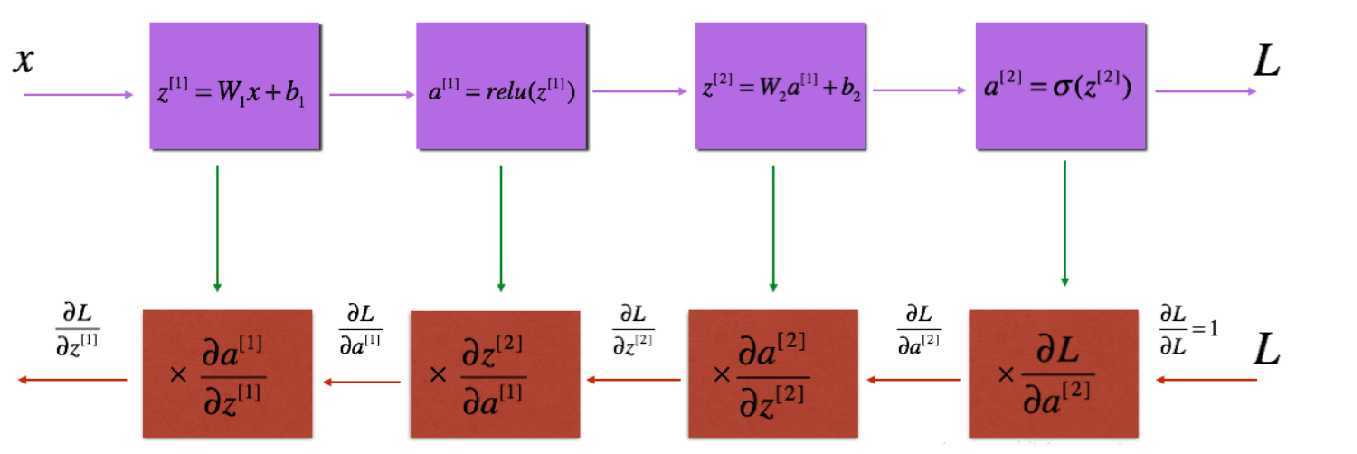

程序编写过程中需要特别注意各矩阵维度定义。

超参数的选择会直接影响到参数的训练结果。
以上内容主要参考吴恩达《深度学习》课程第一课
神经网络和深度学习 (Neural Network & Deep Learning)
原文:https://www.cnblogs.com/sun-a/p/13298941.html